Advanced Python Types
1. List
Lists are mutable.
1 | amazon_cart = [ |
1.1 常见操作
1 | >>>x = [1,2,3,4,5,6] |
1.2 append() 与 extend() 方法的区别
1.append() 方法用于在列表末尾添加新的对象。语法:
1 | list1.append(obj) # 向列表中添加一个对象object |
该方法无返回值,直接修改原列表。
使用append()
的时候,是将obj看作一个对象,整体打包添加到list1对象中。
例:
1 | list1 = [1,2,3] |
2.extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。语法:
1 | list1.extend(iterable) # 把iterable的内容添加到列表中(什么是iterable: something that you can loop over, 例如list) |
该方法没有返回值,直接修改原列表。
extend()方法接受一个序列作为参数,并将该序列的每个元素都添加到原有的列表中。
例:
1 | list1 = [1,2,3] |
1 | t1 = (5, 15, 25, 50) |
1.3 给List添加元素
1.往后添加元素append
1 | arr = [1,2] |
2.往前添加元素,或在指定位置添加元素 insert
1 | arr = [] |
1.4 List的拼接
方法一:使用 “+”
1 | arr1 = [1,2] |
方法二:使用extend()
1 | arr1 = [1,2] |
1.5 排序
法一:sort() - 会改变原列表,无返回值
1 | x = [3,2,1] |
法二:sorted() - 不会改变原列表,返回一个新的列表
1 | x = [3, 4, 1] |
更多关于sort的内容见 Python中的reverse, reversed, sort, sorted
1.6 列表 count() 方法
count() 方法返回具有指定值的元素数量。语法:
1 | list.count(value) |
例:
1 | points = [1, 4, 2, 9, 7, 8, 9, 3, 1] |
1.7 all() 方法
all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。元素除了是 0、空、None、False 外都算 True。语法:
1 | all(iterable) |
iterable -- 元组或列表。
例: Define a list with elements 11, 25, 43, 68, 76 and 94. Write code that confirms the list of numbers are over 10.
1 | numbers = [11, 25, 43, 68, 76 , 94] |
1.8 创建一个0-99的数列
1 | L = list(range(100)) |
1.9 列表生成式 List Comprehension
参考 https://www.liaoxuefeng.com/wiki/1016959663602400/1017317609699776
A quick way for us to generate list.
关于列表生成式中的 if ... else 的用法:
例:输出偶数 只需要 if 时的正确写法:
1 | [x for x in range(1,11) if x%2 == 0] |
但是,不能在最后的 if 加上 else:
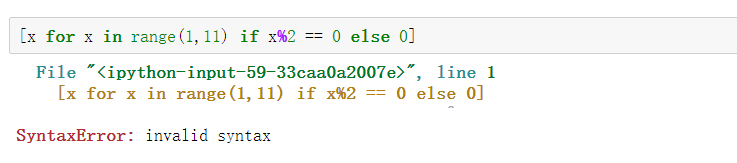
这是因为跟在 for 后面的 if
是一个筛选条件,不能带 else,否则如何筛选?
而如果把 if 写在 for 前面,必须加
else,否则报错:
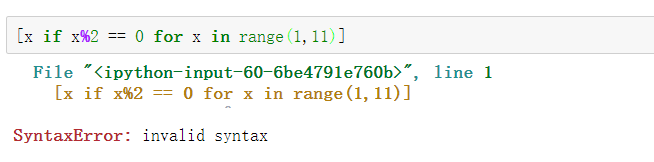
这是因为 for 前面的部分是一个表达式,它必须根据
x 计算出一个结果。因此,考察表达式:
x if x%2 == 0,它无法根据 x
计算出结果,因为缺少 x,必须加上 else: 需要 if ... else 时的正确写法:
1 | [x if x%2 == 0 else -x for x in range(1,11)] |
上述 for 前面的表达式 x if x%2 == 0 else -x
才能根据 x 计算出确定的结果。
总结:在列表生成式中,
for前面的内容是表达式,也就是对我们 iterate over 的对象要做什么操作,如果要用if,则if ... else要成对使用,而for后面的if是过滤条件(也即对满足条件的对象才放进list中),不能带else.
此外,set, dictionary 也能进行类似操作(set comprehension, dictionary comprehension)
1 | # set comprehension,和list comprehension很像,只是[]换成了{} |
1.10 从列表中移除元素
方法一:pop()
1 | basket = [1,2,3,4,5] |
方法二:remove(value) - remove the first occurrence of value
1 | basket = [1,2,3,4,3,5] |
pop与remove的区别:
1、pop是移除指定index的元素,remove是移除指定的value (first occurence)
2、remove没有返回值,pop会返回移除的那个元素
清空列表:
1 | basket = [1,2,3,4,5] |
1.11 移除列表中的重复元素
方法一:不需要保持原来的顺序时,可使用 set()
使用 set() 方法,返回的是一个集合,可使用 list() 或 tuple() 转化回 list 或 tuple。
1 | l = [3, 3, 2, 1, 5, 1, 4, 2, 3] |
方法二:需要保持原来的顺序时,可使用 dict.fromkeys()
(Python3.7) 或 sorted()
dict.fromkeys()
使用可迭代对象中的键创建一个新字典,当第二个参数省略时,默认值为
None。因为字典键不能有重复的元素,重复的值会被忽略,就像 set()
一样。将字典传递给 list() 将返回一个以字典键为元素的列表。
1 | l = [3, 3, 2, 1, 5, 1, 4, 2, 3] |
从python3.7开始,dict.fromkeys()
保证序列的顺序会被保留。在更早的版本中,可使用 sorted()
1 | print(sorted(set(l), key=l.index)) |
index() 方法返回一个值的索引。通过将其指定为 sorted() 中的
key 参数,可以根据原始列表的顺序对列表进行排序。
1.12 从列表中提取重复元素
方法一:使用 Counter()
使用 collections.Counter()返回
collections.Counter(字典子类),其键是一个元素,其值是它的计数。
1 | import collections |
由于它是字典的子类,因此可以使用 items() 检索键和值。可以通过列表生成式提取具有两个以上计数的键:
1 | print([k for k, v in collections.Counter(li).items() if v > 1]) |
注:从Python 3.7开始,collections.Counter
的键保留原始列表的顺序。在更早的版本中,如果需要保持原来的顺序时,可使用
sorted():
1 | li = [3, 3, 2, 1, 5, 1, 4, 2, 3] |
如果希望提取 elements in their duplicated state, 只需包含原始列表中出现两次或两次以上的元素。顺序也会被保留下来:
1 | counter = collections.Counter(li) |
方法二: 自己构造一个counter
1 | some_list = [3, 3, 2, 1, 5, 1, 4, 2, 3] |
方法三:利用list的count()方法
1 | some_list = [3, 3, 2, 1, 5, 1, 4, 2, 3] |
方法四:结合set()使用(缺点:不能保持原顺序)
1 | some_list = [3, 3, 2, 1, 5, 1, 4, 2, 3] |
1.13 List Unpacking
1 | a,b,c=[1,2,3] |
2. Tuple
Tuple很像List,只是tuple是immutable的。
1 | >>>my_tuple=(1,2,3,4,5) |
向tuple添加元素: 注:由于元组是不可变的,您不能直接向元素例添加元素,但可以将元组连接在一起
1 | primes = (2, 3, 5, 7, 11, 13, 17, 19, 23) |
元组可以使用切片:
1 | primes[1] |
1 | x,y,z,*other = (1,2,3,4,5) |
tuple只有两个built-in methods: count(), index()
1 | my_tuple=(1,2,3,4,5,5) |
另:有了list为什么还需要tuple
tuple的优点:
1、immutable. Makes things easier. It tells other programmers, hey ,this shouldn't be changed.
2、More efficient. They are usually faster that lists.
3、可以当作字典的key(字典的key必须是immutable的,list不能作为key)
If you don't need a list to change, use a tuple.
3. Dictionary
注:3.6版本后Python的dict就是有序的了,顺序就是插入的顺序。
在Python3.6及之后的版本中,字典变得更加智能,使用了一种称为“保留插入顺序”的技术来存储键值对。这种技术确保在字典中添加新键时,它们被添加到最后,并且在迭代字典时按照它们在字典中添加的顺序返回。这也就意味着,在Python3.6及之后的版本中,字典的迭代顺序是可以预测的。
In other languages, you might know this as a map, or a hash table. It's basically a lookup table, where you store values associated with some unique set of key values.
字典是一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
1 | d = {key1 : value1, key2 : value2 } |
一个简单的字典实例:
1 | d = {'foo':1, 'bar':2.3, 's':'my first dictionary'} |
键一般是唯一的,如果重复,最后的一个键值对会替换前面的,值不需要唯一。
1 | dict1 = {'a': 1, 'b': 2, 'b': '3'} |
值可以取任何数据类型(字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的),但键必须是不可变的,如字符串,数字或元组(列表不行)。如:
1 | dict1 = {['Name']: 'Zara', 'Age': 7} |
3.1 访问字典里的值
把相应的键放入方括弧

如果访问字典中没有的key,会报错:
1 | captains['NX-01'] |
避免报错的一个方法是使用 get .
get是Python字典内置方法。dict.get(key,
default=None) 返回指定键的值,如果值不在字典中返回default值

get还可指定不存在时的默认返回值,如
1 | print(captains.get("NX-01",0)) |
3.2 修改字典
1 | >>>dict1 = {'Name': 'Zara', 'Age': 7, 'Class': 'First'} |
3.3 删除字典元素
pop(key[,default]) - 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
popitem() - 返回并删除字典中的最后一对键和值。
1 | >>>dict1 = {'Name': 'Zara', 'Age': 7, 'Class': 'First'} |
3.4 遍历字典: keys() 、values() 、items()
Iterate:
- xxx.keys() : 返回字典的所有的key. 返回一个序列,序列中保存有字典的所有的键
例:

- xxx.values() : 返回字典所有的值.
例:

- xxx.items() : 返回字典中所有的key和values. 返回一个序列,序列中包含所有双值子序列
例:

3.5
Python中的defaultdict
dict subclass that calls a factory function to supply missing values.
1 | import collections |
defaultdict(int) 创建一个类似 dictionary 对象,里面任何的 values 都是 int 的实例,而且就算是一个不存在的 key, d[key] 也有一个默认值,这个默认值是 int() 的默认值0.
3.6 按照字典的键或者值排序
参考 https://blog.csdn.net/leokingszx/article/details/81154681
1 | y = {1:3, 2:2, 3:1} |
当然,在这样处理后,得到的结果将变成元组。这样也可以理解,毕竟对于字典而言,本身是不提供排序的需求的。如果想按照里面的元素进行排列,那么将不得不对其类型进行转化。
另:Python中多条件排序:
1 | #!/usr/bin/python |
3.7 其他一些字典内置函数&方法
len(my_dict) 计算字典元素个数,即键的总数。
my_dict.copy() 返回一个字典的浅拷贝
3.8 两个列表合并成一个字典
两个列表合并成一个字典,一个列表里的值为 key,一个列表里的为 Value
1 | a = [1,2,3,4] |
补充1:关于zip()函数:https://www.runoob.com/python/python-func-zip.html
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表(python2中返回的是列表,python3中返回的是对象)。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
1 | zip([iterable, ...]) |
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 2.x zip() 返回的是一个元组列表, Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换。。
1 | # Python3 |
补充2:字典还可以这样定义:
1 | dict([(1,2),(3,4)]) |
3.9 合并两个字典
Combine below dictionaries in order to add values for common
keys:
dict1 = {'alpha': 50,'beta': 200, 'gamma':300}
dict2 = {'alpha': 300, 'b': 200, 'beta': 120, 'delta':400}
Expected output:
{'alpha': 350, 'beta': 320, 'gamma': 300, 'b': 200, 'delta': 400}.
法一:
1 | dict1 = {'alpha': 50,'beta': 200, 'gamma':300} |
法二:
1 | dict1 = {'alpha': 50,'beta': 200, 'gamma':300} |
法三:
1 | from collections import Counter |
4. String
String is immutable. You can’t reassign part of a string.
1 | test_str = '123456' |
4.1 endswith()
Define a list called files which contains some file
names:
files = ['1.txt', '2.txt', '2.ab', '2.c', '3.txt', '3.ann', '3.ss'].
Delete the file name which doesn't use the extension .txt
from the list. Print the list, the expected output is:
['1.txt', '2.txt', '3.txt']
法一:
1 | files = ['1.txt', '2.txt', '2.ab', '2.c', '3.txt', '3.ann', '3.ss'] |
法二:
1 | files = ['1.txt', '2.txt', '2.ab', '2.c', '3.txt', '3.ann', '3.ss',] |
类似的函数还有 startswith()
4.2 strip()
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
例:
1 | cities = [' London', ' Birmingham ', ' Manchester', ' Glasgow', ' Newcastle', 'Sheffield '] |
1 | str1 = "00000003210Runoob01230000000"; |
例: Define a string:
idx_str = 'use, index,numbers ,to , specify ,positions'.
生成如下字典idx_dict:{0: 'use', 1: 'index', 2: 'numbers', 3: 'to', 4: 'specify', 5: 'positions'}
法一:
1 | idx_str = 'use, index,numbers ,to , specify ,positions' |
法二:
1 | idx_str = 'use, index,numbers ,to , specify ,positions' |
4.3 大小写
- s.lower():全部转换为小写
- s.upper():全部转换为大写
- s.title():每个单词的首字母大写,其余小写
- s.capitalize():第一个单词的首字母大写,其余小写
- s.islower():判断是否全为小写
- s.isupper():判断是否全为大写
- s.istitle():判断是否每个单词的首字母均大写,其余均小写
例:
1 | s = "hello WorlD" |
4.4 判断是否为数字、字母
- s.isdigit():判断是否全为数字(若s为空,返回False)
- s.isalpha():判断是否全为字母(若s为空,返回False)
- s.isalnum():判断是否全为字母数字(若s为空,返回False)
注:Python官方定义中的字母:可默认为英文字母+汉字;Python官方定义中的数字:可默认为阿拉伯数字+带圈的数字(如①)
4.5 替换strings
参考 https://note.nkmk.me/en/python-str-replace-translate-re-sub/
在Python中,有许多替换strings的方法,可以使用
replace()进行简单的替换,使用 translate() 进行
character-to-character 的替换,以及正则表达式方法 re.sub()
和 re.subn() 进行复杂的 patter-based 替换。另外,slicing
可用来替换指定位置的子字符串。
4.5.1 Replace substrings:
replace()
1 | s = 'one two one two one' |
指定替换的最大计数:指定第三个参数 count
1 | s = 'one two one two one' |
替换多个不同的字符串:
如果要用相同的字符串替换多个不同的字符串,可以使用接下来会描述的正则表达式方法,如果要用不同的字符串替换多个不同的字符串,需要重复使用
replace():
1 | s = 'one two one two one' |
第一次replace的结果,传入第二个replace。
4.5.2 Replace
multiple different characters: translate()
使用 translate() 方法替换多个不同的字符。通过使用
str.maketrans() 来创建 translate()
中指定的翻译表:
1 | s = 'one two one two one' |
4.5.3 Replace by regex:
re.sub(), re.subn()
如果想替换匹配正则表达式(regex)而不是精确匹配的字符串,可以使用re模块的sub()。
在re.sub()中,在第一个参数中指定regex pattern,在第二个参数中指定新字符串,在第三个参数中指定要处理的字符串。
1 | import re |
和 replace() 一样,可以在第四个参数
count中指定替换的最大计数:
1 | print(re.sub('[a-z]+@', 'ABC@', s, 2)) |
还可以使用 re.compile()创建正则表达式模式对象并调用
sub()方法。当需要重复使用相同的正则表达式模式时,这种方法更有效:
1 | p = re.compile('[a-z]+@') |
用相同的字符串替换多个子字符串:(将字符串用 []
括起来以匹配其中的任何单个字符)
1 | s = 'aaa@xxx.com bbb@yyy.net ccc@zzz.org' |
If patterns are delimited by |, it matches any pattern:
1 | print(re.sub('com|net|org', 'biz', s)) |
Replace using the matched part:使用匹配到的部分进行替换
如果pattern中有被
()括起来的部分,替换时可以通过\1、\2等来指代
() 括起来的部分:
1 | s = 'aaa@xxx.com bbb@yyy.net ccc@zzz.org' |
↑ 在引号(单引号或双引号)中,'\1'
需要用反斜杠进行转义:\\1;也可通过在引号前加
r(r'' 或 r"")将字符串变为 raw
string后,可直接写作 \1。(因为 \1
是特殊转义字符(Python中 print('\1')会输出☺),需使用双反斜杠或者
r'' 来使其代表字面意义上的 \1)
4.5.4 Replace by position: slice
1 | s = 'abcdefghij' |
4.6 find()
存不存在,如果存在返回第一次出现时所在的index
1 | quote = 'to be or not to be' |
5. Set
Sets are simply unordered collections of unique object.
1 | my_set = {1,2,3,4,5,5} |
5.1 向集合中添加元素
1 | my_set={1,2,3,4,5} |
1 | fruits = {"apple", "banana", "cherry"} |
5.2 移除元素
1 | # discard |
5.3 集合的方法
- .difference()
1 | my_set={1,2,3,4,5} |
- .difference_update(): remove all elements of another set from this set.
1 | my_set={1,2,3,4,5} |
- .intersection() - 交集
1 | my_set={1,2,3,4,5} |
- .union() - 并集
1 | my_set={1,2,3,4,5} |
- .isdisjoint() - 是否有共同元素,如果没有则返回True,否则返回False
1 | my_set={1,2,3,4,5} |
- .issubset() - 是否是子集; .issuperset() - 是否是超集
1 | my_set={4,5} |
6. Array
1 | import numpy as np |
1 | array_2 = np.array([[[1,1,1],[2,2,2]],[[3,3,3],[4,4,4]],[[5,5,5],[6,6,6]],[[7,7,7],[8,8,8]]]) |
np.arange():
1 | array_3 = np.arange(1,20,2) |
cumsum:
1 | a = np.array([1,3,5,7,9,11,13,15,17,19,21]) |
Create an array by using
array_4 = np.array([[7,-1],[10,2],[-3,4]]).Print the
elements of the array which are larger than 0.
1 | array_4 = np.array([[7,-1],[10,2],[-3,4]]) |
Replace the odd numbers in array_4 with zeros.
1 | array_4[array_4%2==1] = 0 |
6.1 Array的合并
1 | np.concatenate(要拼接的多个数组, axis = 0) |
例:
1 | arr1 = np.array([1,2]) |
6.2 矩阵
单位矩阵:np.identity(), np.eye()
1 | 法一: |
区别:np.identity() 返回的是行数和列数相等的 square array,np.eye() 行数和列数可以不同,例:
1 | print(np.eye(3,2)) |
全为1的矩阵:np.ones()
1 | my_array = np.ones([5,5]) #也可以用(5,5) |
全为0的矩阵:np.zeros()
1 | array = np.zeros((12,12)) |
空矩阵:np.empty(). Return a new array of given shape and type, without initializing entries.
1 | arr = np.empty((4,4)) |
Write a code that reindexes the array arr_new so that it
looks like the below array:
1 | [[0., 0.], |
1 | arr_new[np.ix_([0, 2, 4, 6, 7, 5, 3, 1], [0,1])] |
Using ix_ one can quickly construct index arrays that
will index the cross product. a[np.ix_([1,3],[2,5])]
returns the array [[a[1,2] a[1,5]], [a[3,2] a[3,5]]].
上三角矩阵与下三角矩阵
Use one line of numpy code to create
and print the below array:
1 | [[0. 0. 0. 0.] |
1 | (np.triu(np.ones((4, 4)), 1)).T |
np.triu(): 上三角矩阵(主对角线以下都是零的方阵) np.tril(): 下三角矩阵(主对角线以上都是零的方阵)
随机矩阵
1 | X = np.random.randn(6, 3) # Return a sample (or samples) from the "standard normal" distribution. |
Define an array called data using the following code:
data = np.array([[10,2,3],[1,3,3],[2,34,4],[5,4,3]]) For
each row in the array, apply the following formula: \(x_1×2+x_2×5+x_3×3\) For instance, if you
apply the formula to the first row, you will get $39 (10×2+2×5+3×3).
$Print the new array after applying the formula to each row. The
expected output is: [ 39 26 186 39]
1 | data = np.array([[10,2,3],[1,3,3],[2,34,4],[5,4,3]]) |
Print an array of shape 4X4, with the first value of 1000 and next values being 25% larger than the previous one. It should look like this:
1 | [[ 1000. 1250. 1562.5 1953.125 ] |
1 | print(1000*(1.25**np.arange(16)).reshape(4,4)) |
6.3 Array中的nan
1 | np.isnan(arr).sum() |
7. python的数据类型的有序无序&可变不可变
- 列表list有序可变
- 字典dict在python3.6之前是无序的,到了python3.7变成了有序,可变
- 元组tuple不可变
- 集合set无序可变(还有个不可变集合frozenset)
- 数字number不可变
- 字符串string不可变