A Recommender Engine Framework
What we need now is a framework to let us easily experiment with new recommender system algorithms, evaluate them, and compare them against each other.
1. Our Recommender Engine Architecture
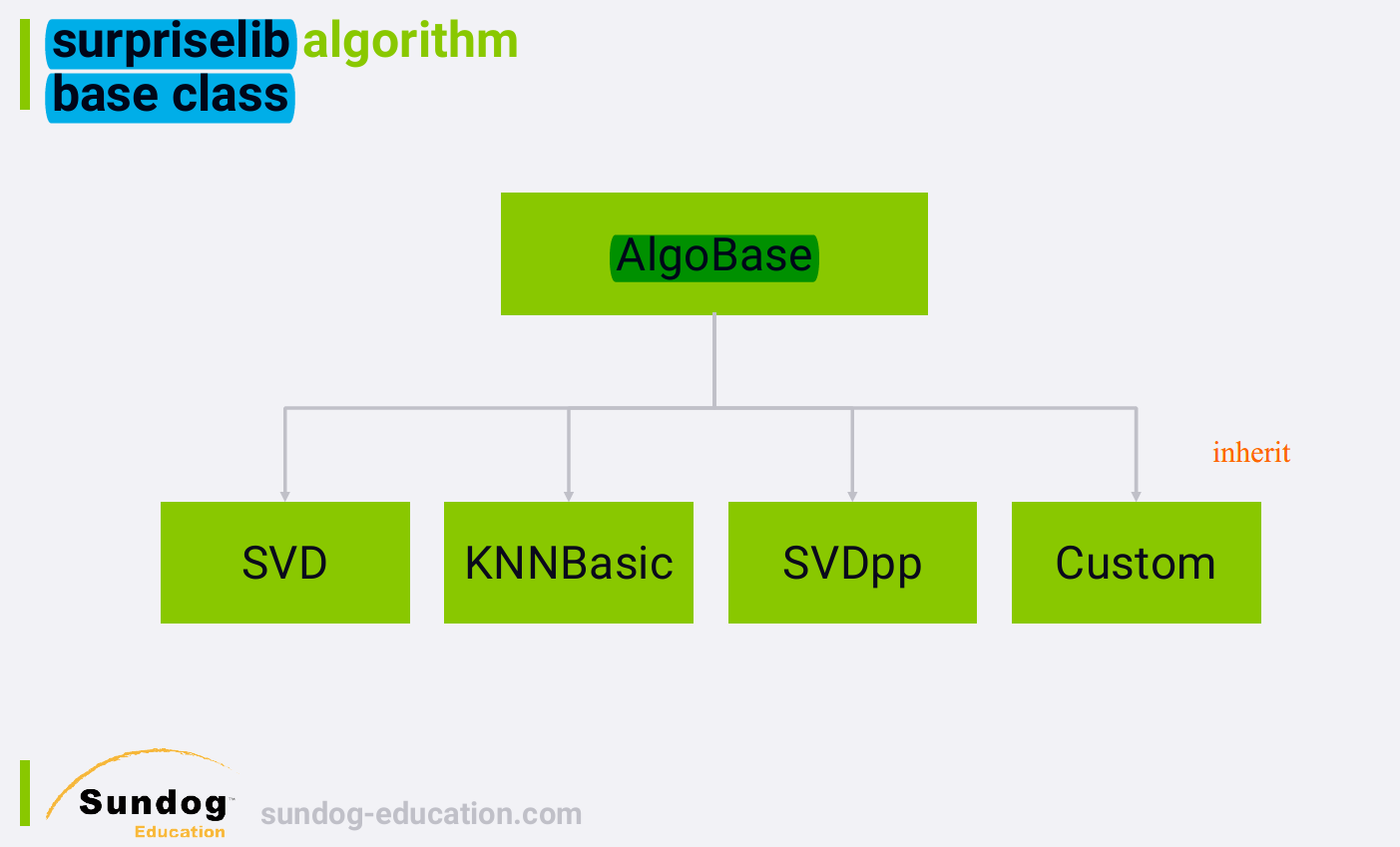
Object oriented design allows us to have base classes, for example, AlgoBase, that contain functions and variables that can be shared by other classes that inherit from that base class. 例如AlgoBase中实现了fit和test方法,则无论我们实际上使用的是什么算法,我们都可以调用fit和test方法。
Custom指的是any custom algorithm we might develop (自己写的recommender system), and make them part of the supriselib framework.
Create a custom algorithm
So, how do you write your own recommender algorithm that's compatible with surpiselib?

All you have to do is create a new class that inherits form AlgoBase, and as far as supriselib is concerned, your algorithm has one job: to predict ratings.
As we mentioned, supriselib is built around the architecture of predicting the ratings of every movie for every user, and giving back the top predictions as your recommendations.
Your class have to implement an estimate function.
When estimate is called by supriselib framework, it's asking you to predict a rating for the user and item passed in.
注:这里的user id和item id是inner id. Must be mapped back to the raw user and item ids in your source data.
- Now, we want to do more than just predict ratings.
我们想要很简单的将之前在
RecommenderMetrics中实现的不同的evaluation metrics应用到algorithms we work with.

为了做到这一点,我们将创建一个新的class叫做EvaluatedAlgoritm,里面创建了一个新的函数叫做Evaluate,that
runs all the metrics in RecommenderMetrics on that algorithm. So this
class makes it easy to measure accuracy, coverage, diversity and
everything else on a given algorithm.
不同的评估方法,要求对数据集的不同分割方式,于是我们创建了另一个新的class:
EvaluationData来做到这一点。如何连接这一切?
We create an EvaluationData instance with our data set,
create an EvaluatedAlgorithm for each algorithm we want to
evaluate, and call Evaluate on each algorithm using the
same EvaluationData. Under the hood,
EvaluatedAlgorithm will use all the functions we defined in
RecommenderMetrics to measure accuracy, hit rate,
diversity, novelty, and coverage.
- Since what we generally want to do is 比较不同推荐系统, we can make
life even easier by writing a class that takes care of all the
comparison for us. 于是我们创建了新的class:
Evaluator.
Ideally, we want to just submit algorithms we want to evaluate against each other into this class, and let it do everything from there.

The beauty of this is that you don't even have to use the
EvalutedAlgorithm or EvaluatedData classed at
all, when you want to start playing around with new algorithms and
testing them against each other. All you need to do is use this
Evaluator class, which has a really simple interface.
将上述framework写好后,如下这是我们比较SVD算法与random算法所需要的所有代码:

2. Code Walkthrough
Framework文件夹里:

结果分析

我们比较的是SVD和随机推荐。SVD is one of the best algorithms available right now, so it shouldn't be surprise that SVD beats random recommendation in accuracy and hit rate no matter how we measure it.
- RMSE和MAE: lower is better.
- Hit rate,包括cHR, ARHR: higher is better.
- Coverage, diversity, novelty: need to apply some common sense to, as it's not a clear higher-is-better sort of thing. There are trade-offs involved with these metrics.
就Coverage而言,SVD的要低一些: that's just because we are enforcing a quality threshold on the top-N recommendations we're making with SVD, while our random recommender isn't actually making totally random recommendations, it's predicting movie ratings using what's called a normal distribution centered around the average rating value, which ends up meaning all of the rating predictions it makes fall above our rating threshold, giving us 100% coverage. Having 100% coverage at the expense of having bad recommendations isn't a trade-off worth making.
就Diversity和Novelty而言,SVD的都要低一些,这是我们所预期会出现的。