Hive介绍
参考: https://blog.csdn.net/PowerBlogger/article/details/83626449 https://blog.csdn.net/u010886217/article/details/83796151 《Hadoop构建数据仓库实践》
更多内容见Hive官方文档 https://cwiki.apache.org/confluence/display/Hive/Home#Home-UserDocumentation
1. 什么是Hive?
Hive 是 Hadoop 生态圈的数据仓库软件,里面有表的概念,使用类似于 SQL 的语言(HiveQL)读、写、管理分布式存储上的大数据集。它建立在 Hadoop 之上,具有以下功能和特点:
- 通过 HiveQL 方便地访问数据,适合执行 ETL、报表查询、数据分析等数据仓库任务。
- 提供一种机制,给各种各样的数据格式添加结构。
- 直接访问 HDFS 的文件,或者访问如 HBase 等其他数据存储。
- 可以通过 MapReduce、Spark 或 Tez 等多种计算框架执行查询。
Hive 被设计成一个可扩展的、高性能的、容错的、与输入数据格式松耦合的系统,适合于数据仓库中的汇总、分析、批处理查询等任务,而不适合联机事务处理(OLTP)的工作场景。Hive 包括 HCatalog 和 WebHCat 两个组件。HCatalog 是 Hadoop 的表和存储管理层,允许使用 Pig 和 MapReduce 等数据处理工具的用户更容易读写集群中的数据。WebHCat 提供了一个服务,可以使用 HTTP 接口执行 MapReduce (或 YARN)、Pig、Hive 作业或元数据操作。
HiveQL 只处理结构化数据,并且不区分大小写(与SQL一样)。
Hive 里的数据最终存储在 HDFS 的文件中,常用的数据文件格式有以下4种:TEXTFILE、SEQUENCEFILE、RCFILE、ORCFILE。(关于文件格式的更详细内容见 3.1.2 file format)。在 Hive 中文件格式指的是记录以怎样的编码格式被存储到文件中。不同文件格式的主要区别在于它们的数据编码、压缩率、使用的空间和磁盘I/O。在加载数据的过程中,Hive不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的HDFS目录中。
当用户向传统数据库中增加数据时,系统会检查写入的数据与表结构是否匹配,如果不匹配则拒绝插入数据,这就是所谓的写时模式。Hive与此不同,它使用的是读时模式,即直到读取时再进行数据校验(加载数据时不进行数据格式的校验,读取数据时如果不合法则显示NULL。这种模式的优点在于加载数据迅速)。在向 Hive 装载数据时,它并不验证数据与表结构是否匹配,但这时它会检查文件格式是否和表定义相匹配。
2. Hive的原理
Hive 将用户的 HiveQL 语句进行解析,优化,最终把一个个的HiveQL语句转换为 MapReduce 作业提交到 Hadoop 集群上,Hadoop进行作业的调度及监控,作业完成后将执行结果返回给用户。所以,Hive并不进行计算,只是把HiveQL解析为MapperReduce在HDFS集群中运行而已,所以Hive的效率并不高。
2.1 Hive 的体系结构
Hive 的体系结构如下图所示:
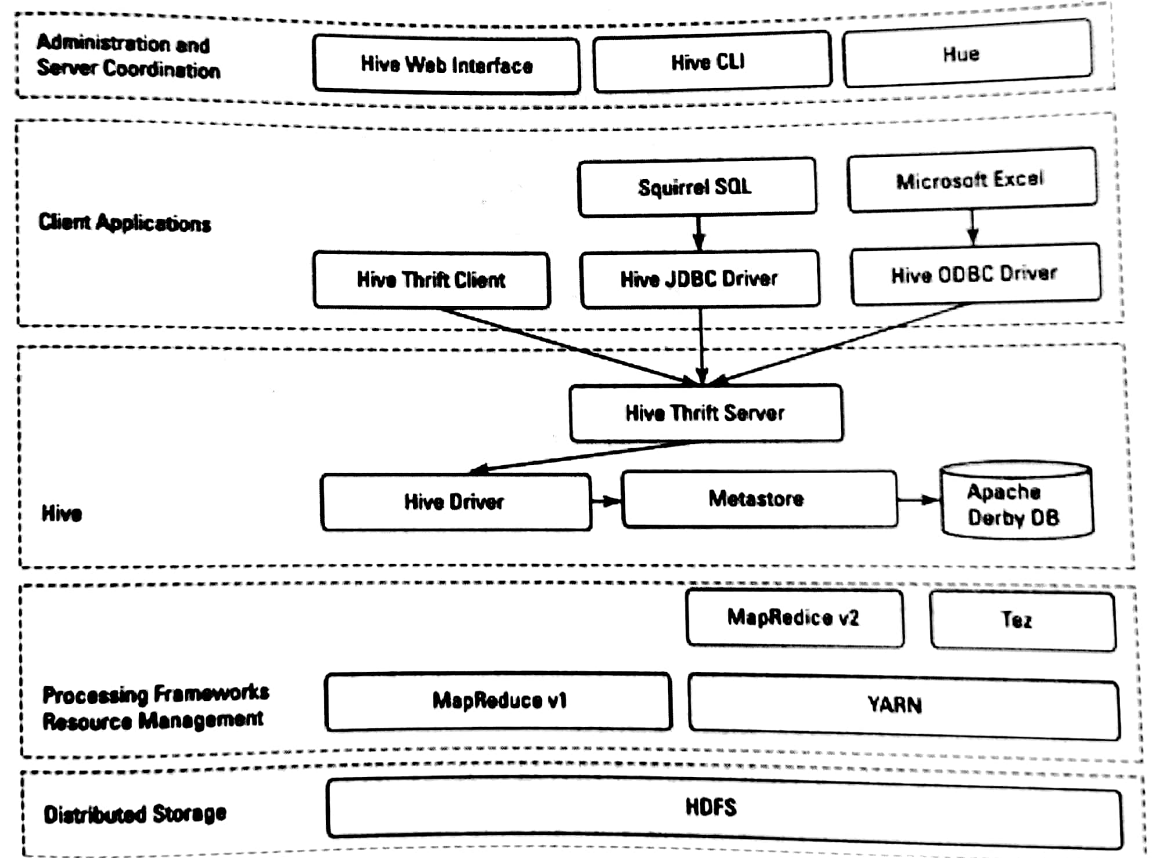
Hive建立在 Hadoop 的分布式文件系统 HDFS 和 MapReduce 之上。上图显示了 Hadoop1 和 Hadoop2 中的两种 MapReduce 组件。
在 HDFS 和 MapReduce 之上,图中显示了 Hive 驱动程序和元数据存储。Hive 驱动程序及其编译器负责编译、优化和执行 HiveQL。依赖于具体情况,Hive 驱动程序可能选择在本地执行 Hive 语句或命令,也可能是产生一个 MapReduce 作业。Hive 驱动程序把元数据存储在数据库中。
默认配置下,Hive 在内建的 Derby 关系数据库系统中存储元数据,这种方式被称为嵌入模式。在这种模式下,Hive 驱动程序、元数据和 Derby 全部运行在同一个 Java 虚拟机中(JVM)。它只支持单一 Hive 会话,所以不能用于多用户的生产环境。Hive 还允许将元数据存储于本地或远程的外部数据库中,这种设置可以更好地支持 Hive 的多会话生产环境。并且,可以配置任何与 JDBC API 兼容的关系数据库系统存储元数据,如 MySQL、Oracle 等。(元数据默认存储在Hive自带的Derby数据库中,但由于Derby不能实现并发访问,所以我们一般使用 MySQL 进行替换)。
对应用支持的关键组件是 Hive Thrift 服务。任何与 JDBC 兼容的应用,都可以通过绑定的 JDBC 驱动访问 Hive。与 ODBC 兼容的客户端,如 Linux 下典型的 unixODBC 和 isql 应用程序,可以从远程 Linux 客户端访问 Hive。
架构图的最上面包括一个命令行接口(CLI),可以在 Linux 终端窗口向 Hive 驱动程序直接发出查询或管理命令。还有一个简单的 Web 界面,通过它可以从浏览器访问 Hive 管理表及其数据。
3. Hive建表语句
参考 https://blog.csdn.net/qq_36743482/article/details/78383964 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
Hive建表方式共有三种:
- 直接建表法
- 查询建表法
- like建表法
3.1 法一:直接建表法
1 | create table table_name(col_name data_type); |
完整的syntax:
1 | CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later) |
data_type可选内容: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
(👆来自官网 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL [] 表示可选,| 表示选其一)
注:
- 不使用 EXTERNAL 时,创建的是内部表。
- 表和列的注释(COMMENT)是字符串文字(单引号)。
- 要为表指定一个数据库,要么在
CREATE TABLE语句之前使用USE database_name语句,要么用一个数据库名称限定表名(database_name.table_name)。 - See Alter Table for more information about table comments, table properties, and SerDe properties.
- See Type System and Hive Data Types for details about the primitive and complex data types.
这里我们针对里面的一些不同于关系型数据库的地方进行说明。
3.1.1 row format
1 | ROW FORMAT DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] |
Hive将HDFS上的文件映射成表结构,通过分隔符来区分列(比如‘,’, ‘;’ or ‘^’等),row format就是用于指定序列化和反序列化的规则。 比如对于以下记录:
1 | 1,xiaoming,book-TV-code,beijing:chaoyang-shanghai:pudong |
逗号用于分割列,即FIELDS TERMINATED BY ',',分割为如下列
ID、name、hobby(该字段是数组形式,通过
'-'
进行分割,即COLLECTION ITEMS TERMINATED BY '-')、address(该字段是键值对形式map,通过
':' 分割键值,即
MAP KEYS TERMINATED BY ':');而
LINES TERMINATED BY char
用于区分不同条的数据,默认是换行符。
写法形如:
1 | create table xxx( |
3.1.2 file format(HDFS文件存放的格式)
1 | file_format |
默认TEXTFILE,即文本格式,可以直接打开。
a) TEXTFILE
TEXTFILE就是普通的文本型文件,是 Hadoop 里最常用的输入输出格式,也是 Hive 的默认文件格式。如果表定义为TEXTFILE,则可以向该表中装载以逗号、TAB或空格作为分隔符的数据,也可以导入JSON格式的数据。 文本文件中除了可以包含普通的字符串、数字、日期等简单数据类型外,还可以包含复杂的集合数据类型。Hive 支持 STRUCT、MAP 和 ARRAY 三种集合数据类型。
示例1:以TAB为列间分隔符的文本文件
创建一个文本文件/root/data.csv,录入四列两行数据,列之间用TAB符号作为分隔符,文件内容如下:
1 | a1 1 b1 c1 |
执行下面的语句创建表、装载数据、查询表。
1 | -- 建立TEXTFILE格式的表 |
(关于load的详细介绍见5.2 Load)
查询结果如下所示:
1 | hive> select * from t_textfile; |
示例2:JSON格式的数据文件
建立一个json文件/root/simple.json,内容如下:
1 | {"foo":"abc", "bar":"2009101100000", "quux":{"quuxid":1234, "quuxname":"sam"}} |
执行下面的语句创建表、装载数据、查询表。
1 | -- 根据实际目录添加hive-hcatalog-core.jar包 |
查询结果如下所示:
1 | OK |
示例3:complex_json表中含有结构类型嵌套和结构、数组、结构三层嵌套
建立一个json文件/root/complex.json,内容如下:
1 | {"docid":"abc", "user": |
执行下面的语句创建表、装载数据、查询表。
1 | -- 建立测试表 |
查询结果如下所示:
1 | OK |
查询:
1 | select docid, user.id, user.orders.itemid from complex_json; |
查询结果:
1 | OK |
b) SEQUENCEFILE
Hadoop处理少量大文件比大量小文件的性能要好。如果文件小于Hadoop定义的块尺寸(Hadoop 2.x默认是128MB),可以认为是小文件。元数据的增长将转化为NameNode的开销。如果有大量小文件,NameNode会成为性能瓶颈。为了解决这个问题,Hadoop引入了sequence文件,将sequence作为存储小文件的容器。
Sequence文件是由二进制键值对组成的平面文件。Hive将查询转化成MapReduce作业时,决定一个给定记录的哪些键/值对被使用。Sequence文件是可分割的二进制格式,主要的用途是联合多个小文件。
SEQUENCEFILE格式的输入输出包是:
1 | org.apache.hadoop.mapred.SequenceFileInputFormat |
示例
1 | -- 建立SEQUENCEFILE格式的表 |
c) RCFILE
RCFILE指的是Record Columnar File,是一种高压缩率的二进制文件格式,被用于在一个时间点操作多行的场景。RCFILEs是由二进制键/值对组成的平面文件。RCFILE以记录的形式存储表中的列,即列存储方式。它先分割行做水平分区,然后分割列做垂直分区。RCFILE把一行的元数据作为键,把行数据作为值。这种面向列的存储在执行数据分析时更高效。
RCFILE格式的输入输出包是:
1 | org.apache.hadoop.hive.ql.io.RCFileInputFormat |
示例
1 | -- 建立RCFILE格式的表 |
d) ORCFILE
ORC指的是Optimized Record Columnar,即相对于其他文件格式,它以更优化的方式存储数据。ORC能将原始数据的大小缩减75%,从而提升了数据处理的速度。ORC比Text、Sequence和RC文件格式有更好的性能,而且ORC是目前Hive中唯一支持事务的文件格式。
ORCFILE格式的输入输出包是:
1 | org.apache.hadoop.hive.ql.io.orc |
示例
1 | -- 建立ORCFILE格式的表 |
e) 总结
应该依数据需求选择适当的文件格式:
- 如果数据有参数化的分隔符,那么可以选择TEXTFILE格式
- 如果数据所在文件比块尺寸小,可以选择SEQUENCEFILE格式
- 如果想执行数据分析,并高效地存储数据,可以选择RCFILE格式
- 如果希望减小数据所需的存储空间并提升性能,可以选择ORCFILE格式
3.2 法二:查询建表法(Create Table As Select (CTAS))
通过AS 查询语句完成建表:将子查询的结果存在新表里。一般用于中间表。
可以通过一个create-table-as-select(CTAS)语句中的查询结果来创建和填充表。 CTAS创建的表是原子表,这意味着在填充所有查询结果之前,其他用户不会看到该表。因此,其他用户要么看到包含完整查询结果的表,要么根本看不到表。
CTAS有两部分,SELECT部分可以是HiveQL支持的任何SELECT语句 (SELECT statement); CREATE部分从SELECT部分获取schema,并使用其他表属性(例如SerDe和存储格式)创建目标表。( The CREATE part of the CTAS takes the resulting schema from the SELECT part and creates the target table with other table properties such as the SerDe and storage format.)
CTAS具有以下限制:
目标表不能是外部表。
目标表不能是列表存储表 (list bucketing table)。
hive中用CTAS创建表,所创建的表统一都是非分区表,不管源表是否是分区表。所以对于分区表的创建使用CTAS一定要注意分区功能的丢失。当然创建表以后可以添加分区,成为分区表。(从Hive 3.2.0开始,CTAS语句可以为目标表定义分区规范 (HIVE-20241) ,示例如下:)
1
2CREATE TABLE partition_ctas_1 PARTITIONED BY (key) AS
SELECT value, key FROM src where key > 200 and key < 300;(关于如何查询hive版本,见 6.命令)
CTAS创建表时不能添加注释,这种方式多用于临时表、中间表的创建,不是结果表,且即使源表有注释,使用CTAS创建的表也会丢失源表的字段注释。
例:
1 | CREATE TABLE new_key_value_store |
上面的CTAS语句使用从SELECT语句结果得到的schema(new_key DOUBLE,key_value_pair STRING)创建目标表new_key_value_store。如果SELECT语句未指定列别名,则列名将自动分配给_col0,_col1和_col2等。此外,新目标表是使用特定的SerDe和存储格式创建的,独立于SELECT语句里的源表。
Starting with Hive 0.13.0, the SELECT statement can include one or more common table expressions (CTEs), as shown in the SELECT syntax. For an example, see Common Table Expression. (关于CTEs的介绍见 Common Table Expressions (CTE) - ndong - 博客园)
能够从一个表选择数据到另一个表是Hive最强大的特性之一。Hive在执行查询时处理数据从源格式到目标格式的转换。
根据例子我们建一张表:t3
1 | create table t3 as |
会执行MapReduce过程。 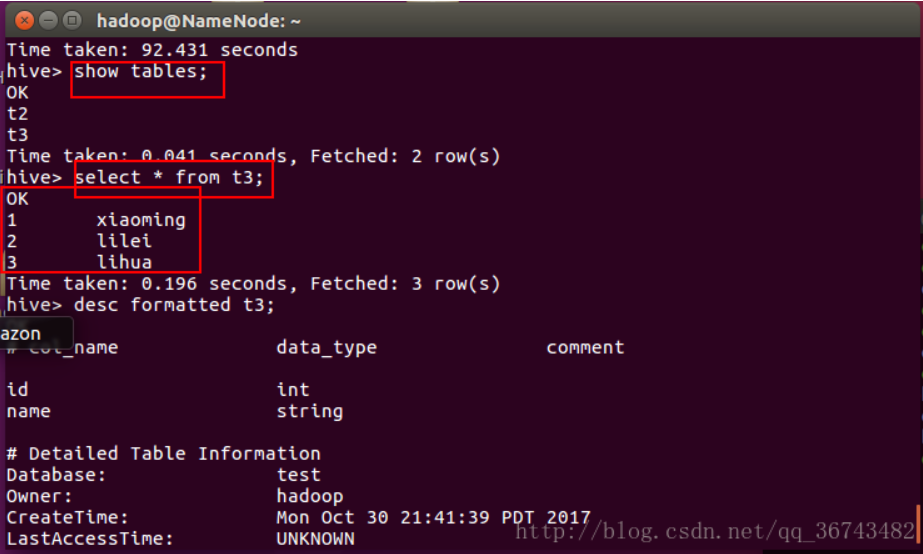
3.3 法三:like建表法
会创建结构完全相同的表,但是没有数据。常用于中间表。
(尝试过like建表法可以生成分区表)
LIKE形式的CREATE TABLE允许您精确地复制现有表定义(而无需复制其数据)。 与CTAS相比,以下语句创建了一个新的empty_key_value_store表,它的定义在表名以外的所有细节上与现有key_value_store完全匹配。 新表不包含任何行。
1 | CREATE TABLE empty_key_value_store LIKE key_value_store; |
在Hive 0.8.0之前,CREATE TABLE LIKE view_name将复制该视图。 在Hive 0.8.0和更高版本中,CREATE TABLE LIKE view_name通过使用view_name schema(字段(fields)和分区列(partition columns)), 使用SerDe和文件格式的默认值来创建一个表。
Syntax:
1 | CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name |
注:上面语句中如果不使用 EXTERNAL 关键字,若源表是外部表的话,生成的新表也将是外部表;若源表是内部表的话,生成的新表也将是内部表。若语句中包含 EXTERNAL 关键字且源表是内部表的话,生成的新表将是外部表。即使在这种场景下,LOCATION 子句同样是可选的。
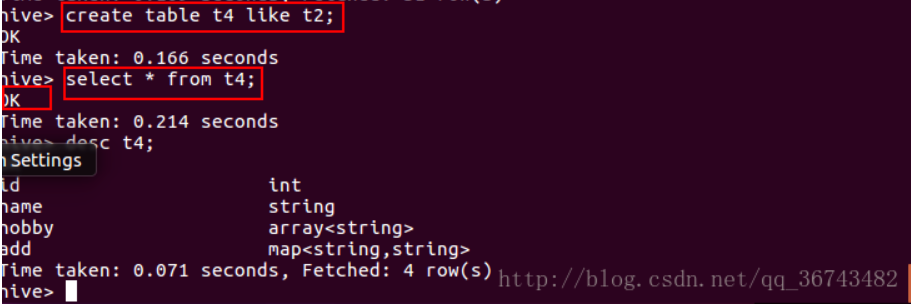
例子:
1 | create table t4 like t2; |
可以发现,不会执行MapReduce,且表结构和t2完全一样,但是没有数据

3.4 实例
1 | -- 建表方式一 |
4. Hive中表的类型
Hive中有5种表:内部表,外部表,临时表,分区表,桶表(分桶表)
4.1 内部表与外部表
参考 https://cwiki.apache.org/confluence/display/Hive/Managed+vs.+External+Tables
不使用 EXTERNAL 创建的表称为管理表 (也叫做内部表)
(managed
table),因为Hive管理它的数据。若要确定一个表是内部表还是外部表,使用 DESCRIBE
FORMATTED table_name 可以得到表的类型:
1 | Table Type: MANAGED_TABLE 或者 EXTERNAL_TABLE |
查看表的描述:
1 | DESCRIBE [EXTENDED|FORMATTED] table_name |
DESCRIBE显示列的列表(the list of columns),包括给定表的分区列(partition columns)。 如果指定了EXTENDED关键字,则它将以Thrift序列化形式显示表的所有元数据。 这通常只在调试时有用,而不适用于一般使用。 如果指定了FORMATTED关键字,则它将以表格格式显示元数据。
(注:使用FORMATTED会显示许多其他信息,例如表的创建人,创建时间,location等等)
默认情况下,Hive创建内部表,其中文件、元数据和统计信息由内部Hive进程管理 。
4.1.1 内部表(Managed Table)
A managed table is stored under the hive.metastore.warehouse.dir
path property, by default in a folder path similar to
/user/hive/warehouse/databasename.db/tablename/. The
default location can be overridden by the location property
during table creation. If a managed table or partition is dropped, the
data and metadata associated with that table or partition are deleted.
If the PURGE option is not specified, the data is moved to a trash
folder for a defined duration.
Use managed tables when Hive should manage the lifecycle of the table, or when generating temporary tables.
内部表的主要问题是只能用 Hive 访问,不方便和其他系统共享数据。例如,有一份由 Pig 或其他工具创建并且主要由这一工具使用的数据,同时希望使用 Hive 在这份数据上执行一些查询,可是并没有给予 Hive 对数据的所有权,这时就不能使用内部表了。我们可以创建一个外部表指向这份数据,而并不需要对其具有所有权。
删除内部表会同时删除存储数据和元数据。
4.1.2 外部表(External Table)
An external table describes the metadata/schema on external files. External table files can be accessed and managed by processes outside of Hive. External tables can access data stored in sources such as Azure Storage Volumes (ASV) or remote HDFS locations.
Use external tables when files are already present or in remote locations, and the files should remain even if the table is dropped.
外部表方便对已有数据的集成。因为表是外部的,所以 Hive 并不认为其完全拥有这个表的数据。在对外部表执行删除操作时,只是删除掉描述表的元数据信息,并不会删除表数据。
数据存储位置由用户自己指定,由HDFS管理,删除外部表时仅仅会删除元数据,存储数据不会受到影响。
- 适用情形: 当一份日志需要多个小组一起分析,分析完了之后创建的表就可以删除了。但是普通的表删除的同时也会把数据删除,这样就会影响到其他小组的分析,而且日志数据也不能随便删除。所以,需要外部表,删除外部表,不会删除对应的HDFS上的数据。
建表:
1 | create external table wc_external ( |
4.1.3 实例:创建内部表
如下:根据上述文件内容(见3.1.1 row format),创建一个表t1
1.创建表
1 | create table t1( |
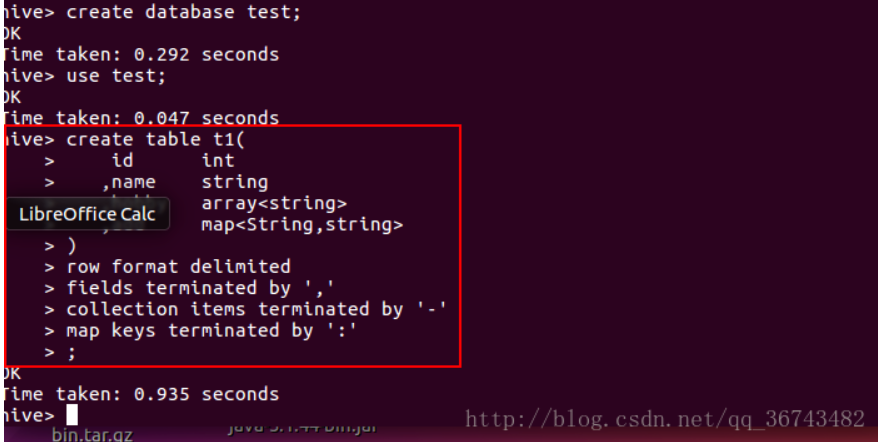
2.装载数据
1 | load data local inpath '/home/hadoop/Desktop/data' overwrite into table t1; |
(关于LOAD的详细介绍见5.2 Load)
查看表内容:
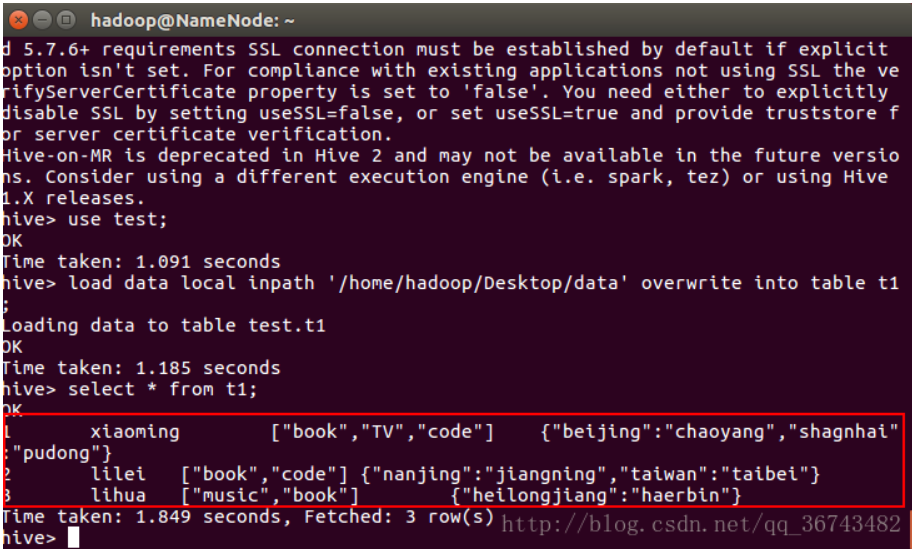
3.查看文件位
t1表在哪儿呢?在我们之前配置的默认路径里(/user/hive/warehouse)
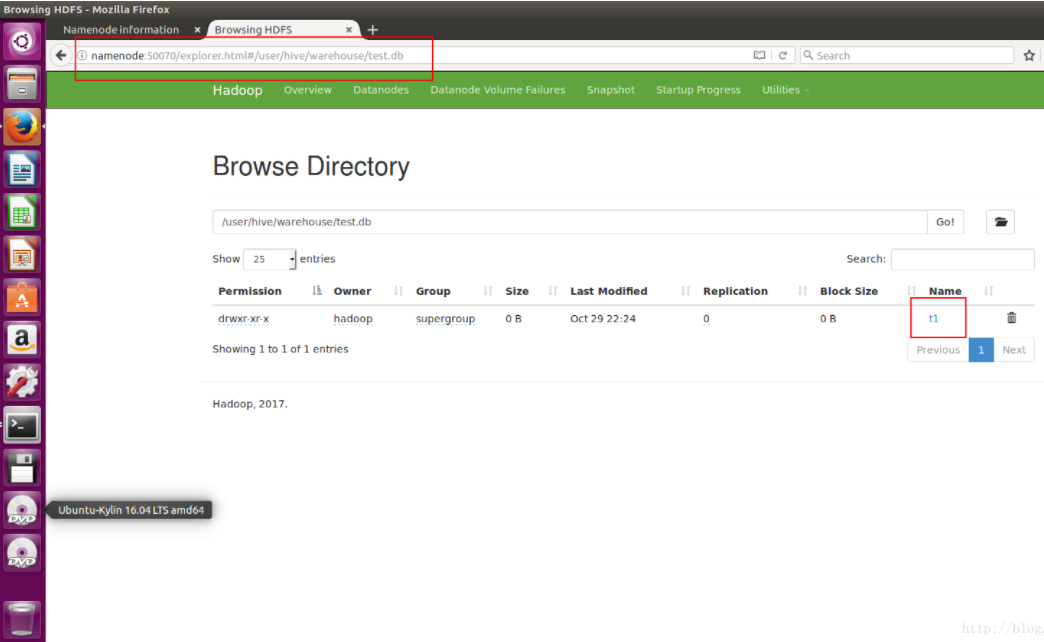
通过命令行获取位置信息
1 | desc formatted table_name; |
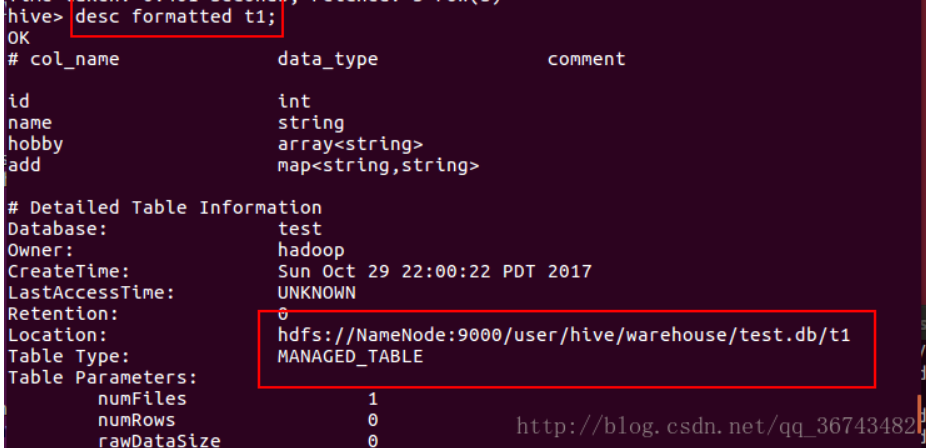
4.删除表


观察HDFS上的文件,t1已经不在了
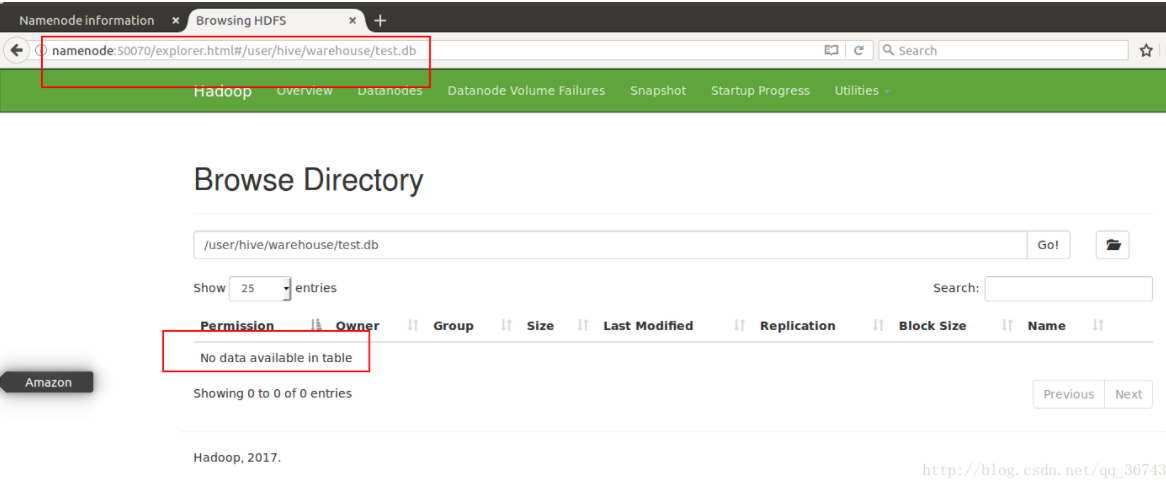
4.1.4 实例:创建外部表
1.创建表
1 | create external table t2( |
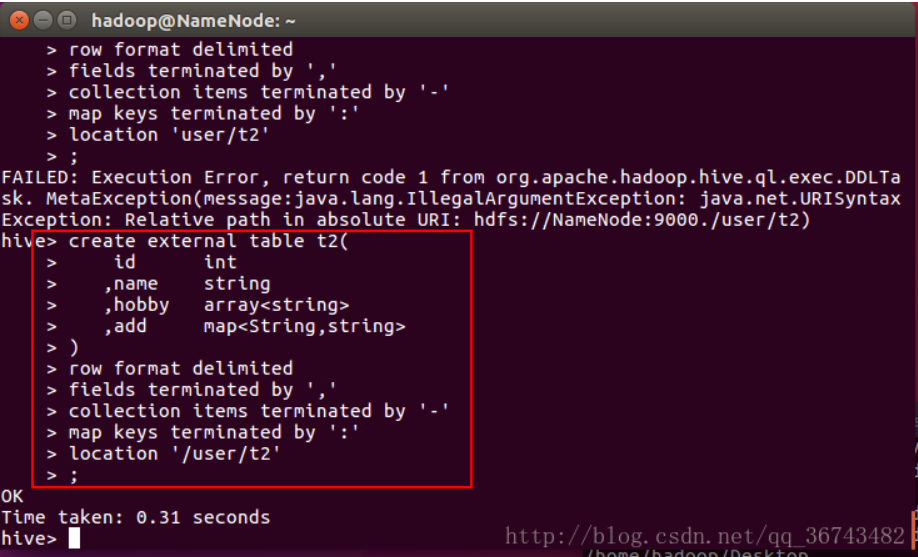
2.装载数据
1 | load data local inpath '/home/hadoop/Desktop/data' overwrite into table t2; |
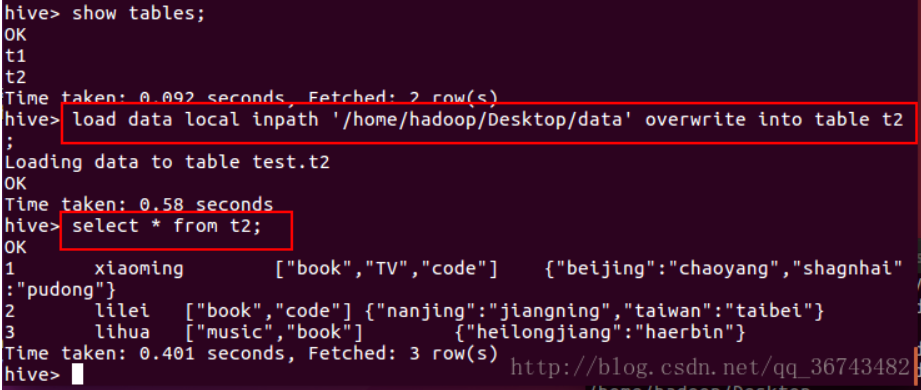
3.查看文件位置
在/user/目录下,可以看到t2文件
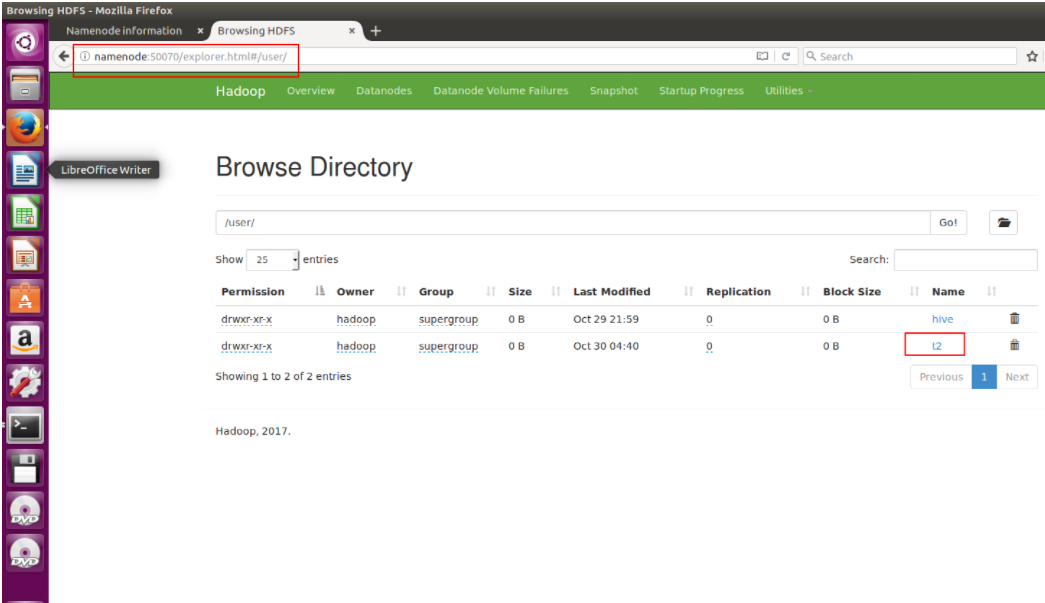
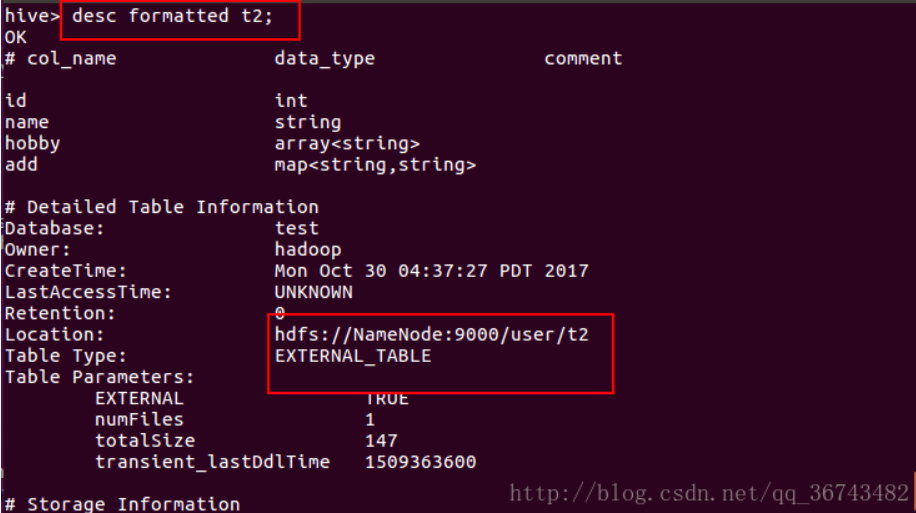
通过命令行获得位置信息
1 | desc formatted table_name; |
4.删除表


观察HDFS上的文件,t2仍然存在
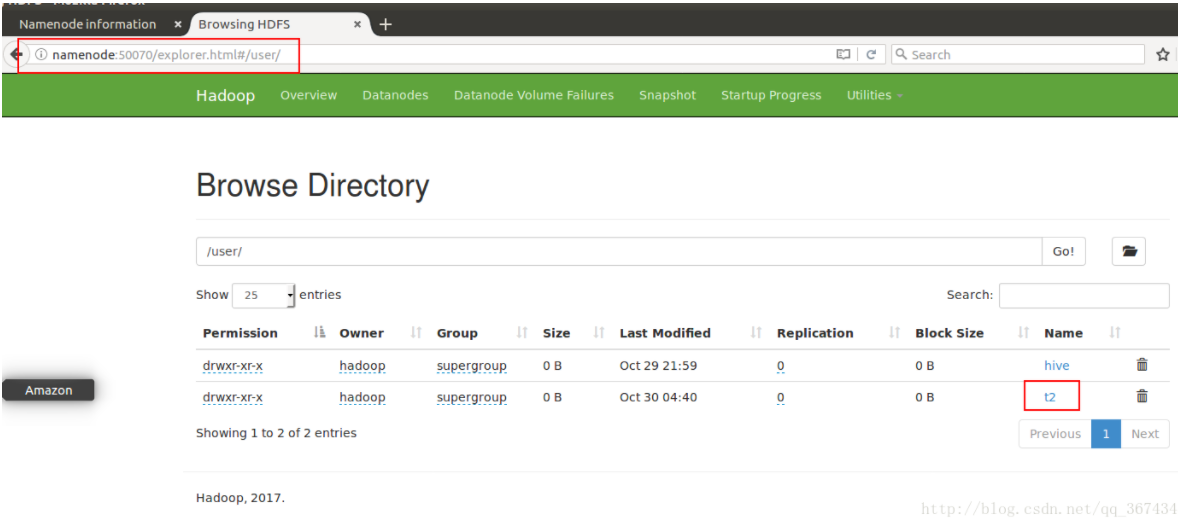
因而删除外部表仅仅会删除元数据。
重新创建外部表t2:
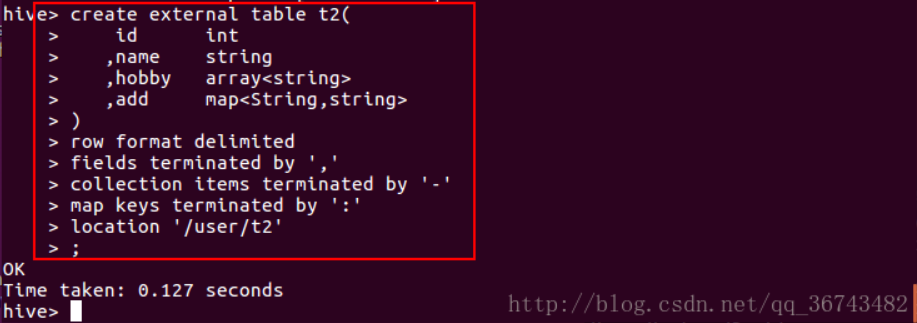
不往里面插入数据,我们select * 看看结果
可见数据仍然在!
4.1.5 内部表与外部表的区别
- 内部表数据由Hive自身管理,外部表数据由HDFS管理
- 内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己指定
- 对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name)
- 创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径, 不对数据的位置做任何改变
- 删除表时:在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据(HDFS上的文件不会被删除)。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据
- ARCHIVE/UNARCHIVE/TRUNCATE/MERGE/CONCATENATE only work for managed tables
- DROP deletes data for managed tables while it only deletes metadata for external ones
- ACID/Transactional only works for managed tables
- Query Results Caching only works for managed tables
- Only the RELY constraint is allowed on external tables
- Some Materialized View features only work on managed tables
4.2 临时表(Temporary Table)
在当前会话期间存在,会话结束后自动销毁。
- 适用情形 临时分析,在关闭hive客户端后,临时表就会消失。主要用于存储不重要的中间结果集,不重要的表。
临时表具有以下限制:
- 不支持分区列。
- 不支持创建索引。
建表:
1 | create TEMPORARY table ttabc( |
建表并加载数据:
1 | create TEMPORARY table dept_tmp( |
查看location信息:
1 | desc formatted dept_tmp; |
4.3 分区表(Partitioned Table)
可以使用 PARTITIONED BY 子句创建分区表。
一个表可以具有一个或多个分区列,并为分区列中的每个不同值组合创建一个单独的数据目录。
此外,可以使用 CLUSTERED BY
列对表或分区进行存储,并且可以通过 SORT BY
列在该存储区中对数据进行排序(tables or partitions can be bucketed using
CLUSTERED BY columns, and data can be sorted within that bucket via SORT
BY columns. )。 这样可以提高某些查询的性能。
更多关于bucket 的内容见 4.4 分桶表(Bucket Tables)
如果在创建分区表时收到以下错误消息:“ FAILED: Error in semantic analysis: Column repeated in partitioning columns”,则表示您试图将分区列包含在表本身的数据中。 您可能确实定义了该列,但是,您创建的分区将创建一个可查询的伪列,因此您必须将表列重命名为其他名称(用户不应在其上查询!)
(You probably really do have the column defined. However, the partition you create makes a pseudocolumn on which you can query, so you must rename your table column to something else (that users should not query on!))
例如,假设原始未分区表具有三列:id,date和name。
1 | id int, |
现在您要按日期分区。 您的Hive定义可以使用“ dtDontQuery”作为列名,以便可以将“ date”用于分区(和查询)。
1 | create table table_name ( |
现在,您的用户仍将查询where date ='...',但第二列dtDontQuery将保留原始值。
分区表将数据按照某个字段或者关键字分成多个子目录来存储,防止暴力扫描全表。
适用情形
1
select * from logs where date = '20171209'
- 普通表执行流程:对全表的数据进行查询,然后进行过滤操作。
- 分区表执行流程:直接加载对应文件路径下的数据。
适用于大数据量,可以通过分区快速定位需要查询的数据,分区表的作用主要是提高查询检索的效率
分区表的优势体现在可维护性和性能两方面,而且分区表还可以将数据以一种符合业务逻辑的方式进行组织,因此是数据仓库中经常使用的一种技术。内部表和外部表都可以创建相应的分区表,分别称之为内部分区表和外部分区表。
先看一个内部分区表的例子:
1 | CREATE TABLE page_view( |
CREATE TABLE 语句的 PARTITIONED BY
子句用于创建分区表。上面的语句创建一个名为 page_view
的分区表。这是一个常见的页面浏览记录表,包含浏览时间、浏览用户ID、浏览页面的URL、上一个访问的URL和用户的IP地址五个字段。该表以日期和国家作为分区字段,存储为SEQUENCEFILE文件格式。
使用 DESCRIBE FORMATTED 命令会显示出分区键。
1 | DESCRIBE FORMATTED page_view; |
输出信息中把表字段和分区字段分开显示。
分区表改变了 Hive 对数据存储的组织方式。如果是一个非分区表,那么只会有一个page_view目录与之对应,而对于分区表,当向表中装载数据后,Hive 将会创建好可以反映分区结构的子目录。
对数据进行分区,最重要的原因就是为了更快地查询。如果用户的查询包含了
where dt='...' and country='...'
这样的条件,查询优化器只需要扫描一个分区目录即可。
静态分区表:
1 | create table day_hour_table ( |
加载数据:
1 | -- insert单条插入的方式往分区表中插入数据: |
删除Hive分区表中的分区:
1 | ALTER TABLE day_table DROP PARTITION (dt=10,hour=10); |
创建/添加分区:
Syntax:
1 | ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location'] |
1 | -- 创建一个空分区: |
动态分区表:
动态分区表和静态分区表建表语句相同,插入数据的方式不同。
1 | set hive.exec.dynamic.partition=true; |
动态分区可以根据数据本身的特征自动来划分分区,load data …
只是将数据上传到HDFS指定目录,所以我们需要使用from
insert的方式插入数据,hive才会根据分区设置自动将数据进行分区。
(详细内容见: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML#LanguageManualDML-DynamicPartitionInserts)
4.4 分桶表(Bucked Tables)
将数据按照某个字段和桶的数量,对指定字段进行取模运算,拆分成多个小文件来存储,模相同的存储在同一个小文件中,提高join以及抽样的效率。
- 适用情形 数据有严重的数据倾斜,分布不均匀,但是相对来说每个桶中的数据量会比较平均。桶与桶之间做join等查询的时候,会有优化。
1 | set hive.enforce.bucketing=true; |
分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储,由列值的哈希值除以桶的个数来决定每条数据划分在哪个桶中。对于hive中每一个表、分区都可以进一步进行分桶。
For an int, it's easy, hash_int(i) == i.
例如基于user_id进行分桶时, if user_id were an int, and there were 10
buckets, we would expect all user_id's that end in 0 to be in bucket 1,
all user_id's that end in a 1 to be in bucket 2, etc.
建表:
1 | CREATE TABLE psnbucket( |
插入数据:
1 | insert into table psnbucket select id, name, age from original; |
分桶表+分区表:
1 | CREATE TABLE psnbucket_partition( |
参考 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL+BucketedTables
Bucketed tables are fantastic in that they allow much more efficient sampling than do non-bucketed tables, and they may later allow for time saving operations such as mapside joins. However, the bucketing specified at table creation is not enforced when the table is written to, and so it is possible for the table's metadata to advertise properties which are not upheld by the table's actual layout. This should obviously be avoided. Here's how to do it right.
First, table creation:
1 | CREATE TABLE user_info_bucketed(user_id BIGINT, firstname STRING, lastname STRING) |
Note that we specify a column (user_id) to base the bucketing. Then we populate the table
1 | set hive.enforce.bucketing = true; -- (Note: Not needed in Hive 2.x onward) |
Version 0.x and 1.x only The command
set hive.enforce.bucketing = true;allows the correct number of reducers and the cluster by column to be automatically selected based on the table. Otherwise, you would need to set the number of reducers to be the same as the number of buckets as inset mapred.reduce.tasks = 256;and have aCLUSTER BY ...clause in the select.
What can go wrong? As long as you use the syntax above and
set hive.enforce.bucketing = true (for Hive 0.x and 1.x),
the tables should be populated properly. Things can go wrong if the
bucketing column type is different during the insert and on read, or if
you manually cluster by a value that's different from the table
definition.
Bucketed Sorted Tables
参考 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-TemporaryTables
例:
1 | CREATE TABLE page_view( |
In the example above, the page_view table is bucketed (clustered by) userid and within each bucket the data is sorted in increasing order of viewTime. Such an organization allows the user to do efficient sampling on the clustered column - in this case userid. The sorting property allows internal operators to take advantage of the better-known data structure while evaluating queries, also increasing efficiency. MAP KEYS and COLLECTION ITEMS keywords can be used if any of the columns are lists or maps.
CLUSTERED BY和SORTED BY创建命令不会影响将数据插入表的方式,而只会影响数据的读取方式。 这意味着用户必须注意正确地插入数据,方法是将reducer的数量指定为等于存储桶的数量,并在查询中使用CLUSTER BY和SORT BY命令。
5. 向Hive表中插入数据
5.1 Insert
5.1.1 INSERT INTO/OVERWRITE TABLE SELECT
参考 LanguageManual DML - Apache Hive - Apache Software Foundation
Inserting data into Hive Tables from queries. 此种方式适合把Hive表里的数据插入另一张Hive表。
Syntax
1 | Standard syntax: |
解释:
INSERT OVERWRITE将覆盖表或分区中的任何现有数据- unless
IF NOT EXISTSis provided for a partition (as of Hive 0.9.0). - As of Hive 2.3.0 (HIVE-15880), if the table has TBLPROPERTIES ("auto.purge"="true") the previous data of the table is not moved to Trash when INSERT OVERWRITE query is run against the table. This functionality is applicable only for managed tables (see managed tables) and is turned off when "auto.purge" property is unset or set to false.
- unless
INSERT INTO将追加到表或分区,保持现有数据不变- As of Hive 0.13.0, a table can be made immutable by creating it with TBLPROPERTIES ("immutable"="true"). The default is "immutable"="false". 如果表中已经存在任何数据,则不允许在不可变表中执行INSERT INTO行为,但如果不可变表为空,则插入INTO仍然可以工作。 INSERT OVERWRITE 的行为不受“不可变”表属性的影响。 不可变表可以防止由于脚本错误地多次运行而将数据加载到表中的意外更新。The first insert into an immutable table succeeds and successive inserts fail, resulting in only one set of data in the table, instead of silently succeeding with multiple copies of the data in the table.
- 可以对表或分区进行插入。如果表是分区表,则必须通过指定所有分区列的值来指定一个特定的分区. If hive.typecheck.on.insert is set to true, these values are validated, converted and normalized to conform to their column types (Hive 0.12.0 onward).
- 可以在同一查询中指定多个插入子句(也称为多表插入)。
- The output of each of the select statements is written to the chosen table (or partition). Currently the OVERWRITE keyword is mandatory and implies that the contents of the chosen table or partition are replaced with the output of corresponding select statement.
- The output format and serialization class is determined by the table's metadata (as specified via DDL commands on the table).
- As of Hive 1.1.0 the TABLE keyword is optional.
- As of Hive 1.2.0 each INSERT INTO T can take a column list like INSERT INTO T (z, x, c1). See Description of HIVE-9481 for examples.
Notes
- Multi Table Inserts minimize the number of data scans required. Hive can insert data into multiple tables by scanning the input data just once (and applying different query operators to the input data). 多表插入可最大程度地减少所需的数据扫描次数。 Hive可以通过只扫描一次输入数据(并应用不同的查询运算符到输入数据)来将数据插入到多个表中。
- Starting with Hive 0.13.0, the select statement can include one or more common table expressions (CTEs) as shown in the SELECT syntax. For an example, see Common Table Expression.
例1:
1 | insert into rest select count(*) from tableA; |
例2:
1 | create table if not exists dwd_base.dwd_user_info_df( |
5.1.2 INSERT INTO ... VALUES
参考 LanguageManual DML - Apache Hive - Apache Software Foundation
Inserting values into tables from SQL. 此种方式适合将具体数值(少量)插入到Hive表。
Syntax:
1 | Standard Syntax: |
解释:
- VALUES 子句中列出的每一行都会被插入到表中(插入多行数据可以写到一个insert into语句中)
- 表中的每一列都需提供需要插入的值。允许用户只向某些列插入值的标准SQL语法目前还不支持。为了模拟标准SQL,用户不希望赋值的列可以提供null。
- 使用 INSERT INTO ... VALUES 语句不支持 complex datatypes (array, map, struct, union)
例1:
1 | CREATE TABLE students ( |
例2:
1 | CREATE TABLE pageviews ( |
5.2 Load
参考 LanguageManual DML - Apache Hive - Apache Software Foundation
Loading files into tables. 此种方式适合把文件中的数据插入Hive表
Syntax:
1 | LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] |
解释:
Hive 3.0之前的加载操作是纯复制/移动操作,将数据文件移动到与Hive表相对应的位置
- filepath 可以是:
- 相对路径, 如 project/data1
- 绝对路径, 如 /user/hive/project/data1
- a full URI with scheme and (optionally) an authority, such as hdfs://namenode:9000/user/hive/project/data1
- The target being loaded to can be a table or a partition. If the table is partitioned, then one must specify a specific partition of the table by specifying values for all of the partitioning columns.
- filepath 可以指向文件(在这种情况下,Hive会将文件移至表中),也可以是目录(在这种情况下,Hive会将目录中的所有文件移至表中)。 In either case, filepath addresses a set of files.
- 如果指定了关键字 LOCAL,则
- load命令将在本地文件系统中查找文件路径。
如果指定的是相对路径,它将相对于用户的当前工作目录进行解释。
用户也可以为本地文件指定完整的URI - for example:
file:///user/hive/project/data1 - the load command will try to copy all the files addressed by filepath to the target filesystem. The target file system is inferred by looking at the location attribute of the table. The copied data files will then be moved to the table.
- 如果要装载的文件在服务器上,使用LOCAL;如果在HDFS中,不使用LOCAL。(如果使用了关键字LOCAL,filepath would be referred from the server where hive beeline is running otherwise it would use the HDFS path.)
- load命令将在本地文件系统中查找文件路径。
如果指定的是相对路径,它将相对于用户的当前工作目录进行解释。
用户也可以为本地文件指定完整的URI - for example:
- 如果未指定关键字
LOCAL,则Hive将使用文件路径的完整URI(如果已指定),或将应用以下规则:
- If scheme or authority are not specified, Hive will use the scheme
and authority from the hadoop configuration variable
fs.default.namethat specifies the Namenode URI. - If the path is not absolute, then Hive will interpret it relative to
/user/<username> - Hive will move the files addressed by filepath into the table (or partition)
- If scheme or authority are not specified, Hive will use the scheme
and authority from the hadoop configuration variable
- 如果使用了 OVERWRITE 关键字,目标表(或分区)中的内容将会被删掉并被替换为filepath指向的文件; 否则,filepath指向的文件将被追加到表中。
例:将HDFS中的文件导入分区表
1 | LOAD DATA INPATH '/user/kelly/test-ml/20210901predict_result.csv' OVERWRITE INTO TABLE 'ads_base.xxxx' partition(dt=20210901) |
5.2.1 向非分区表中装载数据
(1)使用 LOAD ... INTO
先准备一个本地文本文件 a.txt,其中只有一行记录 'aaa'.
1 | >mkdir test |
将这行记录装载到一个表中,并查看HDFS上生成的数据文件
1 | hive> use test; |
可以看到,hive命令行中除了可以执行HiveQL语句,还可以执行Hadoop的dfs命令。Load语句实际执行了一个复制文件的操作。通常我们在load语句中指定的路径是一个目录,而不是单个独立的文件。Hive会将该目录下的所有文件都复制到目标位置。这使得用户将更方便地组织数据到多个文件中,同时可以在不修改Hive脚本的前提下修改文件命名规则。文件会被复制到目标路径下而且文件名保持不变。
上面的HiveQL语句向t1表中装载了数据'aaa',并在默认的数据仓库目录下生成了数据文件 /user/hive/warehouse/test.db/t1/a.txt,实际上数据文件是纯文本格式,内容就是 'aaa'。
在本地文件a.txt中添加一行'bbb'。
1 | echo 'bbb' >> a.txt |
然后再执行下面的HiveQL语句并查看结果:
1 | hive> load data local inpath '/root/test' into table t1; |
可以看到,现在表中有3条数据,并且新生成了数据文件a_copy_1.txt。原来的a.txt文件中的内容还是'aaa',新生成的a_copy_1.txt文件中的内容是第二次装载的两行数据。即,每次装载会生成一个新的文件,如果目录中装载的文件已经存在,那么再次装载会生成一个原文件的复制,表中数据对应的是表目录下的所有文件的内容。
(2)使用 LOAD ... OVERWRITE INTO
1 | hive> drop table if exists t2; |
可以看到,现在t2表中只有两条数据,在表目录下生成了数据文件a.txt。现在编辑本地文件a.txt,使其只有一行'ccc'。
1 | echo 'ccc' > a.txt |
再执行下面的语句:
1 | hive> load data local inpath '/root/test' overwrite into table t2; |
可以看到,现在表中只有一条数据'ccc',数据文件名没变,但其内容重新生成。
5.2.2 向分区表中装载数据
(1)LOAD
准备本地文本文件a.txt,其中只有一行'aaa',然后执行下面的语句:
1 | hive> create table t1(name string) partitioned by (country string, state string); |
可以看到,建立t1表后,装载数据前,表目录下没有任何文件。load语句创建了分区目录country=us/state=ca,并将本地文件复制到分区目录下。从查询的角度看,向t1表中装载了数据'aaa'。查询结果显示了三列,除了原始的文本文件中的数据,还包括了两个分区列的值。分区列总是在表的最后显示。
load overwrite装载数据与非分区表类似,不再赘述。
(2)ALTER table tablename add partition
1 | hive> alter table t1 add partition(country='us', state='cb') location '/a'; |
说明:表中原有一条数据'aaa'。添加一个新分区,并指定位置为'/a'。把已经存在的数据文件a.txt复制到目录'/a'里。此时查询已经有属于不同分区的两条数据。删除country='us'且state='ca'分区的数据文件。此时查询表只有属于country='us'且state='cb'分区的一条数据。整个过程中HDFS中都没有存在过coutry=us/state=cb的目录。
5.2.3 对Hive表的数据装载特性总结
- load与load overwrite的区别是:
- load:每次执行会生成新的数据文件,文件中是本次装载的数据,表中数据对应的是表目录下的所有文件的内容。
- load overwrite:若表(或分区)的数据文件不存在则生成,存在则重新生成数据文件内容(覆盖掉以前的)。
- 分区表比非分区表多了一种alter table ... add partition的数据装载方式
- 对于分区表(无论内部还是外部),load与load overwrite会自动建立名为分区键值的目录,而alter table ... add partition,只要用location指定数据文件所在的目录即可。
- 对于外部表,除了在删除表时只删除元数据而保留表数据目录外,其数据装载行为与内部表相同。
实例1:将CSV文件导入Hive表
(1)首先需创建hive表:
1 | CREATE TABLE IF NOT EXISTS emp.employee ( |
注: 为了将csv文件导入Hive表, 建表时需要使用
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',',并且不能加上stored as ORC,否则
load 时会报错,文件格式不匹配
(2)使用 rz 命令将电脑本地文件上传至服务器
注:先关闭本地文件,再
rz,且文件中不要包含header,否则会被一起导入表中
(3)将服务器上的文件上传至HDFS
1 | 登录hive |
(4)将HDFS中的csv导入Hive表
1 | hive>LOAD DATA INPATH '/user/kelly/data/data.csv' OVERWRITE INTO TABLE emp.employee; |
使用
overwrite,会删掉目标表里已有的数据,并导入文件中的数据
使用 select * from emp.employee 查看是否写入成功。
注:对于LOAD DATA INAPTH:LOAD 后,HDFS中的源数据会被删掉
法二:跳过步骤(3),直接将服务器(即local filesystem)上的csv导入Hive表
Use LOCAL optional clause to load CSV file from the
local filesystem into the Hive table without uploading to HDFS.
1 | hive>LOAD DATA LOCAL INPATH '/data/test/data.csv' OVERWRITE INTO TABLE emp.employee; |
注:对于LOAD DATA LOCAL INAPTH:local file system 中的源数据不会被删掉。
另:使用 partition
如果目标表是分区表,使用 partition
将数据导入特定的分区中。并且可使用 overwrite
覆盖该分区(删掉原有的数据并装载现在的数据)
1 | hive>LOAD DATA INPATH '/user/kelly/data/data.csv' OVERWRITE INTO TABLE emp.employee PARTITION(date=2020); |
实例2:将hive表内容导出为csv
hive表的内容实际是存在hdfs上的,可以直接导出到服务器本地:
read_data.sh
1 |
|
可指定分隔符为逗号:ROW FORMAT DELIMITED FIELDS TERMINATED BY ',',但若字段中的内容含有逗号,则需使用其他分隔符,例如
'\u0000'。
更多关于分隔符的内容见 Hive应用:选取分隔符
注:sed s/,/\t/g 意思是将所有逗号替换为选项
i 使 sed 修改文件
6. 命令
这里的命令指非sql语句,例如设置属性或添加资源。它们可以在HiveQL脚本中使用,也可以直接在CLI或Beeline中使用。
如何查看hive版本:
在安装了hive的服务器上运行:
1 | hive --version |
Hive shell 中:
1 | hive>quit; |
Linux命令行中:
参考 https://blog.csdn.net/weixin_42073408/article/details/120483485
不进入 hive shell , 直接在linux命令行界面执行hive命令,可使用
hive -e
1 | $hive -e 'select * from test_table' |
增加 -S
选项可以开启静默模式,这样可以输出结果中去掉‘OK’,'Time Taken’等行,
1 | $hive -S -e 'select * from test_table' |
使用 -f 执行文件中的查询语句:
1 | $hive -f /tem/myquery.hql |
在 hive shell 中可以使用 source
命令执行文件中的查询语句:
1 | hive>source /tem/myquery.hql |