Python读取与保存csv和txt文件
一、csv文件
1. 读取
1 | import pandas as pd |
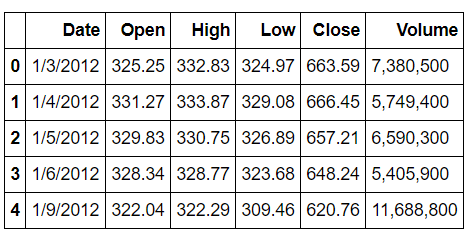
若文件中无列表头,需设定header = None,否则第一行会被识别为标题(如下图)
1 | import pandas as pd |
或者用names指定需要的列表头
1 | import pandas as pd |
另:关于读取csv文件,报错:
参考 https://www.cnblogs.com/huangchenggener/p/10983812.html
1 | 'utf-8' codec can't decode byte 0xd4 in position 0: invalid continuation byte |
法一:csv文件的保存格式改为 "CSV UTF-8 (逗号分割) (*.csv)"
法二:pd.read_csv()中加上编码方式:
1 | pd.read_csv("xxx.csv", encoding='gbk') |
2. 保存
1 | import pandas as pd |
另:关于使用to_csv保存后,打开csv有中文乱码问题:
若有乱码问题,使用如下语句:
1 | df.to_csv("xxx.csv", index=False, encoding='utf_8') |
二、txt文件
1. 读取
(注:法一和法二都有可能会造成行数缺少或数据分割不正确的现象,建议采用法三)
法一
1 | import pandas as pd |
法二
1 | import pandas as pd |
法三
1 | ####### example 1 ######### |
2. 保存
方法同csv
1 | RF_test.to_csv("RF_test.txt", sep = '\t', index = False) |
三、json文件
参考 https://blog.csdn.net/weixin_38842821/article/details/108359551 https://zhuanlan.zhihu.com/p/373661877 https://vimsky.com/examples/usage/json-dump-in-python.html
1. 保存
1 | import json |
2.读取
1 | import json |
3. 含中文时
1 | #如果是在python3环境,可使用: |
1 | # 如果是在python3环境保存,python2环境中读取:含中文时,先使用json.dumps()将python对象转换成json字符串,再使用pickle保存 |
关于 json.dump(), json.dumps(), json.load(), json.loads():
| 方法 | 作用 |
|---|---|
| json.dump() | 将python对象转化成json存储到文件中 |
| json.dumps() | 将python对象编码成json字符串 |
| json.load() | 将json文件转化成python对象提取出来 |
| json.loads() | 将json字符串解码成python对象 |
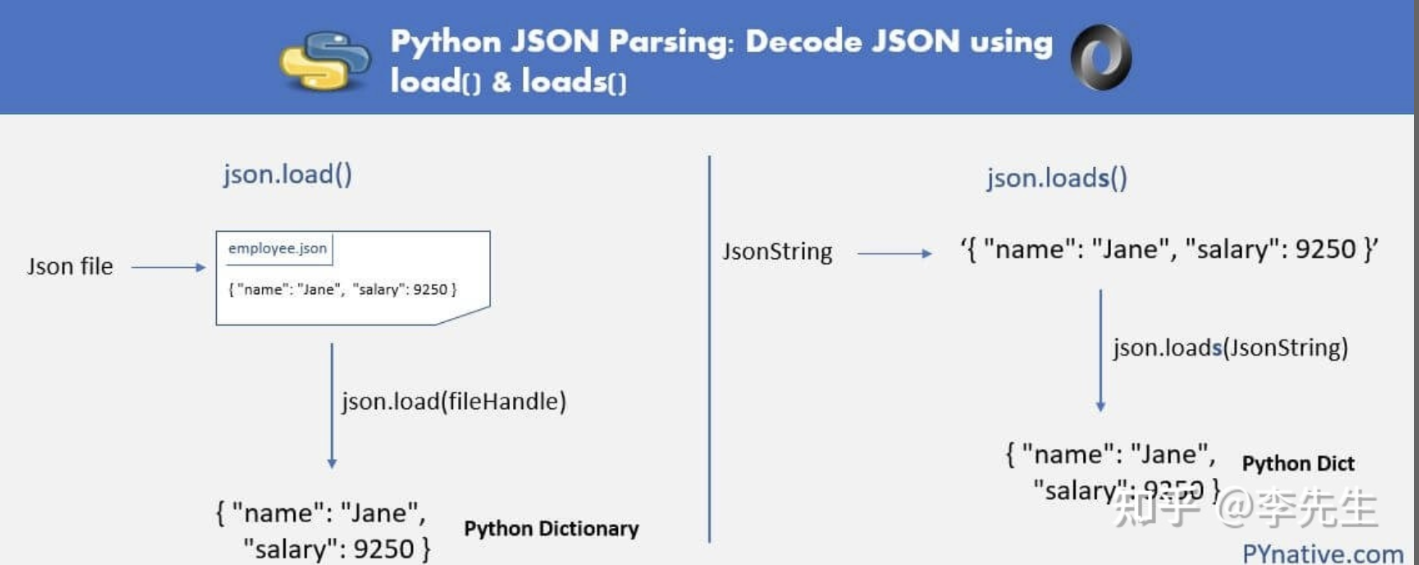
用法:
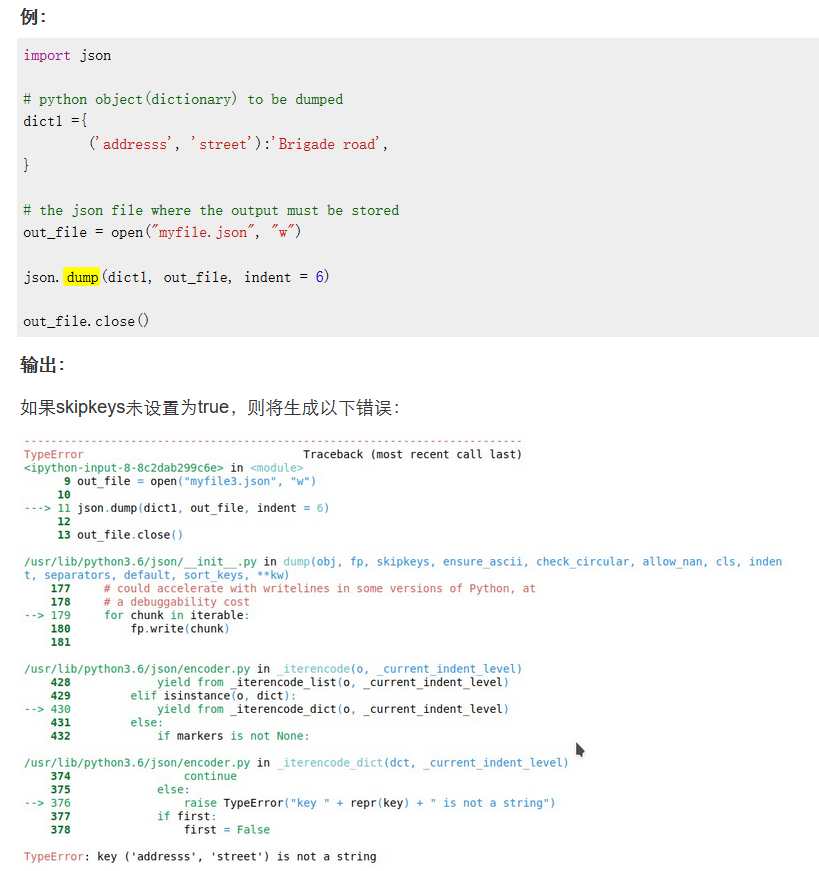
1 | json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw) |
四、pickle文件
官方文档:https://docs.python.org/3/library/pickle.html
The pickle
module implements binary protocols for serializing and de-serializing a
Python object structure. “Pickling” is the process whereby a
Python object hierarchy is converted into a byte stream, and
“unpickling” is the inverse operation, whereby a byte stream
(from a binary
file or bytes-like
object) is converted back into an object hierarchy. Pickling (and
unpickling) is alternatively known as “serialization”, “marshalling,”
[1](https://docs.python.org/3/library/pickle.html#id7) or “flattening”;
however, to avoid confusion, the terms used here are “pickling” and
“unpickling”.
pickle模块实现了用于序列化和反序列化Python对象结构的二进制协议。pickle是将Python对象层次结构转换为字节流的过程,而unpickle是反向操作,即将字节流(从二进制文件或字节类对象)转换回对象层次结构。
Warning:
The
picklemodule is not secure. Only unpickle data you trust.It is possible to construct malicious pickle data which will execute arbitrary code during unpickling. Never unpickle data that could have come from an untrusted source, or that could have been tampered with.
Consider signing data with
hmacif you need to ensure that it has not been tampered with.Safer serialization formats such as
jsonmay be more appropriate if you are processing untrusted data. See Comparison with json.
pickle与json的区别:
- JSON is a text serialization format (it outputs unicode text,
although most of the time it is then encoded to
utf-8), while pickle is a binary serialization format; JSON是一种文本序列化格式(它输出unicode文本,尽管大多数时候它会被编码成utf-8),而pickle是一种二进制序列化格式 - JSON is human-readable, while pickle is not; JSON是人类可读的,而pickle不是
- JSON is interoperable and widely used outside of the Python ecosystem, while pickle is Python-specific; JSON是可互操作的,在Python生态系统之外被广泛使用,而pickle是特定于Python的
- JSON, by default, can only represent a subset of the Python built-in types, and no custom classes; pickle can represent an extremely large number of Python types (many of them automatically, by clever usage of Python’s introspection facilities; complex cases can be tackled by implementing specific object APIs); 默认情况下,JSON只能表示Python内置类型的子集,而不能表示自定义类;pickle可以表示非常多的Python类型(其中许多是通过巧妙地使用Python的内省工具自动实现的;复杂的情况可以通过实现特定的对象api来解决)
- Unlike pickle, deserializing untrusted JSON does not in itself create an arbitrary code execution vulnerability. 与pickle不同,反序列化不受信任的JSON本身并不会产生任意代码执行漏洞。
目前有6种不同的协议可以用于pickling。使用的协议越高,读取生成的pickle所需的Python版本就得越新。
- Protocol version 0 is the original “human-readable” protocol and is backwards compatible with earlier versions of Python. 协议版本0是原始的人类可读的协议,并向后兼容较早版本的Python
- Protocol version 1 is an old binary format which is also compatible with earlier versions of Python. 协议版本1是一种旧的二进制格式,它也与早期版本的Python兼容。
- Protocol version 2 was introduced in Python 2.3. It provides much more efficient pickling of new-style classes. Refer to PEP 307 for information about improvements brought by protocol 2. 协议版本2是在Python 2.3中引入的。它针对 new-style classes 提供了更有效的pickling。
- Protocol version 3 was added in Python 3.0. It has explicit support
for
bytesobjects and cannot be unpickled by Python 2.x. This was the default protocol in Python 3.0–3.7. 协议版本3是在Python 3.0中添加的。它对bytes对象有显式的支持,并且不能被Python 2.x unpickle。这是Python 3.0-3.7中的默认协议。 - Protocol version 4 was added in Python 3.4. It adds support for very large objects, pickling more kinds of objects, and some data format optimizations. It is the default protocol starting with Python 3.8. Refer to PEP 3154 for information about improvements brought by protocol 4. 协议版本4是在Python 3.4中添加的。它增加了对非常大的对象的支持,pickle更多类型的对象,以及一些数据格式优化。这是从Python 3.8开始的默认协议。
- Protocol version 5 was added in Python 3.8. It adds support for out-of-band data and speedup for in-band data. Refer to PEP 574 for information about improvements brought by protocol 5. 协议版本5是在Python 3.8中添加的。它增加了对带外数据的支持和对带内数据的加速。
关于 pickle.dump(), pickle.dumps(), pickle.load(), pickle.loads():
| 方法 | 作用 |
|---|---|
| pickle.dump(obj, file, protocol=None, ***) | 将对象obj的pickle表示写入打开的文件对象file |
| pickle.dumps(obj, protocol=None, ***) | 将对象obj的pickle表示作为一个bytes object返回,而不是将其写入文件。 |
| pickle.load(file, **, fix_imports=True, encoding='ASCII', errors='strict', buffers=None*) | 从打开的文件对象file中读取对象的pickle表示,并返回其中指定的 reconstituted object hierarchy。 |
| pickle.loads(data, /, **, fix_imports=True, encoding="ASCII", errors="strict", buffers=None*) | Return the reconstituted object hierarchy of the pickled representation data of an object. data must be a bytes-like object. |
1. 保存
例:保存xgb模型
1 | import pickle |
2. 读取
1 | import pickle |