索引Index

MySQL官方文档:https://dev.mysql.com/doc/refman/8.0/en/innodb-indexes.html MySQL Tutorial:https://www.tutorialspoint.com/mysql/index.htm
快速导航
CREATE TABLE 官方手册 CREATE INDEX 官方手册 ALTER TABLE 官方手册 使用explain查看是否使用索引 索引组织表 主键索引(聚簇索引,聚集索引)、非主键索引(普通索引,二级索引,非聚簇索引) 覆盖索引 最左前缀 索引下推
第一部分:MySQL中索引的操作
参考: https://www.tutorialspoint.com/mysql/mysql-indexes https://www.runoob.com/mysql/mysql-index.html https://dev.mysql.com/doc/refman/5.6/en/create-table.html#create-table-indexes-keys
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
用户看不到索引,它们仅用于加速查询,并且数据库搜索引擎将使用它们非常快速地定位记录。
对于具有索引的表,INSERT和UPDATE语句会花费更多的时间,而SELECT语句会变得更快。原因是在执行插入或更新时,数据库还需要插入或更新索引值。
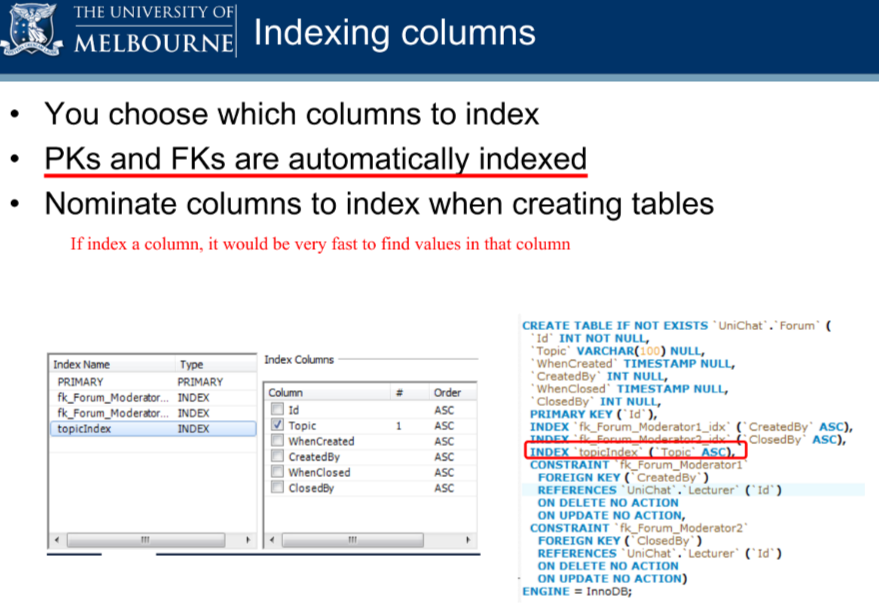
1. MySQL建表语句中关于索引的keywords
PRIMAY KEYA unique index where all key columns must be defined asNOT NULL. If they are not explicitly declared asNOT NULL, MySQL declares them so implicitly (and silently). 一个表只能有一个主键. 主键的key_name始终是PRIMARY, 所以其他类型的索引不能使用PRIMARY作为索引名.If you do not have a
PRIMARY KEYand an application asks for thePRIMARY KEYin your tables, MySQL returns the firstUNIQUEindex that has noNULLcolumns as thePRIMARY KEY.In
InnoDBtables, keep thePRIMARY KEYshort to minimize storage overhead for secondary indexes. Each secondary index entry contains a copy of the primary key columns for the corresponding row. (See Section 14.6.2.1, “Clustered and Secondary Indexes”.)In the created table, a
PRIMARY KEYis placed first, followed by allUNIQUEindexes, and then the nonunique indexes. This helps the MySQL optimizer to prioritize which index to use and also more quickly to detect duplicatedUNIQUEkeys.A
PRIMARY KEYcan be a multiple-column index. 建表时创建一个复合主键:PRIMARY KEY(key_part, ...).In MySQL, the name of a
PRIMARY KEYisPRIMARY. For other indexes, if you do not assign a name, the index is assigned the same name as the first indexed column, with an optional suffix (_2,_3,...) to make it unique. 查看表有哪些索引:SHOW INDEX FROM tbl_name. See Section 13.7.5.23, “SHOW INDEX Statement”. (使用show create table tbl_name也能看到有哪些索引)(例如上图中,主键是
id,索引名为PRIMARY,还添加了索引:Topic,索引名为topicIndex)KEY | INDEXKEYis normally a synonym forINDEX(同义词). The key attributePRIMARY KEYcan also be specified as justKEYwhen given in a column definition. This was implemented for compatibility with other database systems.(通常创建索引的时候可以用
KEY也可以用INDEX,但如果是创建主键等具有约束性质的,不能用INDEX,具体区别见 https://blog.csdn.net/kusedexingfu/article/details/78347354 )1
2
3ALTER TABLE index_test ADD KEY key_1(staff_id);
或
ALTER TABLE index_test ADD INDEX index_1(staff_id);UNIQUEAUNIQUEindex creates a constraint such that all values in the index must be distinct. An error occurs if you try to add a new row with a key value that matches an existing row. For all engines, aUNIQUEindex permits multipleNULLvalues for columns that can containNULL. If you specify a prefix value for a column in aUNIQUEindex, the column values must be unique within the prefix length.FULLTEXTAFULLTEXTindex is a special type of index used for full-text searches. Only theInnoDBandMyISAMstorage engines supportFULLTEXTindexes. They can be created only fromCHAR,VARCHAR, andTEXTcolumns. See Section 12.10, “Full-Text Search Functions”, for details of operation.
还有 SPATIAL, FOREIGN KEY 等的介绍见 https://dev.mysql.com/doc/refman/5.6/en/create-table.html#create-table-indexes-keys.
2. CREATE [UNIQUE] INDEX 创建普通索引(简单索引)与唯一索引
唯一索引意味着索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。 普通索引没有任何限制,它允许表中有重复值。
下面是在表上创建索引的语法(可以使用一个或多个列来创建索引):
1 | CREATE [UNIQUE] INDEX index_name ON table_name (column1, column2,...); |
1 | CREATE [ONLINE | OFFLINE] [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name |
例:
1 | -- create an index on tutorials_tbl using tutorial_author. |
对于普通索引,只需从上述statement中省略UNIQUE关键字即可。
如果希望按降序索引列中的值,可以在列名后添加保留字DESC。
1 | mysql> CREATE UNIQUE INDEX AUTHOR_INDEX ON tutorials_tbl (tutorial_author DESC) |
注:CREATE INDEX 不能用来创建 PRIMARY KEY. Use ALTER TABLE
instead. CREATE INDEX
is mapped to an ALTER TABLE
statement to create indexes. See Section
13.1.7, “ALTER TABLE Statement”.
3. 使用 ALTER 命令添加和删除索引
3.1 添加索引
1 | ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) |
更多关于 alter table 的语法见 https://dev.mysql.com/doc/refman/5.6/en/alter-table.html
示例:在现有表中添加索引
1 | mysql> ALTER TABLE testalter_tbl ADD INDEX (c); |
注:当用 create index 创建索引时,必须指定索引的名字,否则mysql会报错;用 ALTER TABLE 创建索引时,可以不指定索引名字,若不指定mysql会自动生成索引名字。
3.2 删除索引
可以在 ALTER 命令中使用 DROP 子句来删除索引。
1 | ALTER TABLE tbl_name DROP PRIMARY KEY; |
尝试以下示例来删除上面创建的索引。
1 | mysql> ALTER TABLE testalter_tbl DROP INDEX (c); |
3.3 使用 ALTER 命令添加和删除主键
可以以相同的方式添加主键,但要先确保该column(s)不含NULL。下面的代码是在现有表中添加主键。首先使列不为NULL,然后将其添加为主键。
1 | mysql> ALTER TABLE testalter_tbl MODIFY i INT NOT NULL; |
也可以使用 ALTER 命令删除主键:
1 | mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY; |
删除主键时只需指定 PRIMARY KEY,但在删除不是 PRIMARY KEY
的索引时,必须指定索引名。
4. 创建表时直接指定索引
普通索引:
1 | CREATE TABLE mytable( |
唯一索引:
1 | CREATE TABLE mytable( |
主键索引:
1 | CREATE TABLE mytable( |
例:
1 | create table T ( |
5. 使用 DROP 命令删除索引
1 | DROP INDEX [indexName] ON mytable; |
6. 显示索引信息
6.1 show index
可以使用 SHOW INDEX 命令列出与表关联的所有索引。可以通过添加 行垂直格式输出,以避免长行换行。
1 | mysql> SHOW INDEX FROM table_name\G |
6.2 可用explain来查看查询是否使用索引
参考 https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
执行计划(有时称解释计划或查询计划)显示数据库执行SQL语句所采取的步骤。
explain 结果中 key
代表使用的索引名称,若为NULL,则未使用索引。
6.2.1 explain 输出列
| Column | Meaning |
|---|---|
id |
The SELECT identifier |
select_type |
The SELECT type |
table |
The table for the output row |
partitions |
The matching partitions |
type |
The join type |
possible_keys |
The possible indexes to choose |
key |
The index actually chosen |
key_len |
The length of the chosen key |
ref |
The columns compared to the index |
rows |
Estimate of rows to be examined |
filtered |
Percentage of rows filtered by table condition |
Extra |
Additional information |
6.2.2 示例(关于 type 与 extra)
例如:现有表city2如下:
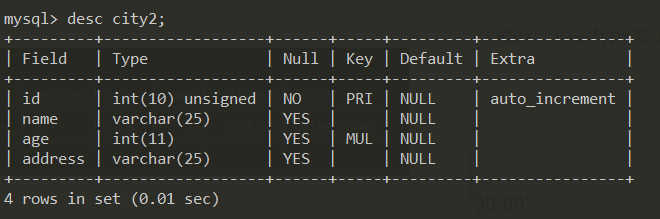
city2上的索引如下图所示:(id为主键,(age,name)联合索引)

查询1:
1 | explain select name,age from city2 where age=20\G |
查询内容在索引内,where 条件为索引最左列
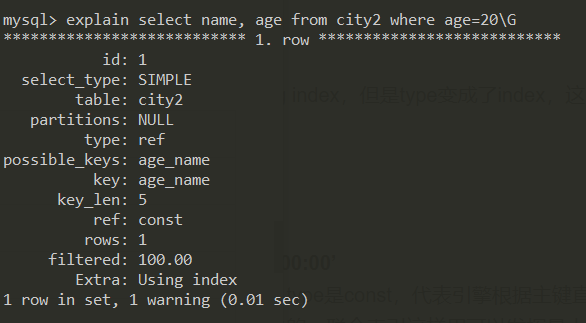
👆 type 是 ref,表明用到了索引(ref 与 Oracle 中的 INDEX RANGE SCAN 意思一样,因为索引列不是 unique 的,还需要 follow the leaf nodes in order to find all matching entries),extra 是 using index,表示索引覆盖了.(即不用回表)
查询2:
1 | explain select name, age from city2 where name='bob'\G |
查询内容在索引内,where条件为索引第二列,这次不是最左列了
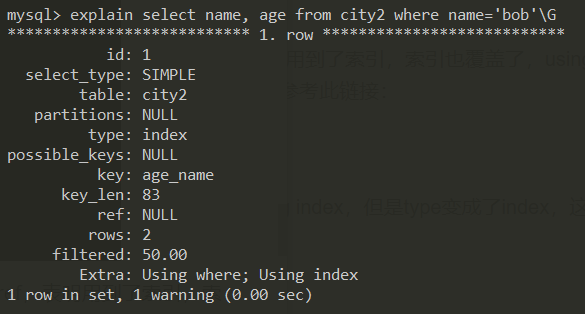
👆 type 是 index,表明发生了索引扫描(因为where条件不是最左列的缘故),extra 是 using where; using index(using index代表索引覆盖了,不用回表,using where代表发生了过滤),
查询3:
1 | explain select address from city2 where age=20\G |
查询内容不在索引内,where 条件为索引最左列
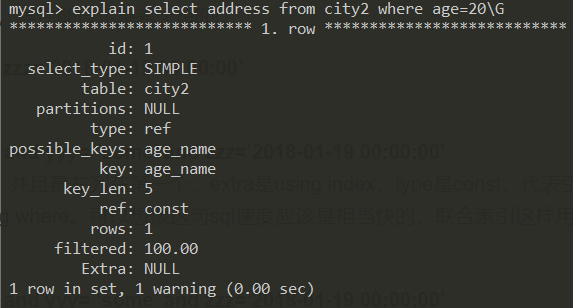
👆 extra 是 NULL,type 是 ref,表明虽然用到了索引,但是没有索引覆盖,产生了回表。
查询4:
1 | explain select address from city2 where name='bob'\G |
查询内容不在索引范围内,where条件为索引第二列
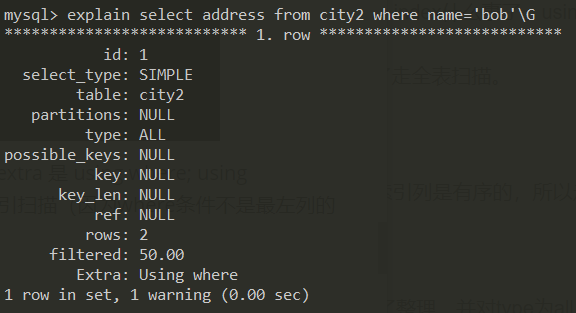
👆 type 是 all,代表全表扫描(将每一行与where条件进行比较,执行时间随表的大小增长),extra 是 using where 说明在全表扫描后发生了过滤。(走全表扫描的原因是查询内容不在索引范围内,且where条件没有最左列,所以引擎选择了走全表扫描。)
查询5:
1 | explain select name from city2 where id=xxx |
👆 此时,type为 const(只遍历索引树,因为是通过主键查询,保证了数据的唯一性,不用再搜索叶子节点,速度很快,几乎与表的大小无关),extra 为 NULL。
更多例子见 https://blog.csdn.net/jeffrey11223/article/details/79100761
6.2.3 EXPLAIN Join Types
explain中type的解释
The type column of EXPLAIN
output describes how tables are joined. The following list describes the
join types, ordered from the best type to the worst:
下面只列出了部分
systemThe table has only one row (= system table). This is a special case of theconstjoin type.constThe table has at most one matching row, which is read at the start of the query. Because there is only one row, values from the column in this row can be regarded as constants by the rest of the optimizer.consttables are very fast because they are read only once.constis used when you compare all parts of aPRIMARY KEYorUNIQUEindex to constant values. In the following queries, tbl_name can be used as aconsttable:1
2
3
4
5SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name
WHERE primary_key_part1=1
AND primary_key_part2=2;1
2
3
4
5
6
7
8
9
10
11
12
13
14
- [`ref`](https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#jointype_ref)
All rows with matching index values are read from this table for each combination of rows from the previous tables. [`ref`](https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#jointype_ref) is used if the join uses only a leftmost prefix of the key or if the key is not a `PRIMARY KEY` or `UNIQUE` index (in other words, if the join cannot select a single row based on the key value). If the key that is used matches only a few rows, this is a good join type.
[`ref`](https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#jointype_ref) can be used for indexed columns that are compared using the `=` or `<=>` operator. In the following examples, MySQL can use a [`ref`](https://dev.mysql.com/doc/refman/8.0/en/explain-output.html#jointype_ref) join to process *ref_table*:
```sql
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;indexTheindexjoin type is the same asALL, except that the index tree is scanned. This occurs two ways:- If the index is a covering index for the queries and can be used to
satisfy all data required from the table, only the index tree is
scanned. In this case, the
Extracolumn saysUsing index. An index-only scan usually is faster thanALLbecause the size of the index usually is smaller than the table data. - A full table scan is performed using reads from the index to look up
data rows in index order.
Uses indexdoes not appear in theExtracolumn.
MySQL can use this join type when the query uses only columns that are part of a single index.
- If the index is a covering index for the queries and can be used to
satisfy all data required from the table, only the index tree is
scanned. In this case, the
ALLA full table scan is done for each combination of rows from the previous tables. This is normally not good if the table is the first table not marked const, and usually very bad in all other cases. Normally, you can avoid ALL by adding indexes that enable row retrieval from the table based on constant values or column values from earlier tables.
6.2.4 EXPLAIN Extra Information
explian中extra的解释
If you want to make your queries as fast as possible, look out for
Extra column values of Using filesort and
Using temporary.
下面只列出了一部分:
Distinct(JSON property:distinct) MySQL is looking for distinct values, so it stops searching for more rows for the current row combination after it has found the first matching row.Full scan on NULL key(JSON property:message) This occurs for subquery optimization as a fallback strategy when the optimizer cannot use an index-lookup access method.Using filesort(JSON property:using_filesort) MySQL must do an extra pass to find out how to retrieve the rows in sorted order. The sort is done by going through all rows according to the join type and storing the sort key and pointer to the row for all rows that match theWHEREclause. The keys then are sorted and the rows are retrieved in sorted order. See Section 8.2.1.16, “ORDER BY Optimization”.Using index(JSON property:using_index) The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index. ForInnoDBtables that have a user-defined clustered index, that index can be used even whenUsing indexis absent from theExtracolumn. This is the case iftypeisindexandkeyisPRIMARY.Using index condition(JSON property:using_index_condition) Tables are read by accessing index tuples and testing them first to determine whether to read full table rows. In this way, index information is used to defer (“push down”) reading full table rows unless it is necessary. See Section 8.2.1.6, “Index Condition Pushdown Optimization”.Using temporary(JSON property:using_temporary_table) To resolve the query, MySQL needs to create a temporary table to hold the result. This typically happens if the query containsGROUP BYandORDER BYclauses that list columns differently.Using where(JSON property:attached_condition) AWHEREclause is used to restrict which rows to match against the next table or send to the client. Unless you specifically intend to fetch or examine all rows from the table, you may have something wrong in your query if theExtravalue is notUsing whereand the table join type isALLorindex.
Tables are read by accessing index tuples and testing them first to determine whether to read full table rows. In this way, index information is used to defer (“push down”) reading full table rows unless it is necessary. See Section 8.2.1.6, “Index Condition Pushdown Optimization”.
7. 什么时候该使用索引
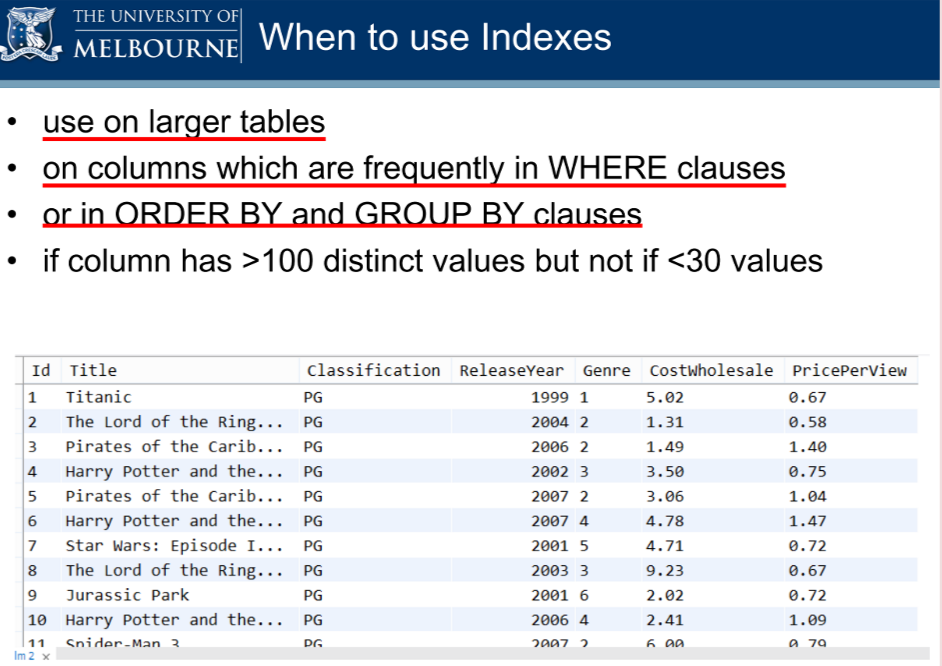
8. 什么时候不该使用索引
索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行 INSERT、UPDATE 和 DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。

第二部分:索引的常见模型
参考 https://time.geekbang.org/column/article/69236
索引的常见模型:哈希表、有序数组和搜索树。
例如,现在维护着一个身份证信息和姓名的表,需要根据身份证号查找对应的名字。
1. 哈希表
哈希索引的示意图如下:
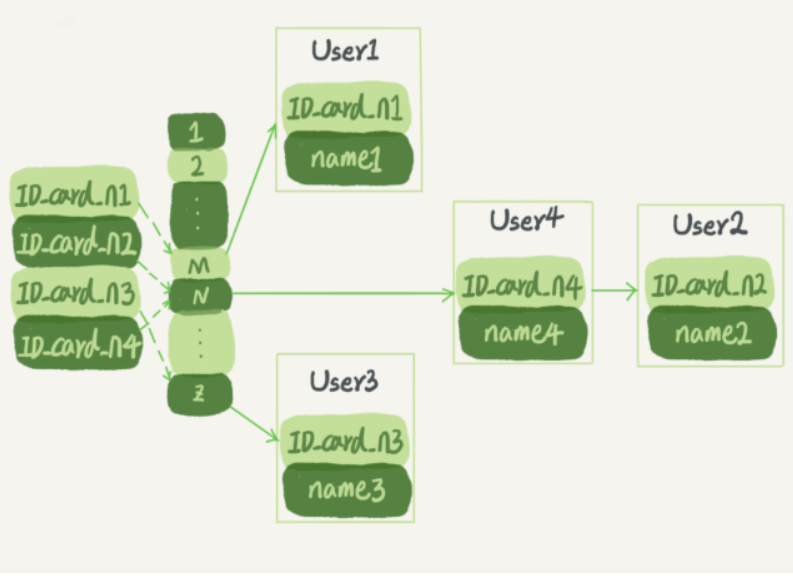
从上图可以看到,四个ID_card_n的值并不是递增的(即并不是身份证号越大,算出来的N越大)
优点:增加新的数据时,只需往后追加。
缺点:因为不是有序的,所以哈希索引做区间查询的速度是很慢的。例如查找身份证号在[ID_card_X, ID_card_Y]区间的所有用户,就必须全部扫描一遍了。
哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。
2. 有序数组
优点:有序数组在等值查询和范围查询场景中的性能都非常优秀。
还是上面这个根据身份证号查名字的例子,如果我们使用有序数组来实现的话,示意图如下所示:
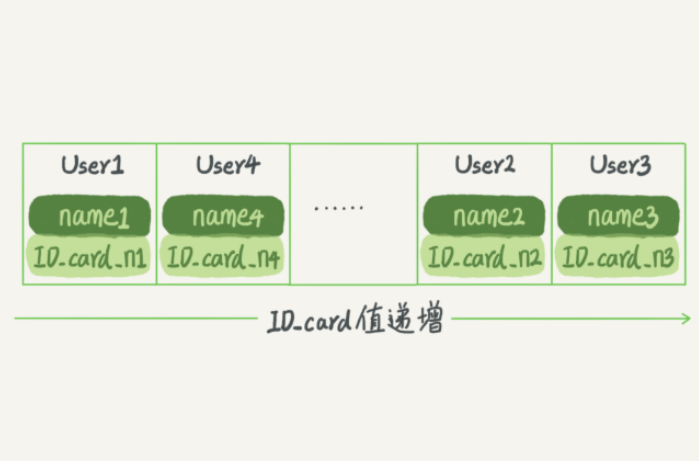
查找身份证号对应的名字,用二分法可以快速得到,时间复杂度 O(log(N))。
同时很显然,这个索引结构支持范围查询。若要查身份证号在 [ID_card_X, ID_card_Y] 区间的 User, 可以先二分法找到 ID_card_x(如果不存在 ID_card_X,就找到大于 ID_card_X 的第一个 user),然后向右谝历,直到查到第一个大于 ID_card_Y 的身份证号,退出循环。
缺点:如果仅仅看查询效率,有序数组就是最好的数据结构了。但是,在需要更新数据的时候就麻烦了,你往中间插入一个记录就它须得挪动后面所有的记录,成本太高。
所以,有序数组索引只适用于静态存储引擎,比如你要保存的是2017年某个城市的所有人囗信息,这类不会再修改的数据。
3. 搜索树
还是上面根据身份证号查名字的例子,如果我们用二叉搜索树来实现的话,示意图如下所示:
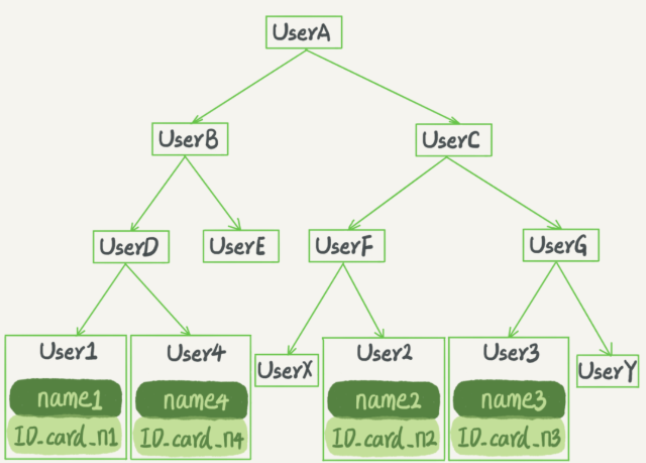
二叉搜索树的特点是:每个节点的左儿子小于父节点,父节点又小于右儿子。这样如果你要查 ID_card_n2 的话,按照图中的搜索顺序就是按照 UserA -> UserC -> UserF -> User2 这个路径得到。这个时间复杂度杂度是O(log(N))。
当然为了维持 O(Iog(N)) 的查询复杂度,需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是O(log(N))。
树可以有二叉,也可以有多叉。多叉树就是每个节点有多个儿子,儿子之间的大小保证从左到右递增。二叉树是搜索效率最高的,但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上。
想象一下一棵100万节点的平衡二叉树,树高20。一次查询可能需要访问20个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要10ms左右的寻址时间。也就是说,对于一个100万行的表,如果使用二叉树来存储,单独访问一个行可能需要20个10ms的时间,这个查询可真够慢的。
为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。那么,我们就不应该使用二叉树,而是要使用“N 叉”树。这里,“N 叉”树中的“N”取决于数据块的大小。
以 InnoDB 的一个整数字段索引为例,这个 N 差不多是 1200。这棵树高是 4 的时候,就可以存 1200 的 3 次方个值,这已经 17 亿了。考虑到树根的数据块总是在内存中的,一个 10 亿行的表上一个整数字段的索引,查找一个值最多只需要访问 3 次磁盘。其实,树的第二层也有很大概率在内存中,那么访问磁盘的平均次数就更少了。
N 叉树由于在读写上的性能优点,以及适配磁盘的访问模式,已经被广泛应用在数据库引擎中了。
N叉树的N值,在 MySQL 5.6 以后可以通过调整 page(数据页)大小间接控制 (page 指的 InnoDB的页,默认大小16K)
3.1 The Index Leaf Node 索引叶子节点
索引的主要目的是为 indexed data 提供有序表示。然而不可能按顺序存储数据,因为插入语句需要移动 the following entries来为新条目腾出空间。移动大量数据非常耗时,因此插入语句将非常缓慢。解决这个问题的方法是在内存中建立一个独立于物理顺序的逻辑顺序。
逻辑顺序是通过一个双链表(doubly linked list)建立的。每个节点都有指向两个相邻 entries 的 links。通过更新两个现有节点的链接指向新节点,来插入新节点。新节点的物理位置并不重要,因为双链表维护了逻辑顺序。
双链表的结构使得数据库能够根据需要向前或向后读取索引。这样就可以在不移动大量数据的情况下插入新条目——只需要改变一些指针。
数据库使用双链表来连接所谓的索引叶节点(index leaf nodes)。每个叶节点存储在一个数据库块或页中,即数据库的最小存储单元。所有索引块的大小相同,通常是 a few kilobytes。数据库尽可能地利用每个块中的空间,并在每个块中存储尽可能多的索引条目。这意味着索引的顺序在两个不同的 level 上维护着:每个叶节点内的索引条目,以及使用双链表连接的叶节点(the index entries within each leaf node, and the leaf nodes among each other using a doubly linked list)。
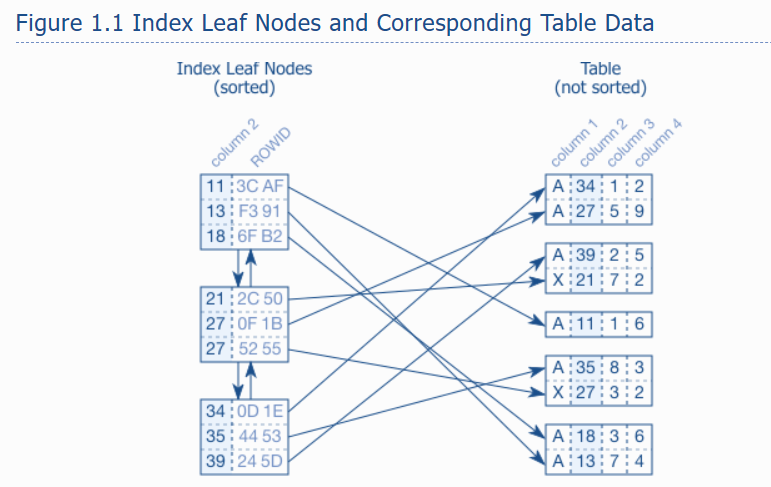
图1.1 展示了索引叶节点及其与表数据的联系。每个索引项由 index columns (the key, column 2) 组成,并 refer to 相应的表行(通过 ROWID 或 RID )。与索引不同,表数据存储在堆结构中,根本不排序,存储在同一个 table block 中的行之间没有任何关系,blocks 之间也没有任何联系。
3.2 搜索树 (B-Tree) 使索引更快
The index leaf nodes 以任意顺序存储,磁盘上的位置与根据索引顺序的逻辑位置并不是对应的。它就像一个打乱了页面的电话簿。如果你搜索 Smith,但首先打开Robinson 的目录,这绝不意味着 Sminth 跟在 Robinson 后面。数据库需要第二种结构来快速地在打乱的页面中找到条目:简而言之就是平衡的搜索树:b树。
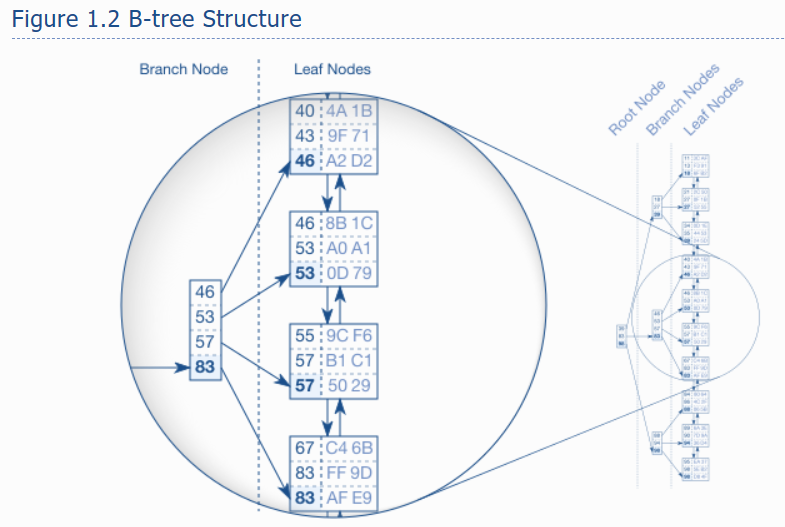
图1.2 展示了一个包含30个条目的示例索引。双链表建立了叶节点之间的逻辑顺序。根节点和分支节点支持在叶节点之间快速搜索。
该图突出显示了一个分支节点和它所指向的叶节点。每个分支节点条目对应于各自叶节点中的最大值。以第一个叶子节点为例,该节点的最大值为46,因此存储在相应的分支节点 entry 中。对于其他叶节点也是如此,因此最终分支节点的值为 46、53、57和83。根据这个机制,一个分支层被建立起来,直到所有叶节点都被分支节点覆盖。
The next layer is built similarly, but on top of the first branch node level. 这个过程不断重复,直到 all keys fit into a single node, the root node。这个结构是一个平衡搜索树,因为树的深度在每个位置都是相等的;根节点和叶节点之间的距离在任何地方都是一样的。
A B-tree is a balanced tree—not a binary tree.
创建索引后,数据库将自动维护索引。它将每次插入、删除和更新应用于索引,并保持树的平衡,从而导致写操作的维护开销。
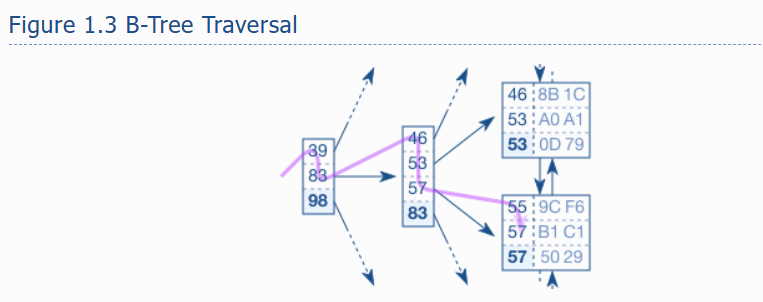
图1.3 展示了一个索引片段,用于演示对 key 57 的搜索。树遍历从左侧的根节点开始。每个条目按升序处理,直到一个值大于等于搜索项(57)。在图中,它是条目83。The database follows the reference to the corresponding branch node ,并重复该过程,直到树遍历到达叶节点。
The B-tree enables the database to find a leaf node quickly.
树遍历是一个非常高效的操作。这主要是因为树的平衡,which allows accessing all elements with the same number of steps,其次是因为树的深度呈对数增长。这意味着与叶节点的数量相比,树的深度增长得非常慢。 Real world indexes with millions of records have a tree depth of four or five. A tree depth of six is hardly ever seen.
3.3 slow index 慢索引
尽管树遍历效率很高,但仍然存在索引查找不如预期快的情况。
导致索引查找缓慢的第一个因素是叶节点链(the leaf node chain)。以图1.3中对 57 的搜索为例,显然,索引中有两个匹配的项。更准确地说,至少有两个条目是相同的,下一个叶节点可能有更多的57。数据库必须读取下一个叶节点,以查看是否有更多匹配条目。这意味着索引查找不仅需要执行树遍历,还需要遵循叶节点链。
导致索引查找缓慢的第二个因素是访问表(accessing the table)。即使是单个叶节点也可能包含许多命中,通常是数百个。相应的表数据通常分散在许多表块中(参见图1.1)。这意味着每次命中都有一个额外的表访问。
索引查找需要三个步骤:
(1)遍历树; (2)沿叶节点链; (3)获取表数据。
树遍历是唯一具有访问块数上限的步骤(索引深度)。另外两个步骤可能需要访问许多 blocks,它们会导致索引查找缓慢。
第三部分:InnoDB的索引模型
参考 https://time.geekbang.org/column/article/69236
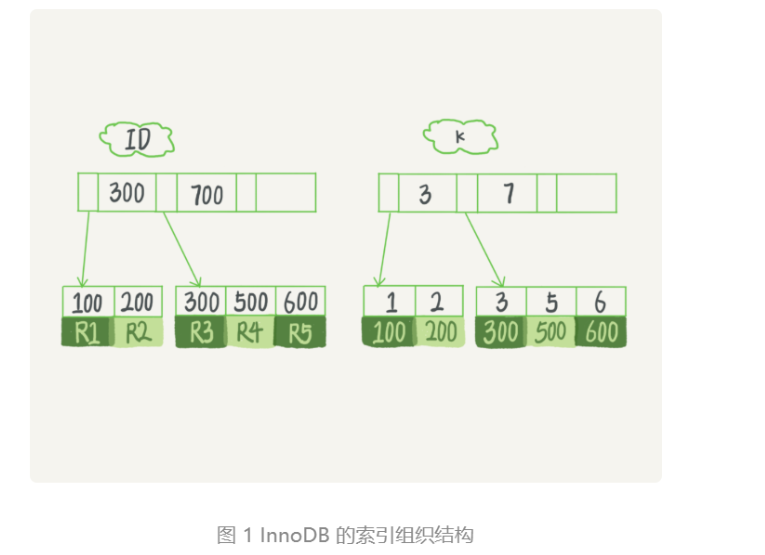
1. InnoDB索引组织结构
在 MySQL 中,索引是在存储引擎层实现的,所以并没有统一的索引标准,即不同存储引擎的索引的工作方式并不一样。而即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不同。由于 InnoDB 存储引擎在 MySQL 数据库中使用最为广泛,所以下面以 InnoDB 为例,分析一下其中的索引模型。
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。
每一个索引在 InnoDB 里面对应一棵 B+ 树。
假设,我们有一个主键列为ID的表,表中有字段 k,并且在k上有索引。这个表的建表语句是:
1 | mysql>create table T( |
表中R1-R5的 (ID,k) 值分别为(100, 1)、(200, 2)、(300,3)、(500,5) 和 (600, 6),
| id | k | name |
|---|---|---|
| 100 | 1 | ... |
| 200 | 2 | ... |
| 300 | 3 | ... |
| 500 | 5 | ... |
| 600 | 6 | ... |
两棵树的示例示意图如下。
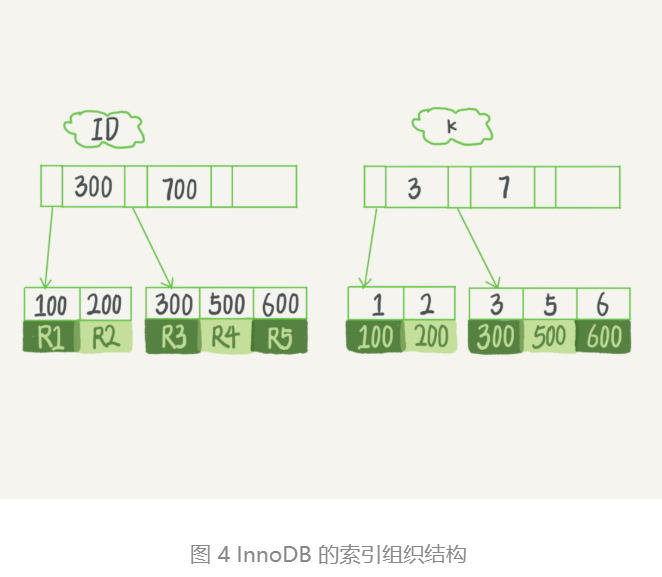
👆 R1代表的是一行,左边是主键索引,右边是非主键索引。
innoDB B+树的叶子节点是 page (页),一个页里面可以存多个行 索引只能定位到 page,page内部怎么去定位行数据:page内部有个有序数组,二分法
从图中不难看出,根据叶子节点的内容,索引类型分为主键索引和非主键索引(也叫普通索引)。 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
根据上面的索引结构说明,我们来讨论一个问题:基于主键索引和普通索引的查询有什么区别?
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
2. 聚簇索引与二级索引
2.1 聚簇索引(也称主键索引,聚集索引,clustered index)
参考 https://www.cnblogs.com/jiawen010/p/11805241.html
InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分。一张表只有一个聚簇索引。
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体细节依赖于其实现方式。
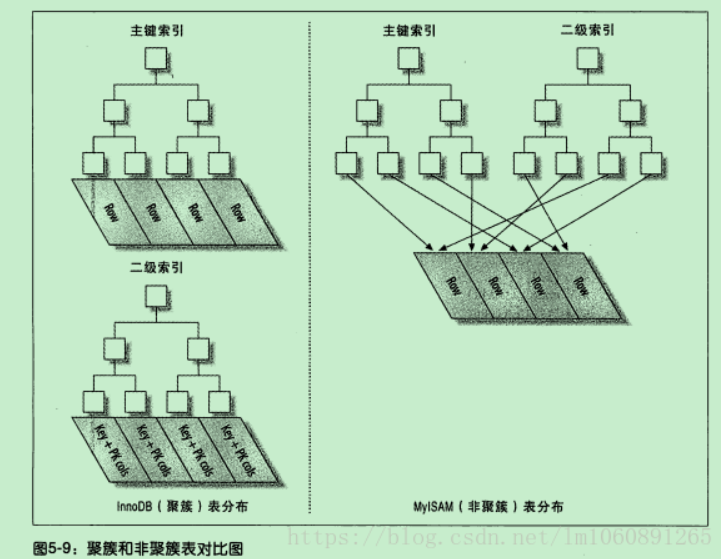
MySQL数据库中innodb存储引擎,B+树索引可以分为聚簇索引(也称聚集索引,clustered index)和辅助索引(有时也称非聚簇索引或二级索引,secondary index,non-clustered index)。这两种索引内部都是B+树,聚集索引的叶子节点存放着一整行的数据。
Innobd中的主键索引是一种聚簇索引,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引。
Innodb使用的是聚簇索引,MyISam使用的是非聚簇索引。 MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
问:主键索引是聚集索引还是非聚集索引? 在Innodb下主键索引是聚集索引,在Myisam下主键索引是非聚集索引
Innodb通过主键聚集数据,如果没有定义主键,innodb会选择非空的唯一索引代替。如果没有这样的索引,innodb会隐式的定义一个主键来作为聚簇索引。
聚簇索引的优缺点:
优点:
- 数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
- 聚簇索引对于主键的排序查找和范围查找速度非常快
缺点:
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
- 二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
2.2 辅助索引(也称非聚簇索引,二级索引,非主键索引,普通索引,secondary index)
参考 https://www.cnblogs.com/jiawen010/p/11805241.html
在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找。辅助索引叶子节点存储的不再是行的物理位置,而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页,再通过数据页中的Page Directory找到数据行。
Innodb辅助索引的叶子节点并不包含行记录的全部数据,叶子节点除了包含键值外,还包含了相应行数据的聚簇索引键。(见上图图4)
辅助索引的存在不影响数据在聚簇索引中的组织,所以一张表可以有多个辅助索引。在innodb中有时也称辅助索引为二级索引。
辅助索引会包含主键列,所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义很多索引,则争取尽量把主键定义得小一些。InnoDB 不会压缩索引。
In
InnoDBtables, keep thePRIMARY KEYshort to minimize storage overhead for secondary indexes. Each secondary index entry contains a copy of the primary key columns for the corresponding row. (See Section 14.6.2.1, “Clustered and Secondary Indexes”.)(来自 https://dev.mysql.com/doc/refman/5.6/en/create-table.html)
2.3 小结
参考 https://www.cnblogs.com/jiawen010/p/11805241.html
- 为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
- 用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
聚簇索引和非聚簇索引的区别:
- 聚簇索引的叶子节点存放的是主键值和数据行,支持覆盖索引;二级索引的叶子节点存放的是主键值或指向数据行的指针。
- 由于叶子节点(数据页)只能按照一颗B+树排序,故一张表只能有一个聚簇索引。辅助索引的存在不影响聚簇索引中数据的组织,所以一张表可以有多个辅助索引
注: 覆盖索引(covering index)指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。也可以称之为实现了索引覆盖。 当一条查询语句符合覆盖索引条件时,MySQL只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作,减少I/O提高效率。 如,表covering_index_sample中有一个普通索引 idx_key1_key2(key1,key2)。当我们通过SQL语句:select key2 from covering_index_sample where key1 = ‘keytest’;的时候,就可以通过覆盖索引查询,无需回表。(关于覆盖索引更详细内容见第四部分:覆盖索引)
3. 索引维护
B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面图4为例,如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
而更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。
当然有分裂就有合并。当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
4. 关于自增主键
你可能在一些建表规范里面见到过类似的描述,要求建表语句里一定要有自增主键。当然事无绝对,我们来分析一下哪些场景下应该使用自增主键,而哪些场景下不应该。
自增主键是指自增列上定义的主键,在建表浯句中一般是这么定义的:NOT NULL PRIMARY KEY AUTO INCREMENT。
插入新记录的时候可以不指定ID的值,系统会获取当前ID最大值加1作为下一条记录的ID值。
也就是说,自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。而用业务逻辑的字段做主键,则往往不容易保证有序插入,这样写数据成本相对较高。
除了考虑性能外,我们还可以从存储空间的角度来看。假设你的表中确实有一个唯一字段,比如字符串类型的身份证号,那应该用身份证号做主键,还是用自增字段做主键呢?
由于每个非主键索引的叶子节点上都是主键的值,如果用身份证号做主键,那么每个二级索引的叶子节点占用约20个字节,而如果用整型做主键,则只要4个字节,如果是长整型(bigint)则是8个字节。
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。所以,从性能和存储空间方面考量,自增主键往往是更合理的选择。
有没有什么场景适合用业务字段直接做主键的呢?还是有的。比如,有些业务的场景需求是这样的:
- 只有一个索引;
- 该索引必须是唯一索引。
这就是典型的KV(key-value)场景,由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。 这时候我们就要优先考虑上一段提到的"尽量使用主键查询"原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
5. 小结
B+ 树能够很好地配合磁盘的读写特性,减少单次查询的磁盘访问次数。
由于 InnoDB 是索引组织表,一般情况下建议创建一个自增主键,这样非主键索引占用的空间最小。
对于上面例子中的 InnoDB 表 T,如果你要重建索引 k,你的两个 SQL 语句可以这么写:
1 | alter table T drop index k; |
如果你要重建主键索引,也可以这么写:
1 | alter table T drop primary key; |
问:对于上面这两个重建索引的做法,有没有不合适的?
注:为什么要重建索引? 前面提到,索引可能因为删除,或者页分裂等原因,导致数据页有空洞,重建索引的过程会创建一个新的索引,把数据按顺序插入,这样页面的利用率最高,也就是索引更紧凑、更省空间。
答案:重建索引 k
的做法是合理的,可以达到省空间的目的。但是,重建主键的过程不合理。
1.直接删掉主键索引,会使得所有二级索引都失效,并且会用ROWID来做主键索引。
2.不论是删除主键还是创建主键,都会将整个表重建。所以连着执行这两个语句的话,第一个语句就白做了。这两个语句,你可以用这个语句代替
:alter table T engine=InnoDB。👈原地重建表结构
第四部分:覆盖索引
参考 https://time.geekbang.org/column/article/69636
在下面这个表T中,如果执行
select * from T where k between 3 and 5,需要执行几次树的搜索操作,会扫描多少行?
表的初始化语句:
1 | create table T ( |
这条SQL查询语句的执行流程:
- 在k索引树上找到 k=3 的记录,取得 ID=300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500;
- 再回到 ID 索引树查到 ID=500对应的R4;
- 在 k 索引树取下一个值 k=6,不满足条件,循环结束。
在这个过程中,回到主键索引树搜索的过程,我们称为回表。可以看到,这个查询过程读了 k 索引树的 3 条记录(步骤 1、3 和 5),回表了两次(步骤 2 和 4)。
在这个例子中,由于查询结果所需要的数据只在主键索引上有,所以不得不回表。那么,有没有可能经过索引优化,避免回表过程呢?
如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
需要注意的是,在引擎内部使用覆盖索引在索引k上其实读了三个记录,R3~R5(对应的索引k上的记录项),但是对于MySQL的 Server 层来说,它就是找引擎拿到了两条记录,因此 MySQL 认为扫描行数是2。
基于上面覆盖索引的说明,我们来讨论一个问题:在一个市民信息表,是否有必要将身份证号和名字建立联合索引?
假设这个市民表的定义是这样的:
1 | CREATE TABLE `tuser` ( |
我们知道,身份证号是市民的唯一标识。也就是说,如果有根据身份证号查询市民信息的需求,我们只要在身份证号字段上建立索引就够了。而再建立一个(身份证号,姓名)的联合索引,是不是浪费空间?如果现在有一个高频请求,要根据市民的身份证号查询他的姓名,这个联合索引就有意义了。它可以在这个高频请求上用到覆盖索引,不再需要回表查整行记录,减少语句的执行时间。
当然,索引字段的维护总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了。这正是业务 DBA,或者称为业务数据架构师的工作。
第五部分:最左前缀原则
参考 https://time.geekbang.org/column/article/69636
如果为每一种查询都设计一个索引,索引是不是太多了。如果现在要按照市民的身份证号取查他的家庭地址呢?虽然这个查询需求在业务中出现的概率不高,但总不能让它走全表扫描吧?反过来说,单独为一个不频繁的请求创建一个(身份证号,地址)的索引又感觉有点浪费。应该怎么做呢?
1. 最左前缀
B+树这种索引结构,可以利用索引的”最左前缀“,来定位记录。
用(name, age)这个联合索引来分析:
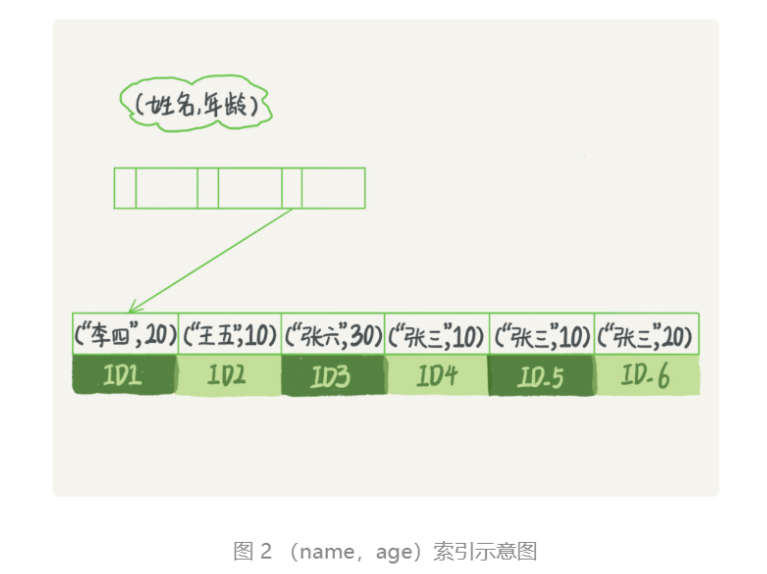
可以看到,索引项是按照索引定义里面出现的字段顺序排序的。→ 即先按name排序,再按age排序
当你的逻辑需求是查到所有名字是“张三”的人时,可以快速定位到 ID4,然后向后遍历得到所有需要的结果。
如果你要查的是所有名字第一个字是“张”的人,你的 SQL
语句的条件是where name like ‘张%’。这时,你也能够用上这个索引,查找到第一个符合条件的记录是
ID3,然后向后遍历,直到不满足条件为止。
可以看到,不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
基于上面对最左前缀索引的说明,我们来讨论一个问题:在建立联合索引的时候,如何安排索引内的字段顺序。
这里我们的评估标准是,索引的复用能力。因为可以支持最左前缀,所以当已经有了 (a,b) 这个联合索引后,一般就不需要单独在 a 上建立索引了。因此,第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。
The most important consideration when defining a concatenated index is how to choose the column order so it can be used as often as possible.
In general, a database can use a concatenated index when searching with the leading (leftmost) columns. An index with three columns can be used when searching for the first column, when searching with the first two columns together, and when searching using all columns.
所以现在你知道了,这段开头的问题里,我们要为高频请求创建 (身份证号,姓名)这个联合索引,并用这个索引支持“根据身份证号查询地址”的需求。
那么,如果既有联合查询,又有基于 a、b 各自的查询呢?查询条件里面只有 b 的语句,是无法使用 (a,b) 这个联合索引的( a two-column index does not support searching on the second column alone),这时候你不得不维护另外一个索引,也就是说你需要同时维护 (a,b)、(b) 这两个索引。
这时候,我们要考虑的原则就是空间了。比如上面这个市民表的情况,name 字段是比 age 字段大的 ,那我就建议你创建一个(name,age)的联合索引和一个 (age) 的单字段索引。
2. 索引下推
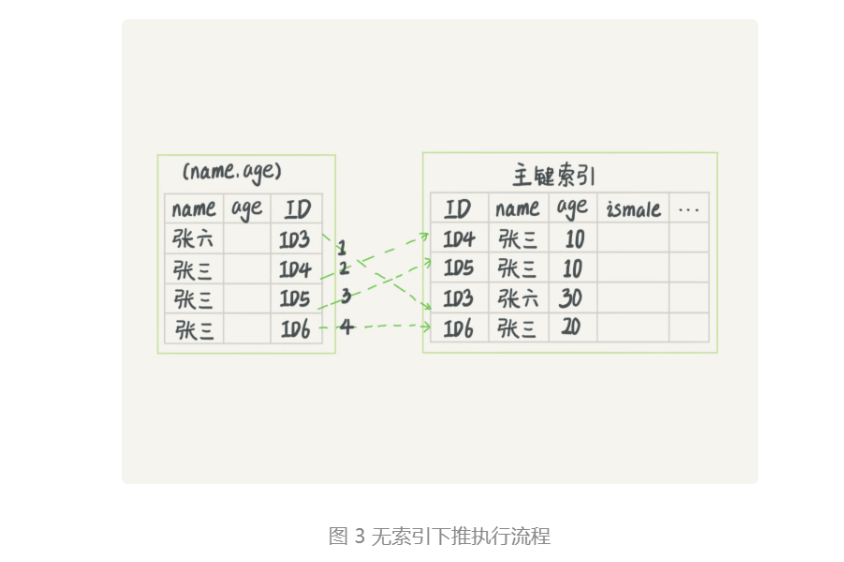
上一段我们说到满足最左前缀原则的时候,最左前缀可以用于在索引中定位记录。这时,你可能要问,那些不符合最左前缀的部分,会怎么样呢?
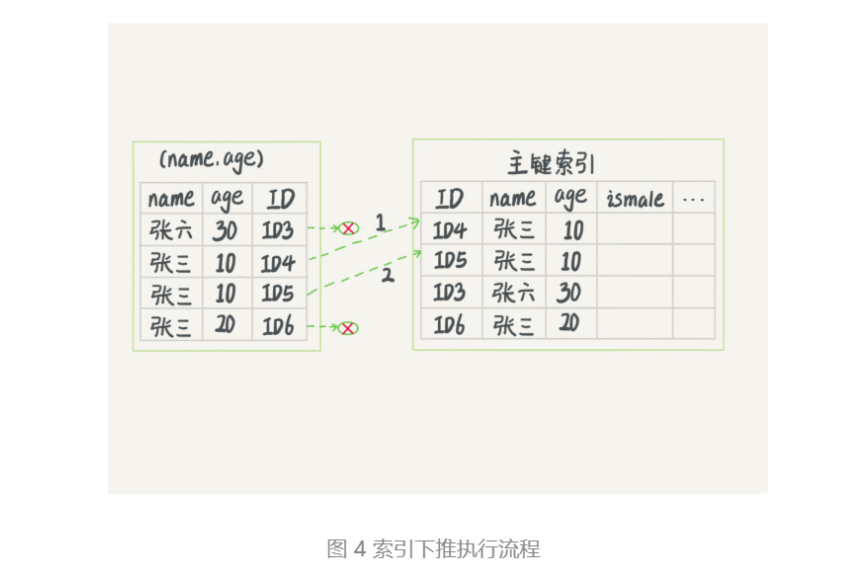
还是以市民表的联合索引(name, age)为例。如果现在有一个需求:检索出表中“名字第一个字是张,而且年龄是 10 岁的所有男孩”。那么,SQL 语句是这么写的:
1 | mysql> select * from tuser where name like '张%' and age=10 and ismale=1; |
根据前缀索引规则,这个语句在搜索索引树的时候,只能用 “张”(索引只有(name, age)),找到第一个满足条件的记录 ID3。当然,这还不错,总比全表扫描要好。然后呢?当然是判断其他条件是否满足。
在 MySQL 5.6 之前,只能从 ID3 开始一个个回表。到主键索引上找出数据行,再对比字段值。
而 MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
图 3 和图 4,是这两个过程的执行流程图。
3. 小结
在满足语句需求的情况下, 尽量少地访问资源是数据库设计的重要原则之一。在使用数据库的时候,尤其是在设计表结构时,也要以减少资源消耗作为目标。
问题:实际上主键索引也是可以使用多个字段的。DBA 小吕在入职新公司的时候,就发现自己接手维护的库里面,有这么一个表,表结构定义类似这样的:
1 | CREATE TABLE `geek` ( |
公司的同事告诉他说,由于历史原因,这个表需要 a、b 做联合主键,这个小吕理解了。
但是,学过本章内容的小吕又纳闷了,既然主键包含了 a、b 这两个字段,那意味着单独在字段 c 上创建一个索引,就已经包含了三个字段了呀,为什么要创建“ca”“cb”这两个索引?
同事告诉他,是因为他们的业务里面有这样的两种语句:
1 | select * from geek where c=N order by a limit 1; |
问:这位同事的解释对吗,为了这两个查询模式,这两个索引是否都是必须的?为什么呢?
答案:ca索引不需要,cb索引需要

联合索引:The first column is the primary sort criterion and the second column determines the order only if two entries have the same value in the first column and so on


