dat = pd.DataFrame({'id':[1,2,3], 'string': ['a', 'b','c']})
法二(若已有现成的list)
1 2 3
dat = pd.DataFrame([n_clusters_start, score], columns = ["分类数", "得分"]) # 或 dat = pd.DataFrame({"分类数": n_clusters_start, "得分": score})
例:
1 2 3 4 5 6 7
exclamationCount = lambda text: sum([1for x in text if x == '!']) EC = tweet.apply(lambda x:exclamationCount(x)) EC = EC.tolist() questionMarkCount = lambda text: sum([1for x in text if x == '?']) QC = tweet.apply(lambda x:questionMarkCount(x)) QC = QC.tolist() dat = pd.DataFrame({'EC':EC,'QC':QC})
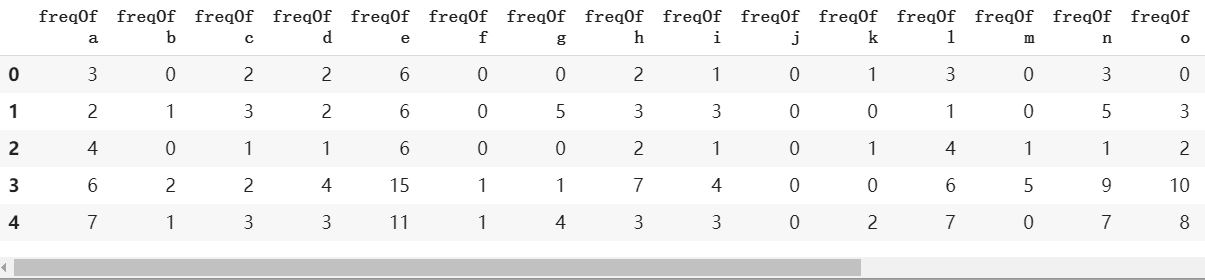
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
eachLetterCount = lambda text,letter: sum([1for x in text.lower() if x == letter])
FList = [] pattern = 'abcdefghijklmnopqrstuvwxyz' j=0 for i in pattern: F = tweet.apply(lambda x:eachLetterCount(x,i)) F = F.tolist() FList.append(F)
res = pd.DataFrame(FList) res = res.transpose()
pattern = 'abcdefghijklmnopqrstuvwxyz' name = [] for i in pattern: name.append("freqOf " + i) res.columns = name
结果
2. 数据框拼接
ignore_index = True, 重新分配索引
2.1 append
1
result = result1.append(result2, ignore_index = True) # 粘贴行