Content-Based Filtering
Recommending items just based on the attributes of those items, instead of trying to use aggregate user behavior data.
Cosine Similarity

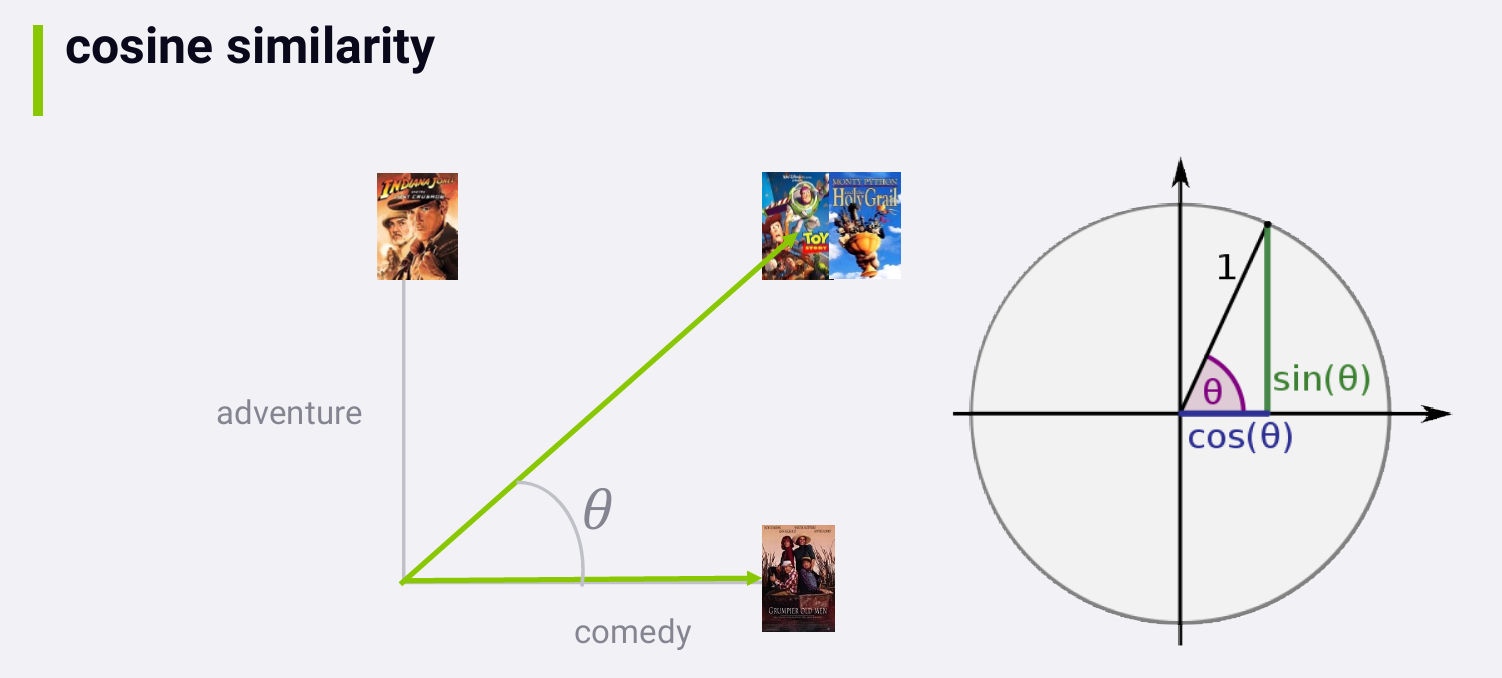
为简单起见,假设电影只有两种类型:adventure和comedy. 一部电影若属于某种类型则为1,若不属于则为0.
角度 θ 一定程度上刻画了它们之间的相似度。我们想要将相似度刻画成[0,1]范围内的数,zero means not at all similar, and one means totally the same thing. 而 θ 的余弦值正好可以达到这个目的:θ 为90度,余弦值为0;θ 为0度,余弦值为1.

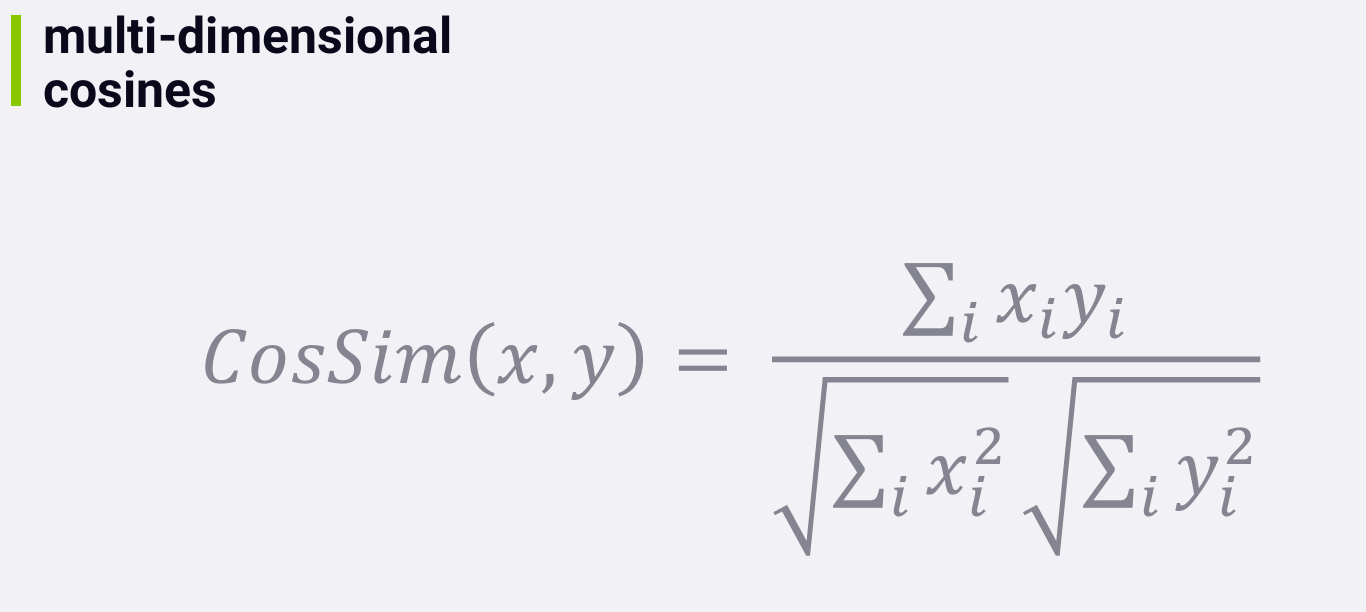

1 | def computeGenreSimilarity(self, movie1, movie2, genres): |

How do we assign a similarity score based on release years alone?
This is where some of the art of recommender systems comes in. You have to think about the nature of the data you have and what makes sense.
How far apart would two movies have to be for their release date alone to signify they are substantially different? A decade seems like a reasonable starting point.
Now we need to come up with some sort of mathematical function that smoothly scales that into the range zero to one. -> 可选择指数衰减函数。
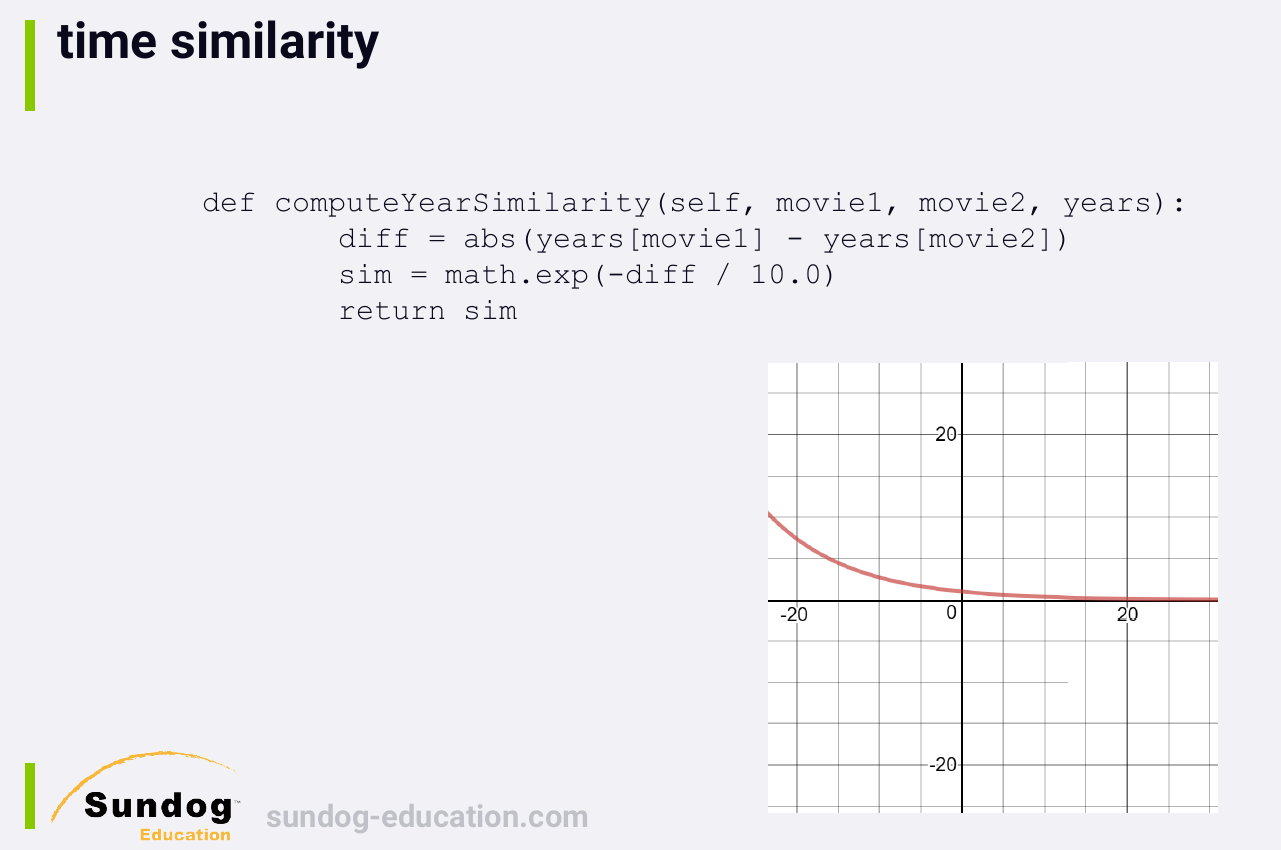
1 | def computeYearSimilarity(self, movie1, movie2, years): |
The choice of this function is completely arbitrary, but it seems like a reasonable starting point. In the real world, you'd test many variations of this function to see what really produces the best recommendations with real people.
K-nearest-neighbors
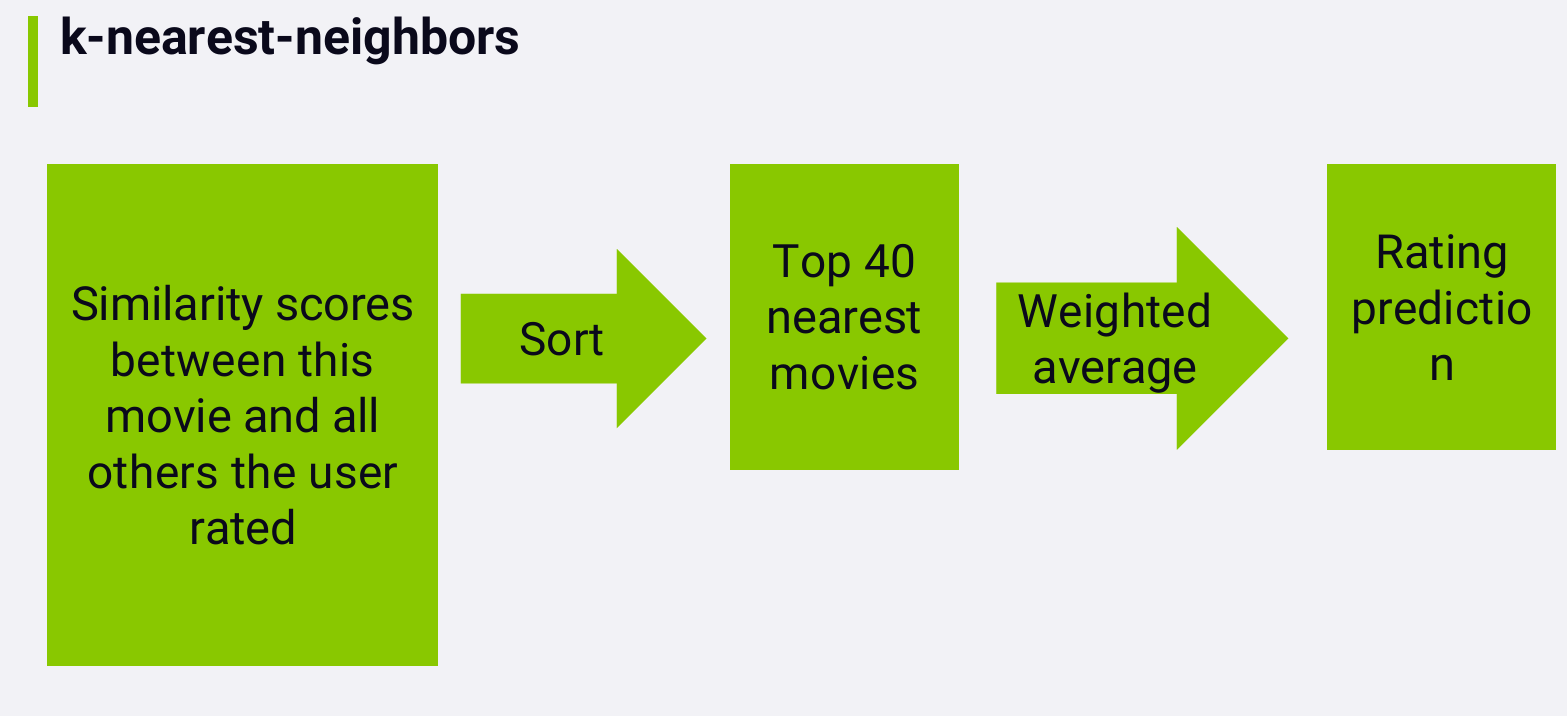
So how do we turn these similarities between movies based on their attributes into actual rating predictions?

Code Walkthrough
ContentBased里的文件:

从结果可以看到,Content-based algorithm比random recommendations 表现得要好。
Bleeding Edge Alert
注:We often refer to the current state of the art as leading edge, but technology that's still so new that it's unproven in the real world can be risky to work with, and so we call that bleeding edge.
This is where we highlight some new research that looks interesting and promising, but hasn't really made it into mainstream yet with recommender systems.
mise en scene
Some recent research and content based filtering has surrounded the use of mise en scene data. Technically, mise en scene refers to the placement of objects in a scene, but the researchers are using this term a bit more loosely to refer to the properties of the scenes in a movie or movie trailer.

The idea is to extract properties from the film itself that can be quantified and analyzed, and see if we can come up with better movie recommendations by examining the content of the movie itself scene by scene.
What sort of attributes are we talking about:
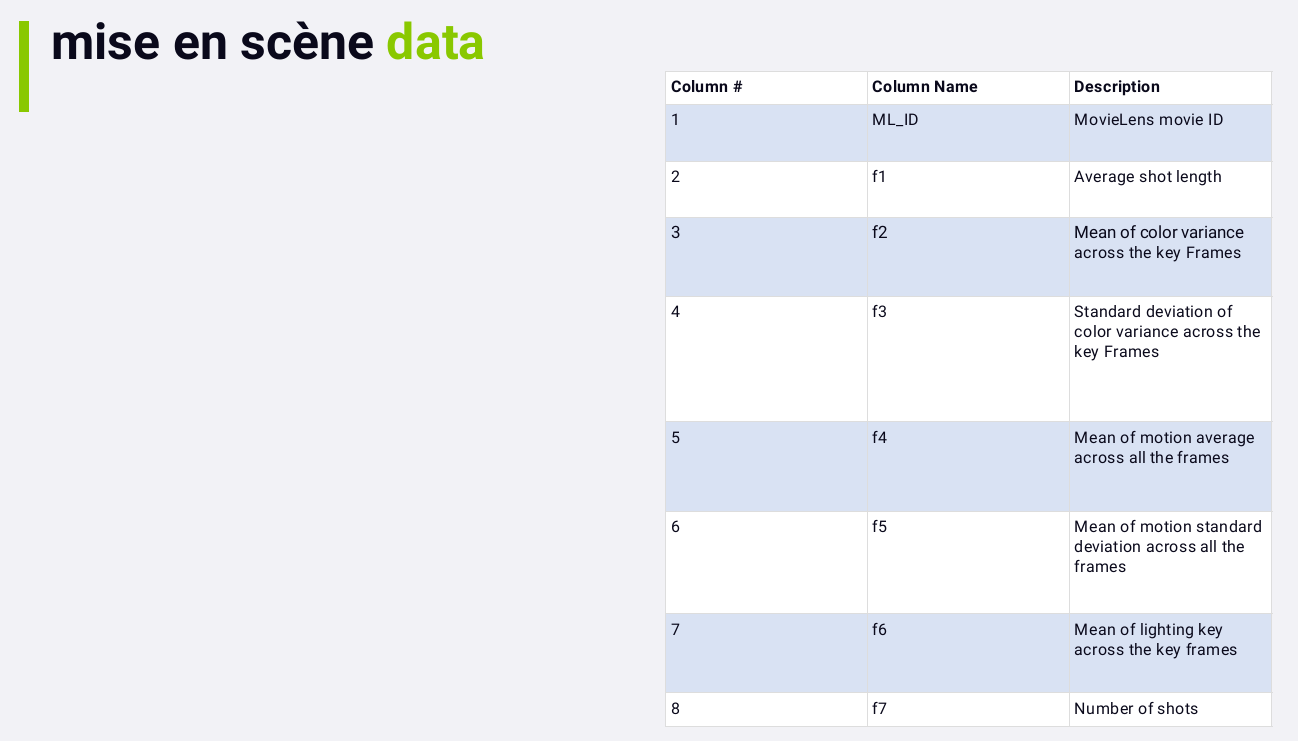
In principle, this should give us a feel as to the pacing and mood of the film, just based on the film itself.
Q:这样的数据和原来使用的 human generated genre classification 相比,是否更加有效?
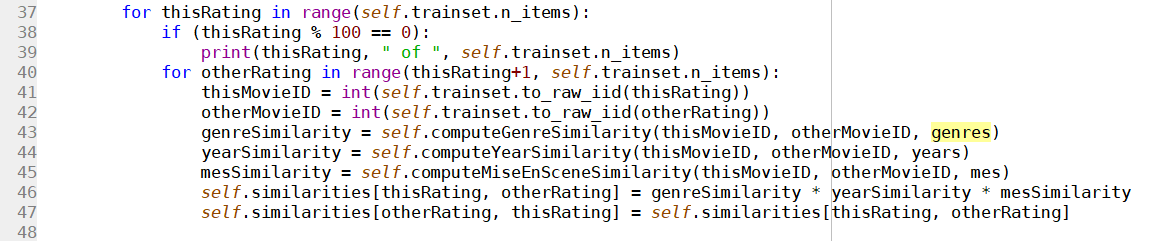
更改代码:
去掉ContentKNNAlgorithm.py中第45行的注释,再在第46行上加上
* mesSimilarity:
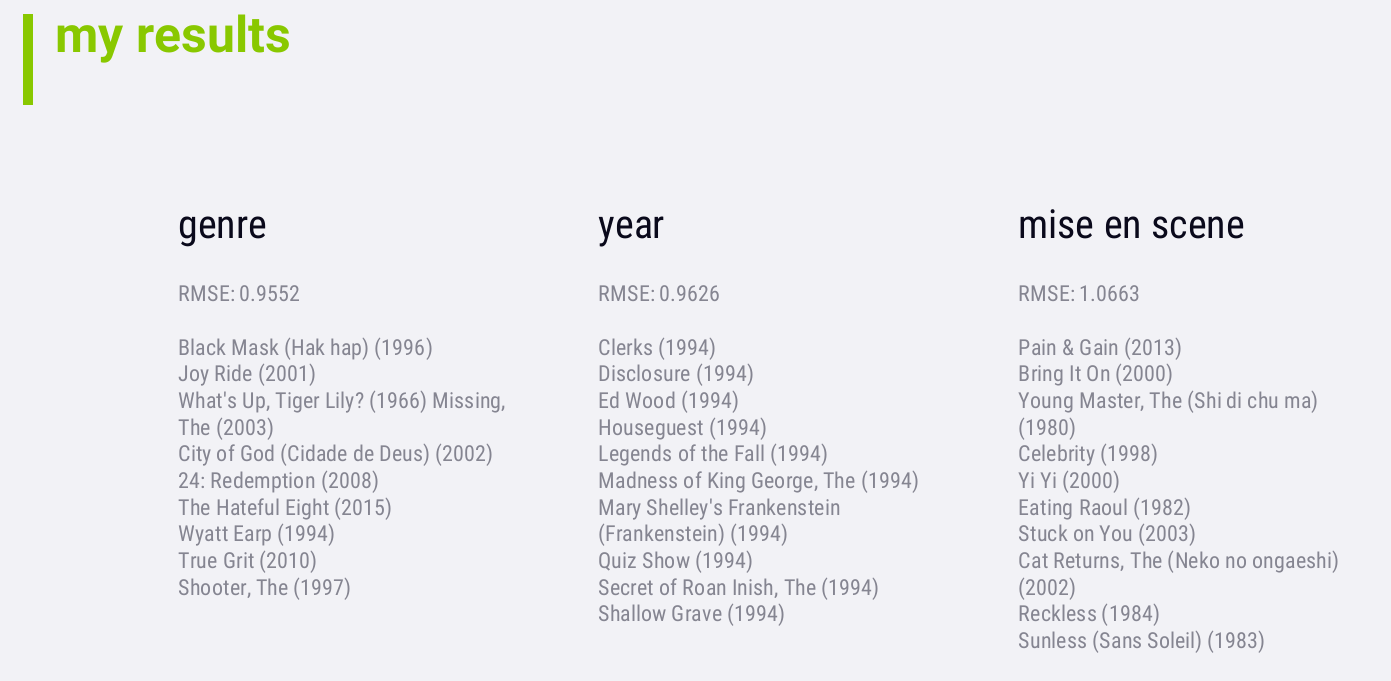
再运行ContentRec.py,可得到结果如下:

从结果上看,RMSE actually got a lot worse. 一方面,This could just be an artifact of how we chose to compute mise en scene similarity scores. 另一方面,Accuracy isn't really what we're concerned with.
Again, sometimes developing recommendation systems is more an art than a science. You can't really predict how real people will react to new recommendations they haven't seen before. Personally, I'd be tempted to test this in an A/B test to see how it performs.
If you look at the research literature associated with mise en scene recommendations however, they note that it doesn't do any favors to accuracy, but it does increase diversity. But again, increased diversity isn't always a good thing when it comes to recommendations. It may just mean that you're recommending random stuff that has no correlation to the user's actually interest. Still, it was interesting to experiment with it, and it would be even more interesting to experiment with it using real people
Here's a reference to the original research paper:

Exercise
- Use genre, release year, and mise en scene data independently.
- See if you improve the release year based recommendations by sorting the k nearest neighbors within a given year by popularity. (sort the year-based recommendations by popularity as a secondary sort)
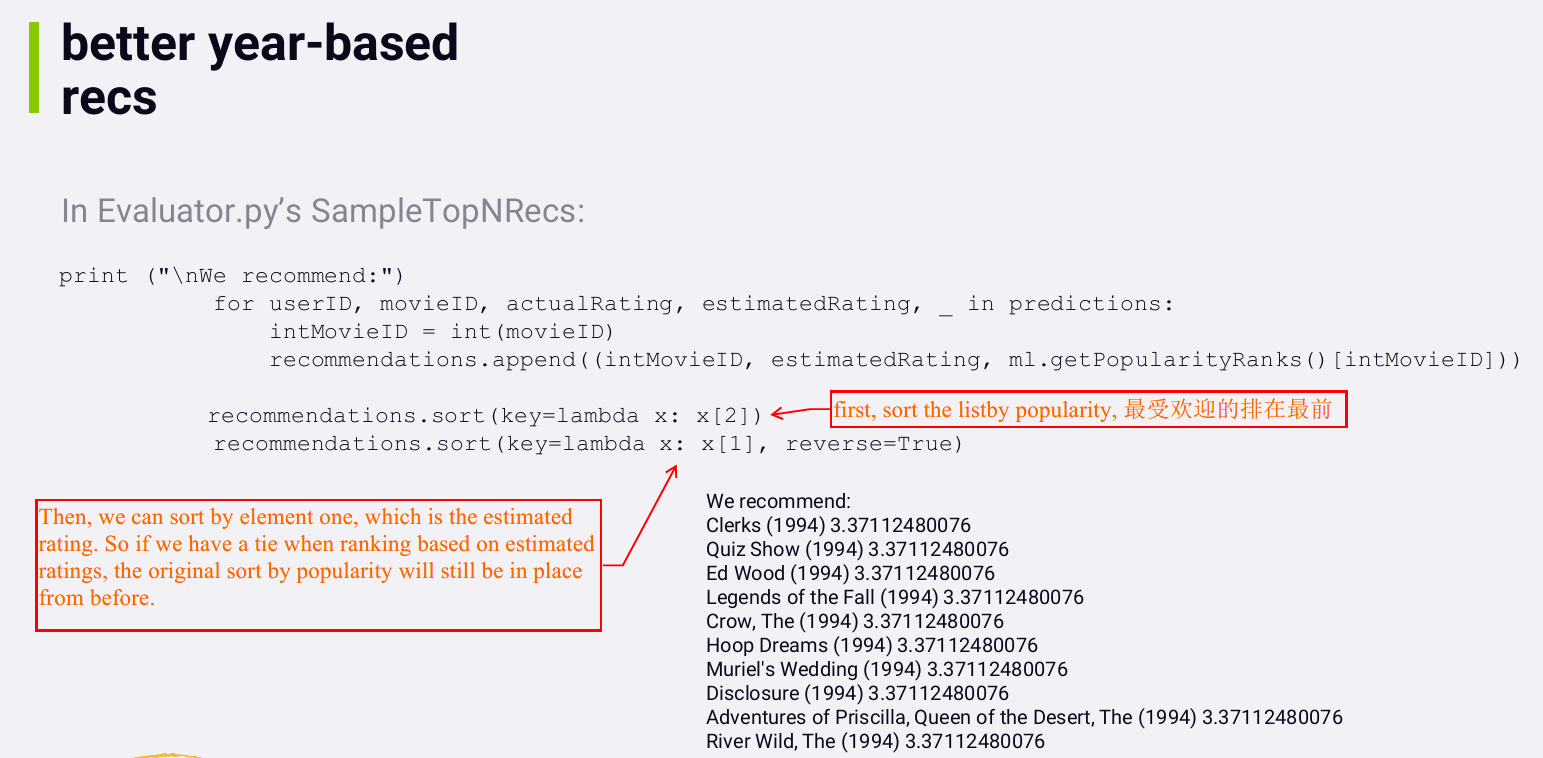
Now by using popularity data, technically we're no longer limiting our recommendations to content attributes. Popularity is behavior-based data.