Spark
参考 http://dblab.xmu.edu.cn/blog/985-2/ https://alison.com/topic/learn/128563/introduction-to-scala-and-apache-spark
1. Introduction to Spark


There's a lot of cool features built on top of Spark, like things for machine learning and graph analysis and streaming data.
1.1 Spark 运行架构
1.1.1 架构设计
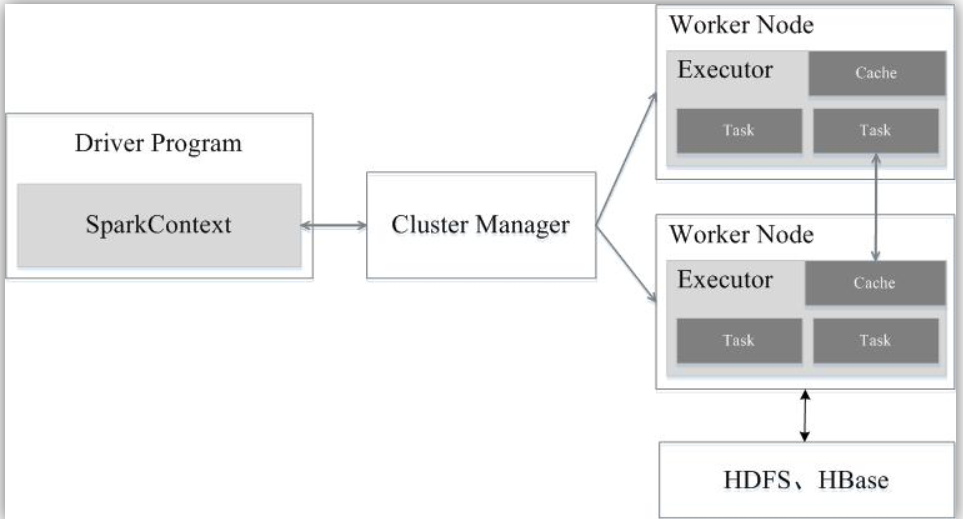
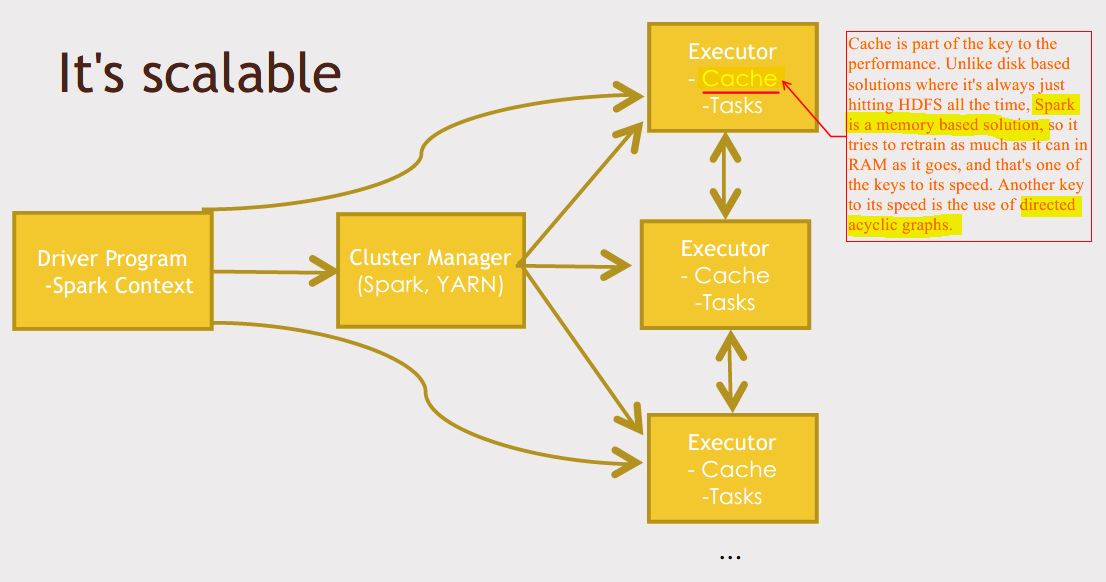
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
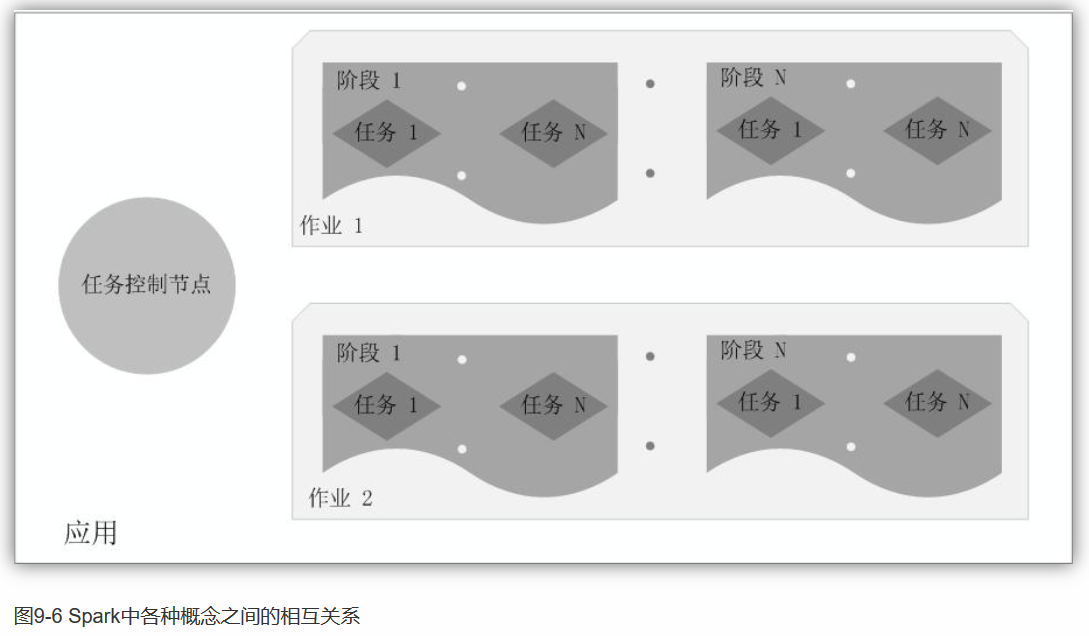
如下图所示,在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
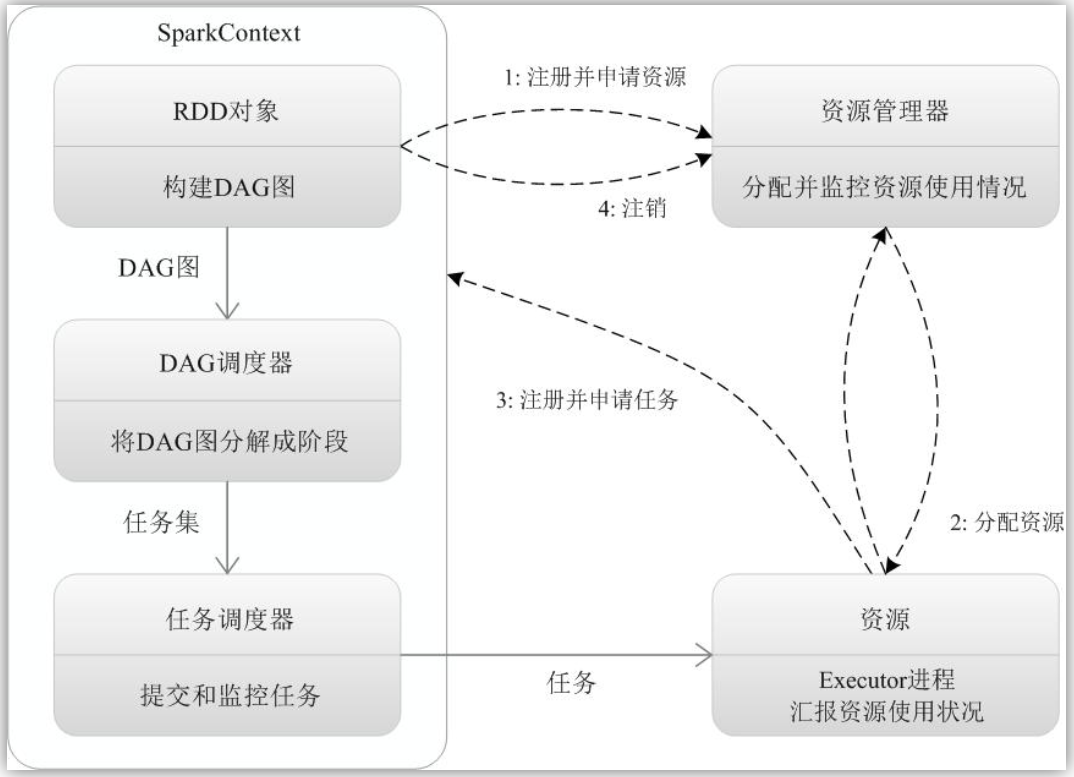
1.1.2 运行流程
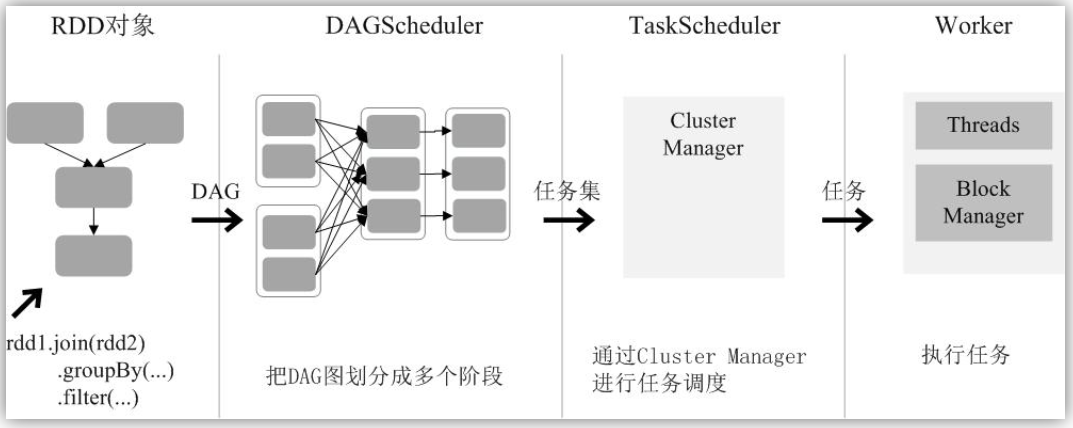
Spark的基本运行流程如下: (1)当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源; (2)资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上; (3)SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor; (4)任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
总体而言,Spark运行架构具有以下特点: (1)每个应用都有自己专属的Executor进程,并且该进程在应用运行期间一直驻留。Executor进程以多线程的方式运行任务,减少了多进程任务频繁的启动开销,使得任务执行变得非常高效和可靠; (2)Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可; (3)Executor上有一个BlockManager存储模块,类似于键值存储系统(把内存和磁盘共同作为存储设备),在处理迭代计算任务时,不需要把中间结果写入到HDFS等文件系统,而是直接放在这个存储系统上,后续有需要时就可以直接读取;在交互式查询场景下,也可以把表提前缓存到这个存储系统上,提高读写IO性能; (4)任务采用了数据本地性和推测执行等优化机制。数据本地性是尽量将计算移到数据所在的节点上进行,即“计算向数据靠拢”,因为移动计算比移动数据所占的网络资源要少得多。而且,Spark采用了延时调度机制,可以在更大的程度上实现执行过程优化。比如,拥有数据的节点当前正被其他的任务占用,那么,在这种情况下是否需要将数据移动到其他的空闲节点呢?答案是不一定。因为,如果经过预测发现当前节点结束当前任务的时间要比移动数据的时间还要少,那么,调度就会等待,直到当前节点可用。
1.2 Spark 特点
1.2.1 Scalable
1.2.2 Fast

Spark除了比MapReduce更快以外,还有一个优势:MapReduce is very limited in what it can do. You have to think about things in terms of mappers and reducers, whereas Spark provides a framework for removing that level of though from you, you can just think more about your end results and program toward that and think less about how to actual distribute it across the cluster.
1.2.3 Hot

1.2.4 Not that hard (可使用的语言,RDD)

A few lines of code can actually kick off some very complex analysis on a cluster.
Spark 2.0 which came out in 2006, they've built on top of RDDs to produce something called a data set. That's a little bit more of a SQL focused take on an RDD, but at the end of the day, it's still built around the RDD.
1.3 Components of Spark
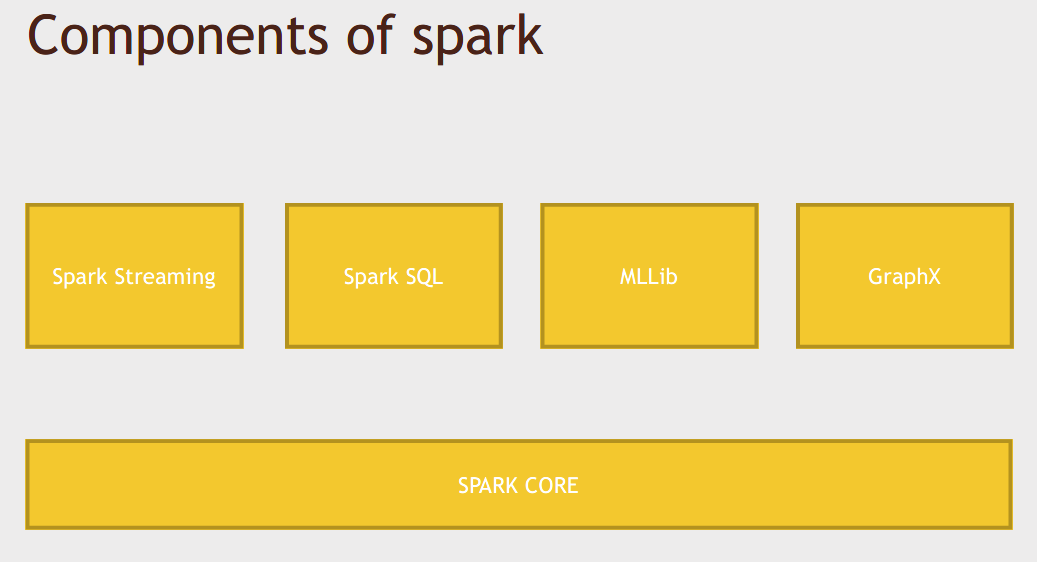
Spark has a lot of depth to it, so while you could just program at the RDD level within Spark Core, there are also libraries built on top of Spark that are part of Spark itself.
Spark Streaming: Instead of doing batch processing of data, you can actually input data in real time. Data can be ingested as it's being produced, and then Spark can analyze it across some window of time, and you can output the results of that analysis to a database or some NoSQL data store, all within a few lines of code.
Spark SQL: Very hot area right now. It's basically a SQL interface to Spark. You can write SQL queries against your data using Spark SQL. It allows us to do more optimizations beyond the directed acyclic graph, because it can do SQL optimizations on the queries that you're actually running.
MLLib: An entire library of machine learning and data mining tools that you can run on a data set that's in Spark.
GraphX: That's the graph in terms of graph theory. Imagine for example, you have a social network graph, and you want to analyze the properties of that graph, and see who's connected to who and what way, and what are the shortest path and things like that, GraphX provides a very extensible way of doing that. (Graph Computation)
SO, very rich ecosystem surrounding Spark that lets you do a wide variety of tasks on big data across the cluster.
Spark provides high-level API in Java, Scala, Python, and R, so Spark Programming can be deployed in any of these languages.
Spark can either run Stand alone or on an exsiting cluster manger.
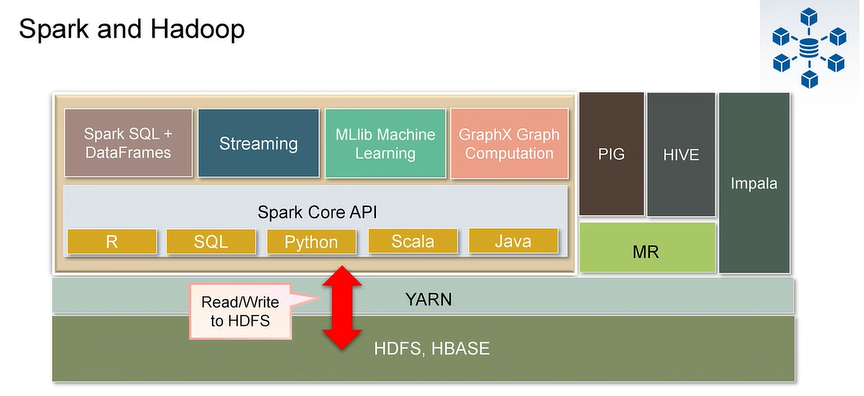
这门课将使用的语言及Scala

If you do want to end up using Spark in production in the real world, Python is OK to start with, but you probably want to move to Scala.

It's not very hard to move from Python to Scala.
2. Understand Data Units in Spark - RDD

2.1 What is RDD?

RDD is the spark's core abstraction which is Resilient Distributed Dataset. It is immutable distributed collection of objects (cannot modify, distributed to different nodes across clusters). Internally Spark distributes the data in RDD, to different nodes across the cluster to achieve parallelization.
It's an abstraction across all the nastiness that happens under the hood to actually make sure your job is evenly distributed across your cluster that it can handle failures in a resilient manner, and at the end of the day, it just looks like a dataset to you.
From a programming standpoint, an RDD is just a dataset to you. But under the hood, it's resilient and distributed and you don't have to think about that very much.
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD是只读的记录分区的集合,不能直接修改(immutable),只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
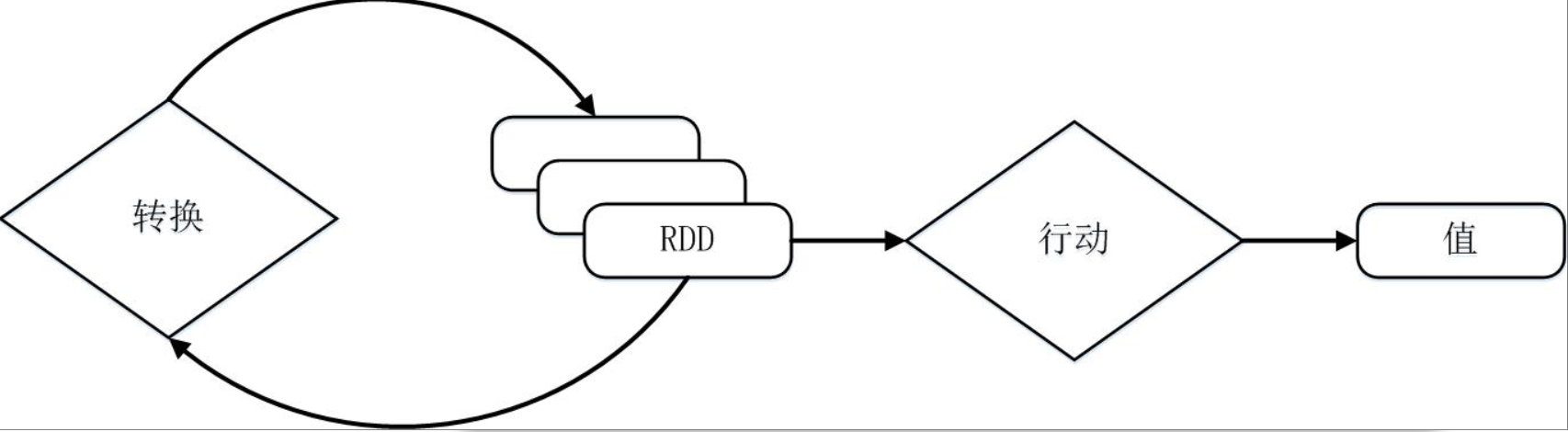
RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
RDD典型的执行过程如下:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
需要说明的是,RDD采用了惰性调用 (Lazy Evaluation)(更多关于惰性调用的内容见2.6 Lazy Evaluation),即在RDD的执行过程中(如下图所示),真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
2.2 How do you make RDD

The SparkContext is sort of the environment that your driver program runs within Spark, and it is what creates RDDs.
运行spark的时候(安装完成后,命令行执行spark-shell),会自动创建sc
2.3 Create RDD
创建RDD的两种方式:
By distributing collection of objects.
例如创建一个list collection,然后pass it to spark context的parallelize方法:
Val colorsRDD = sc.parallize(List("red,blue"))By loading an external dataset.
例如加载一个外部数据集books.txt:
Val booksRDD = sc.textFile("/path/to/filename.txt")


示例:Working with RDD and its Operations in Spark:
第一步run spark shell(可以看到spark-shell is bind with Scala and java ). 第二步,创建一个RDD,第三步使用collect action to retrieve complete list of elements from RDD。
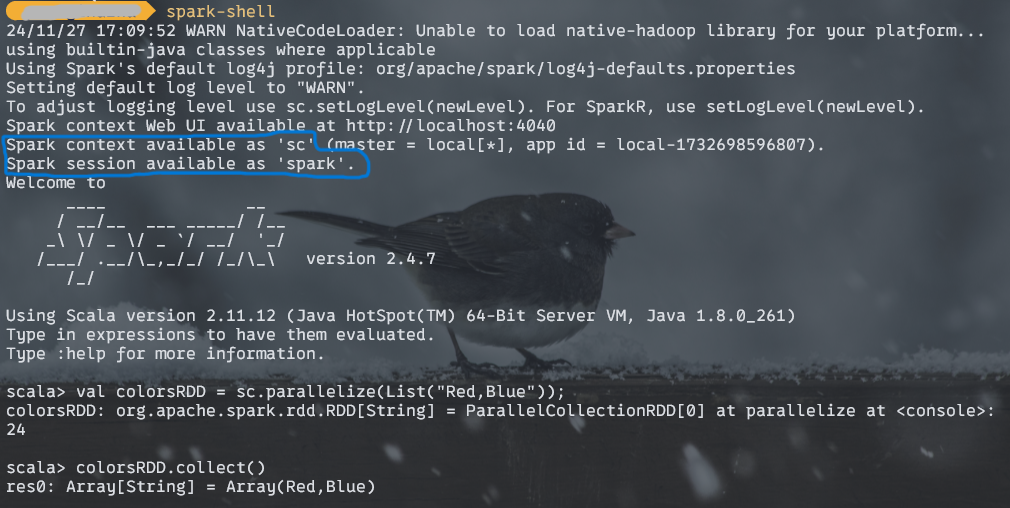
注:退出scala可以使用 :q
2.4 Transform RDD
- Create a new dataset from the existing one.
- Lazy in nature. They are executed only when some action is performed.

map: apply some function to every input row of your RDD and create a new RDD that is transformed in some way. Map is used when you have a one to one relationship
flatmap: 与map的区别在于,使用map, input于output是一对一的关系,使用flatmap, can have any relationship, where your input lines may or may not result in one or more output lines. 例如,maybe you want to split out each input line into multiple rows, or maybe you want to discard some of the input lines if they're invalid.
filter: can be used to take stuff out of an RDD so you can provide that with some function that determines whether or not a row survives.
distinct: gives you back the distinct unique values in an RDD.
sample: sample them randomly.


2.5 RDD actions
Returns to the driver program a value or exports data to a storage system after performing a coumputation.

2.6 Lazy evaluation 惰性调用
So basically, as you go through this script and transform your RDD's, until you hit an action, all that's doing is building up this graph, this chain of dependencies within your driver script, and only when that action is called does it actually figure out the quickest path through those dependencies. And it's at that point that it actually kicks off the job on your cluster.
RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
例:一个Spark的“Hello World”程序 这里以一个“Hello World”入门级Spark程序来解释RDD执行过程,这个程序的功能是读取一个HDFS文件,计算出包含字符串“Hello World”的行数。
1 | val sc= new SparkContext(“spark://localhost:7077”,”Hello World”, “YOUR_SPARK_HOME”,”YOUR_APP_JAR”) |
第1行代码用于创建SparkContext对象;第2行代码从HDFS文件中读取数据创建一个RDD;第3行代码对fileRDD进行转换操作得到一个新的RDD,即filterRDD;第4行代码表示对filterRDD进行持久化,把它保存在内存或磁盘中(这里采用cache接口把数据集保存在内存中),方便后续重复使用,当数据被反复访问时(比如查询一些热点数据,或者运行迭代算法),这是非常有用的,而且通过cache()可以缓存非常大的数据集,支持跨越几十甚至上百个节点;第5行代码中的count()是一个行动操作,用于计算一个RDD集合中包含的元素个数。这个程序的执行过程如下:
- 创建这个Spark程序的执行上下文,即创建SparkContext对象;
- 从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
- 构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
- 执行到第5行代码时,count()是一个行动类型的操作,触发真正的计算,开始实际执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
2.7 RDD 特性
总体而言,Spark采用RDD以后能够实现高效计算的主要原因如下: (1)高效的容错性。现有的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输,这对于数据密集型应用而言会带来很大的开销。在RDD的设计中,数据只读,不可修改,如果需要修改数据,必须从父RDD转换到子RDD,由此在不同RDD之间建立了血缘关系。所以,RDD是一种天生具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需通过RDD父子依赖(血缘)关系重新计算得到丢失的分区来实现容错,无需回滚整个系统,这样就避免了数据复制的高开销,而且重算过程可以在不同节点之间并行进行,实现了高效的容错。此外,RDD提供的转换操作都是一些粗粒度的操作(比如map、filter和join),RDD依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志(比如对哪个数据项进行了修改),这就大大降低了数据密集型应用中的容错开销; (2)中间结果持久化到内存。数据在内存中的多个RDD操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销; (3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化开销。
2.8 RDD 之间的依赖关系
参考
https://blog.csdn.net/weixin_43958974/article/details/122292746 http://dblab.xmu.edu.cn/blog/985-2/
在 Spark 中,RDD 分区的数据不支持修改,是只读的。如果想更新 RDD 分区中的数据,那么只能对原有 RDD 进行转化操作,也就是在原来 RDD 基础上创建一个新的RDD。
那么,在整个任务的运算过程中,RDD 的每次转换都会生成一个新的 RDD,因此 RDD 们之间会产生前后依赖的关系。
说白了,就是相当于将对原始 RDD 分区数据的整个运算进行了拆解,当运算中出现异常情况导致分区数据丢失时,Spark 可以通过依赖关系从上一个 RDD 中重新计算丢失的数据,而不是对最开始的 RDD 分区数据重新进行计算。
在 RDD 的依赖关系中,我们将上一个 RDD 称为父RDD,下一个 RDD 称为子RDD。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),下图展示了两种依赖之间的区别。
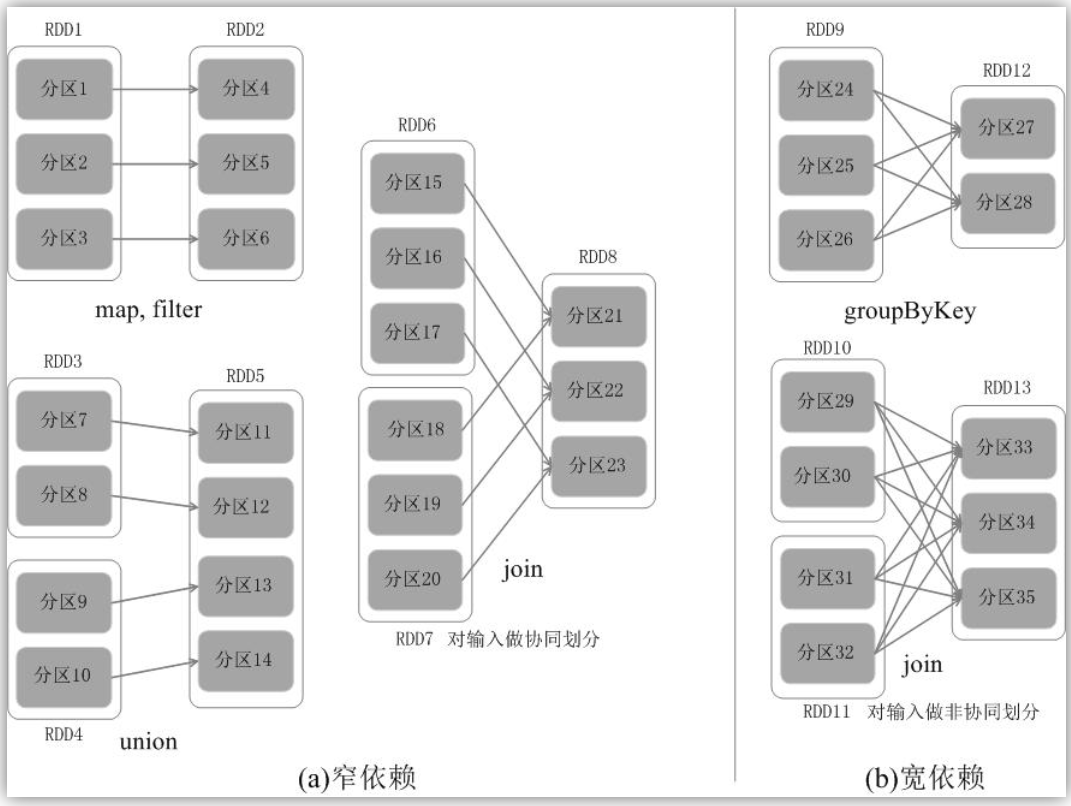
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区。 宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。
总体而言,如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。
有个形象的比喻,如果父 RDD 中的一个分区有多个孩子(被多个分区依赖),也就是超生了,就为宽依赖;反之,如果只有一个孩子(只被一个分区依赖),那么就为窄依赖。
窄依赖典型的操作包括map、filter、union等,宽依赖典型的操作包括groupByKey、sortByKey等。对于连接(join)操作,可以分为两种情况。 (1)对输入进行协同划分,属于窄依赖(上图(a)所示)。所谓协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。 (2)对输入做非协同划分,属于宽依赖,如上图(b)所示。
对于窄依赖的RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的RDD,则通常伴随着Shuffle操作,即首先需要计算好所有父分区数据,然后在节点之间进行Shuffle。
在窄依赖中子 RDD 的每个分区数据的生成操作都是可以并行执行的,而在宽依赖中需要所有父 RDD 的 Shuffle 结果完成后再执行。
Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。因为,RDD数据集通过“血缘关系”记住了它是如何从其它RDD中演变过来的,血缘关系记录的是粗颗粒度的转换操作行为,当这个RDD的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的数据分区,由此带来了性能的提升。相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
2.9 阶段的划分
在 Spark 执行作业时,会按照 Stage 划分不同的 RDD,生成一个完整的最优执行计划,使每个 Stage 内的 RDD 都尽可能在各个节点上并行地被执行。
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分阶段。具体划分方法是:在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。
因此,划分宽窄依赖也是 Spark 优化执行计划的一个重要步骤,宽依赖是划分执行计划中 Stage 的依据,对于宽依赖必须要等到上一个 Stage 计算完成之后才能计算下一个阶段。
例:如图9-11所示,假设从HDFS中读入数据生成3个不同的RDD(即A、C和E),通过一系列转换操作后再将计算结果保存回HDFS。对DAG进行解析时,在依赖图中进行反向解析,由于从RDD A到RDD B的转换以及从RDD B和F到RDD G的转换,都属于宽依赖,因此,在宽依赖处断开后可以得到三个阶段,即阶段1、阶段2和阶段3。可以看出,在阶段2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,比如,分区7通过map操作生成的分区9,可以不用等待分区8到分区9这个转换操作的计算结束,而是继续进行union操作,转换得到分区13,这样流水线执行大大提高了计算的效率。
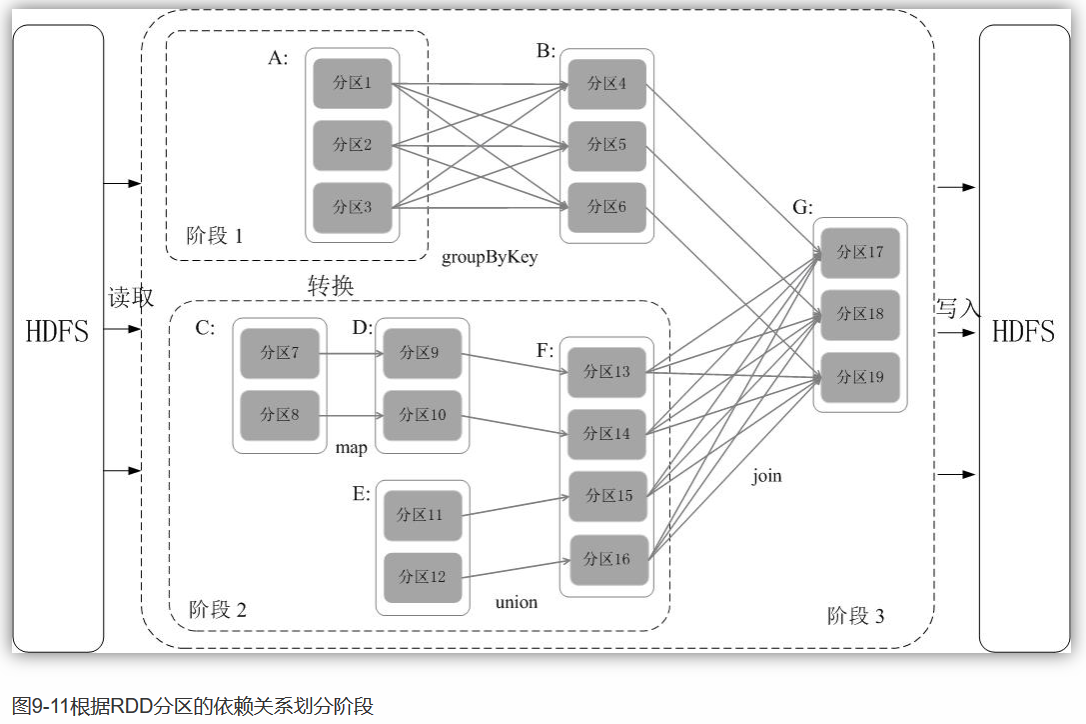
由上述论述可知,把一个DAG图划分成多个“阶段”以后,每个阶段都代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给Executor运行。
2.10 RDD 运行过程
总结一下RDD在Spark架构中的运行过程(如下图所示): (1)创建RDD对象; (2)SparkContext负责计算RDD之间的依赖关系,构建DAG; (3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
2.11 Using RDD's in Spark
Find the movie with the lowest average rating - with RDD's.

3. Spark SQL (DataFrames and DataSets)

Now, let's talk about Spark SQL and the Spark 2.0 way of doing things using dataframes and datasets.
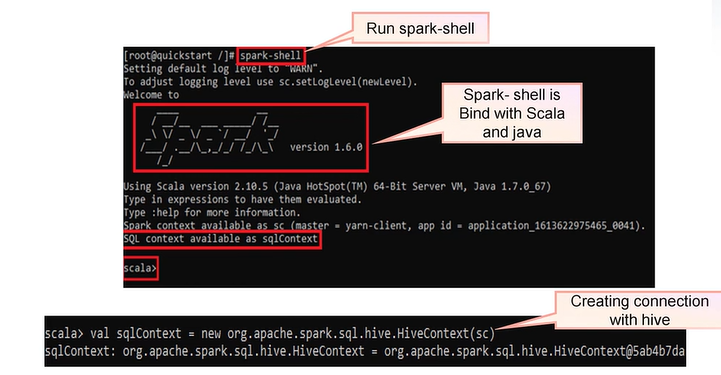
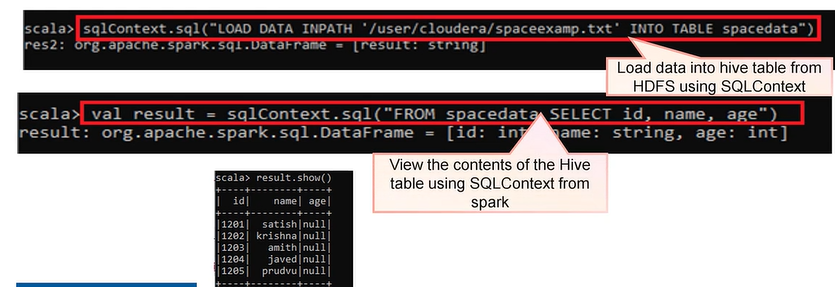
Overview of Spark SQLContext

Working with SQLContext
Spark 1.x Vs Spark 2.x


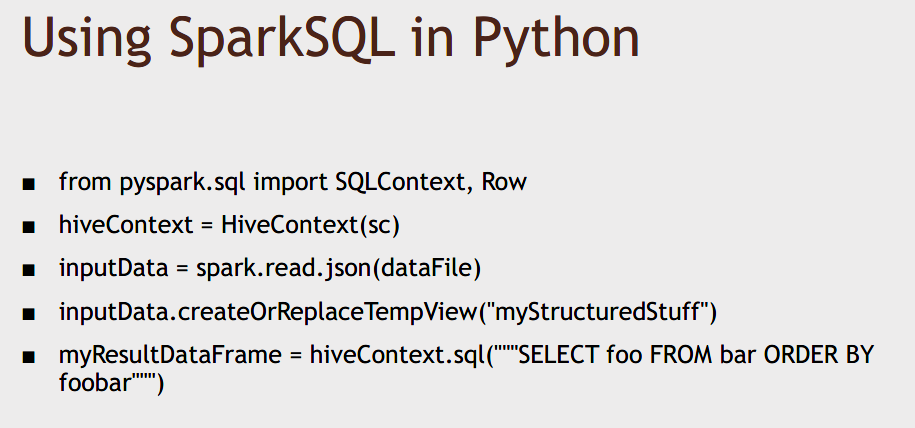

DataFrame is really a dataset of row objects, and DataSet is a more general term that can contain any sort of typed information, not necessarily a row like you have in a DataFrame.


Spark SQL is very extensible, you can create user defined functions that plug into a SQL and create your own functions you can use within your SQL queries.
SO, this is the power of DataFrames and DataSets in Spark 2.0 and Spark SQL. The other thing that's worth noting is that this is sort of the unified API between different subsystems of Spark going forward. You'll see that in Spark 2 the MLLib machine learning library of the Spark streaming library, all now have DataSet based APIs that you can use, so DataSets are kind of the common denominator between these different systems that allow you to pass data between them.
So, not only do you get performance benefits by using DataSets in Spark 2, you also get easier ways of actually using all these capabilities built on top of Spark we can mix and match them in interesting ways.
Using DataSets in Spark 2
Find the movie with lowest average rating - with DataFrames.

4. Using MLLib in Spark
movie recommendations (通过predict rating)

Exercise



check your result
The DataFrame approach is a lot easier to use, and when you're running it at a large scale it's going to be faster as well.