Python中的简单语法与常见操作
缩进是 Python的灵魂
关于 Python 的教程可参考廖雪峰的网站
https://www.liaoxuefeng.com/wiki/1016959663602400
1. 逻辑运算符
1 | df[(df['id']>=1) & (df['id']<=2)] |
2. 比较操作符
>, <, >=, <=, ==, !=
pandas进行条件筛选和组合筛选
参考 https://www.cnblogs.com/qxh-beijing2016/p/15499009.html
1 | df = pd.DataFrame({'A':[100, 200, 300, 400, 500],'B':['a', 'b', 'c', 'd', 'e'],'C':[1, 2, 3, 4, 5]}) |
(1)找出df中A列值为100、200、300的所有数据
1 | num_list = [100, 200, 300] |
(2)找出df中A列值为100且B列值为‘a’的所有数据
1 | df[(df.A==100)&(df.B=='a')] |
(3)找出df中A列值为100或B列值为‘b’的所有数据
1 | df[(df.A==100)|(df.B=='b')] |
注:多条件筛选的时候,必须加括号'()'
2.1 is vs ==
1 | print(True == 1) #True |
== checks for equality of value. 例如
True==1,其实比较的是
True==bool(1),会先转化成同一种类型再比较。但值得注意的是
'1'==1,结果为False,并没有先转化成同一种类型。在使用==的时候,最好比较的是同一类型的,不要让python
do the type conversion and hopefully python figures it out for us.
1 | print(True is 1) #False |
is actually checks if the location in memory where the
value is stored is the same. 为什么 [] is []
是False,因为每次create a list, it's added in memory somewhere (in
another location).
3. Python中的双引号
Python中双引号和单引号作用一样,即字符串可以用单引号也可以用双引号
4. type()
4.1 type()函数
1 | i = 4 |
4.2 dtype
查看type 1
2
3
4print(train["ID"].dtype)
# object
# 或 train["ID"].dtypes
1 | # 当单个数想转换type时,可直接使用 str(), int()等 |
例:
1 | # 将因缺失值而成为object的变量转换为float |
5. Python二维列表初始化
1 | [[0]*n for _ in range(m)] # m*n的二维列表 |
6. 查看列表中最小值所在位置(索引)
第一个位置
1
2
3listA.index(min(listA))
或:
np.argmax(listA)所有位置:
[i for i,v in enumerate(listA) if v == min(listA)]
7. 取top n
1 | # 写法一: |
8. 输出
参考:
https://www.runoob.com/w3cnote/python3-print-func-b.html
https://www.cnblogs.com/penphy/p/10028546.html
https://www.cnblogs.com/lovejh/p/9201219.html
简单的输出:
1 | >>>print('My name is', 'John') |
print不换行:
在 Python 中 print 默认是换行的:
1 | >>>for i in range(0,3): |
要想不换行应该写成 print(i, end = '' )
1 | for i in range(0,6): |
8.1 %用法
支持参数格式化,与 C 语言的 printf 类似
1 | >>>print('Hello, %s. Your age is %d.' % ('Johon', 20)) |
python字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
<sp> |
在正数前面显示空格 |
| # | 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
| 0 | 显示的数字前面填充'0'而不是默认的空格 |
| % | '%%'输出一个单一的'%' |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
8.1.1 格式化输出整数
%x --- hex 十六进制
%d --- dec 十进制
%o --- oct 八进制
1 | >>>nHex = 0xFF |
8.1.2 格式化输出浮点数
%f --- 保留小数点后面六位有效数字
%.3f -- 保留3位小数位
1 | >>>pi = 3.141592653 |
8.1.3 格式化输出字符串
%s
%10s --- 右对齐,占位符10位
%-10s --- 左对齐,占位符10位
%.2s --- 截取2位字符串
%10.2s ---10位占位符,截取两位字符串
1 | print('%s' % 'hello world') # 字符串输出 |
8.2 format用法
相对基本格式化输出采用‘%’的方法,format()功能更强大,该函数把字符串当成一个模板,通过传入的参数进行格式化,并且使用大括号‘{}’作为特殊字符代替‘%’
位置匹配
(1)不带编号,即“{}”
(2)带数字编号,可调换顺序,即“{1}”、“{2}”
(3)带关键字,即“{a}”、“{tom}”
1 | print('{} {}'.format('hello','world')) # 不带字段 |
想输出:The percentage of female students is 68.85%.👇
1 | str_student = "The percentage of female students is {:.2f}%.".format(68.8543) |
百分数:
1 | points = 1 |
千分位:
1 | df["金额"].apply(lambda x: f"{x:,.0f}") |
更多关于数字格式化的内容见 https://www.runoob.com/python/att-string-format.html
9. 切片操作
参考 https://www.liaoxuefeng.com/wiki/1016959663602400/1017269965565856
Python切片操作可作用于list (包括tuple, string)
可以想象为每个位置有两个编号:
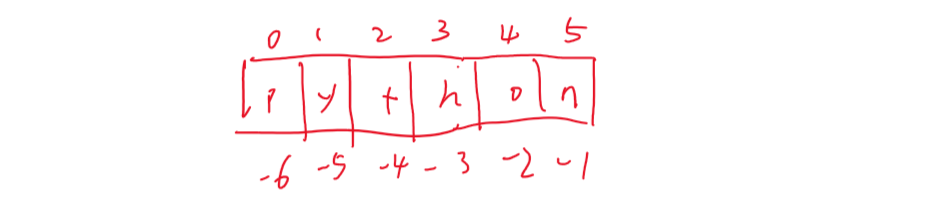
b = a[i:j] - 表示复制 a[i] 到
a[j-1],以生成新的list对象。例:
1 | a = [0,1,2,3,4,5,6,7,8,9] |
- 当 i 缺省时,默认为0,即 a[:3] 等价于 a[0:3]
- 当 j 缺省时,默认为 len(a),即 a[1:] 等价于 a[1:len(a)]
- 当 i, j 都缺省时,a[:] 就相当于完整复制一份 a (等价于 a.copy() 浅拷贝,注:更多关于浅拷贝与深拷贝的内容见我的另一篇博客)
b = a[i:j:s] - 其中 i 与 j
与上面一样,s 表示步进,缺省时默认为1.
1 | a = [0,1,2,3,4,5,6,7,8,9] |
- a[i:j:1] 等价于 a[i:j]
- 当 s<0 时(step小于0),i 缺省时默认为-1,j 缺省时默认为 -len(a) -1
- a[::-1] 等价于 a[-1:-len(a)-1:-1],即从最后一个元素f复制到第一个元素,即倒序
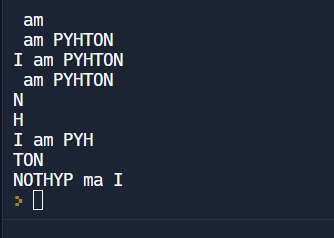
练习:
1 | python = 'I am PYHTON' |
结果:
另:dataframe中:
若想取第2列到第4列:
1
df.iloc[:, 2:5]
若想取第6列、第10列:
1
df.iloc[:, [6,10]]
若想取第2列到第4列,与第6列、第10列:
参考 How to slice continuous and discontinuous index in pandas? - Stack Overflow
使用numpy.r:
1
2import numpy as np
df.iloc[:, np.r_[2:5,6,10]]
10. 日期操作
参考:
https://blog.csdn.net/u010159842/article/details/78331490 https://blog.csdn.net/sinat_30715661/article/details/82534033
1 | import datetime |
字符转日期:
1 | >import datetime |
↑ strptime函数接收两个参数,第一个是要转换的字符串日期,第二个是日期时间的格式化形式。
日期加减:
当前时间的3天后:
1 | >import datetime |
指定时间的1天前:
1 | >import datetime |