Using relational data stores with Hadoop —— Hive & Sqoop
HIVE
We can actually make your Hadoop cluster look like a relational database through a technology called Hive. And there's also ways of integrating a new Hadoop cluster with a MySQL database.

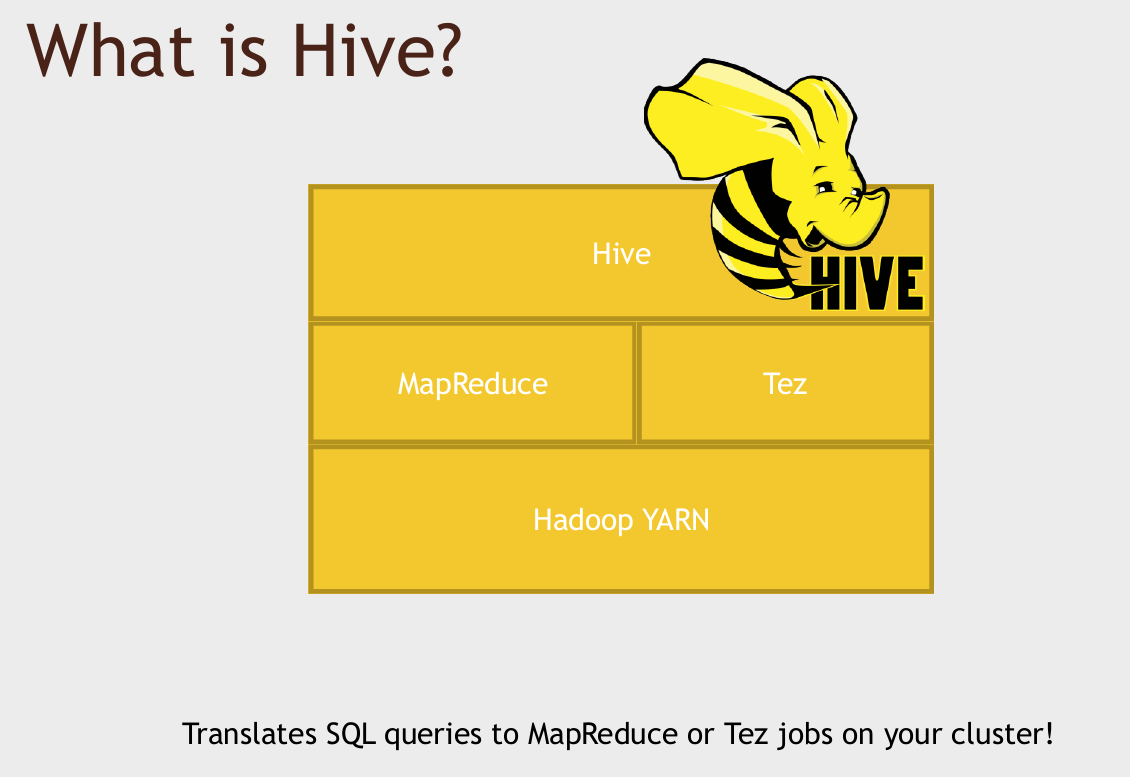
What is Hive?
It lets you write standard SQL queries that look just like you'd be using them on MySQL, but actually execute them on data that's stored across your entire cluster, maybe on an HDFS cluster as well.
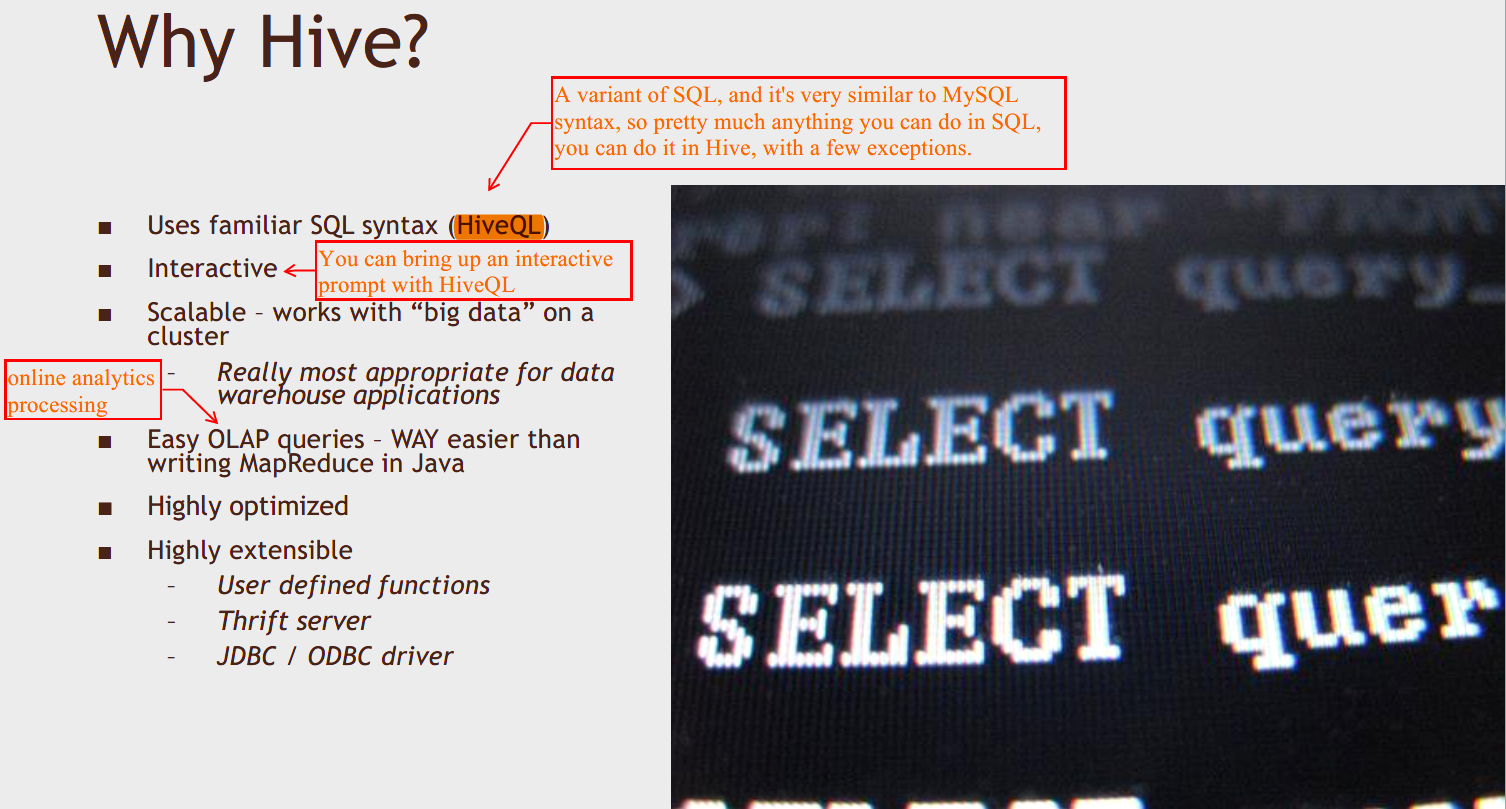
Why Hive
Why not Hive

It's not really meant for being hit with tons of queries all at once, from a website or something like that. That's where you use something like HBase instead.
Hive is a bunch of smoke and mirrors to make it look like a database, so you can issue SQL queries on it, but it isn't really.
HiveQL

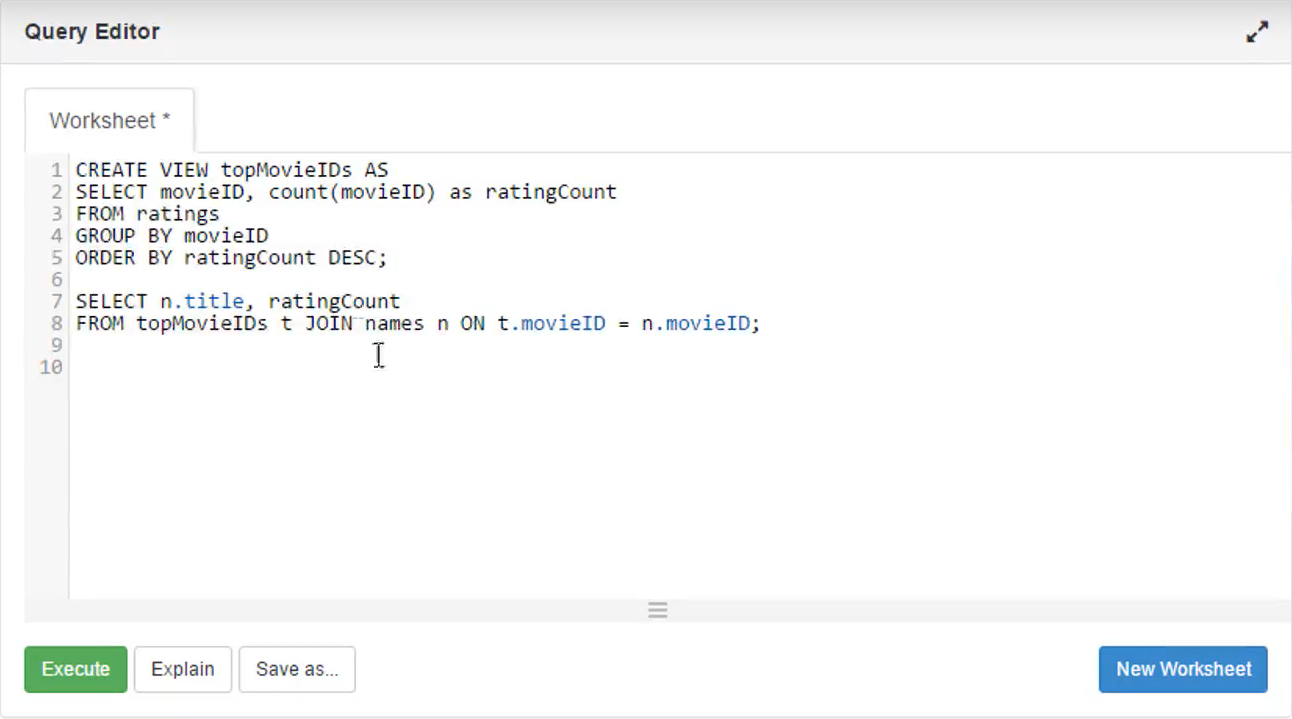
[Activity] Use Hive to find the most popular movie
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963170#overview
或写成:
1 | SELECT title, COUNT(movieID) AS ratingCount |
We used views in Hive to split up a more complicated query into something more readable and more manageable.
执行时会花一点时间,remember this isn't really a relational database, so things like joins are kind of painful when you're not dealing with normalized data.
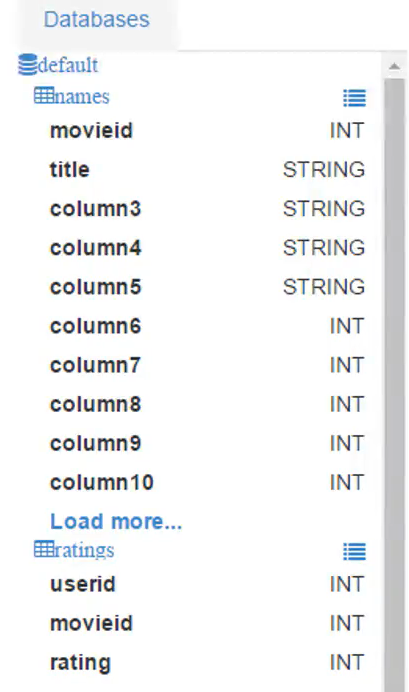
执行后会发现新创建的view出现在了Database里:
Your views are persistent, they're stored to disk.
若此时再执行会出错,可写成:
CREATE VIEW IF NOT EXISTS topMovieIDs ...
Just to clean up our mess and not leave that around:
DROP VIEW topMovieIDs;
How Hive works?

Schema on read

One of the basic concepts pf Hive is something called schema on read, and this is what separates it from a more traditional database. With a real relational database, it uses something called schema on write where you define the schema of your database before you load the data into it, and it's actually enforced at the time that you write the data to disk.
Hive flips that on its head. It takes unstructured data and just sort of applies a schema to it as it's being read instead.
So, Hive isn't creating some structured relational database under the hood, that would be very inefficient, it's just taking the existing data that you have on your cluster and imparting a schema to it when it's read in.
Where is the data? (内部表与外部表)

对于 managed table, if you do a "DROP TABLE" command from Hive, then that data is gone.
But sometimes you want to share that data with other systems that are outside of Hive. So that's where external tables come in. "CREATE EXTERNAL TABLE" with "Location" says, "I'm going to use Hive on this data here, but I'm not going to own it anymore". So I drop this table, it's going to drop the metadata, 但是原数据不会被删除。
Partitioning 分区
If you do have a massive dataset and your queries tend to be on a specific partition of that data, partitioning in Hive can be a very important optimization.
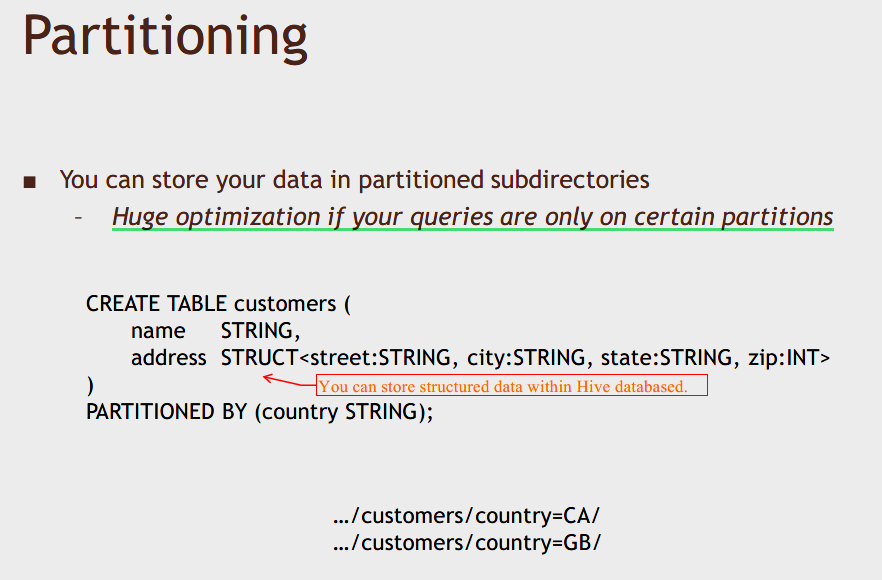
We wouldn't have to scan over the entire customer database, we could just scan over the actual files that are specific to the country that I'm interested in.
Ways to use Hive

[Activity] Use Hive to find the movie with the highest average rating
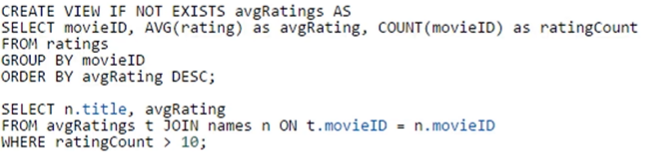
或写成:?
1 | SELECT title, AVG(rating) as avgRating |
Sqoop
Integrating MySQL with Hadoop



Import/Export data (MySQL <-> HDFS/Hadoop)
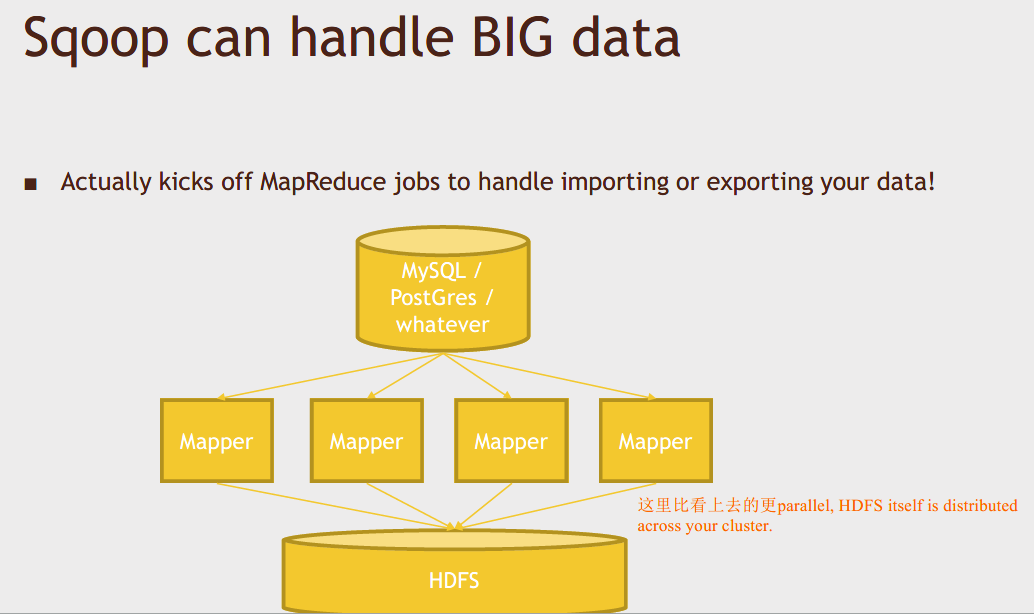
Export data from your database into Hadoop:
- kick off a bunch of mappers (只有mappers, all we're doing is moving data and transforming it from one place to another, there's no real reduce going on here.)
- all these mappers are going to talk to your HDFS cluster on your Hadoop cluster and populate a big old table on HDFS, which is a giant text file (例如逗号分隔的数据), and from there, you can use tools like Hive or Pig on it.
REMEMBER, the power of HDFS is that file might be distributed across many different hosts, blocks, and also stored redundantly. We've done more than just dump our database to a file here - we've dumped it into HDFS, which opens up a whole world of possibilities for analyzing it in a robust, scalable and a manner that can be resilient to failure.
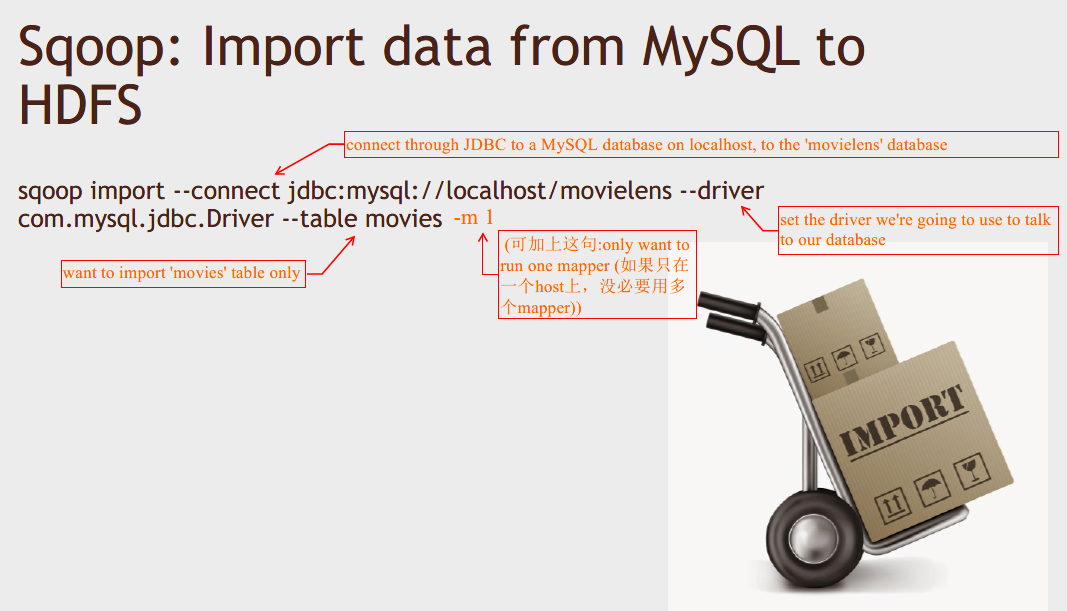

与导入HDFS一样,导入Hive同样会kick off a MapReduce job.


Play with MySQL and Sqoop

[Activity] Install MySQL and import our movie data
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963236#overview
[Activity] Use Sqoop to import data from MySQL to HDFS/Hive
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963266#overview
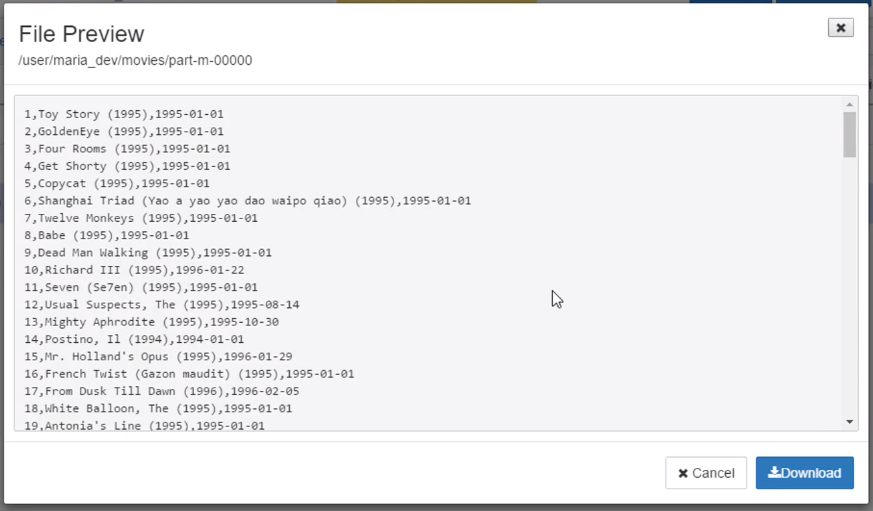
由 MySQL 导入 HDFS 后:
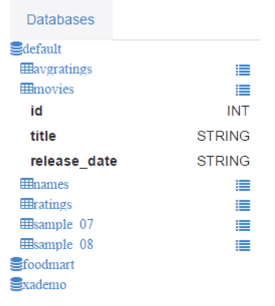
由 MySQL 导入Hive后:
注:These sorts of tools that we're using with Hadoop are really intended for big datasets, so there's a lot of overhead for doing what's actually a pretty simple operation. It doesn't make sense if you're using small datasets. 如果数据集很小,在一个host就能装下,没必要用这些工具,用MySQL就足够了。
[Activity] Use Sqoop tp export data from Hadoop to MySQL
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963272#overview
- 首先需要知道 where the data in Hive actually resides. REMEMBER, Hive is just a schema-on-read sort of deal. The actual data itself if just stored as a plain old text somewhere, and all Hive is doing is imparting structure to it when it's being read.
On Hortonworks:
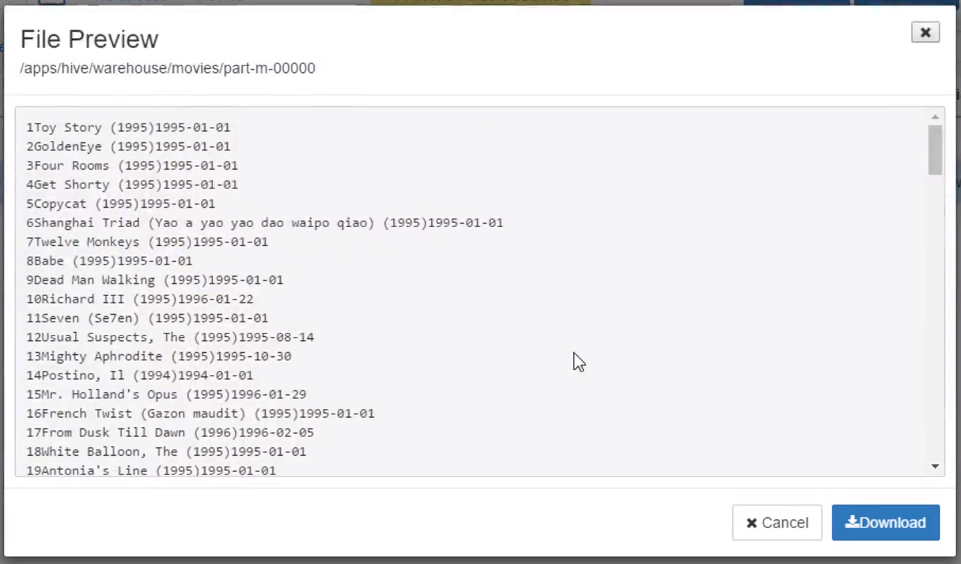
不是靠逗号分隔的,Hive actually uses low ASCII values, like 1 and 2 and 3, to delimit its data.
- 在导入前,MySQL中要先有 target table
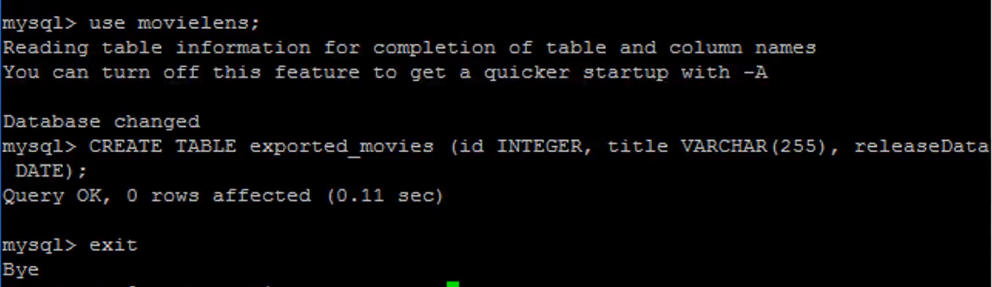

和import一样,export也会kick off a bunch of mappers using MapReduce.
什么时候需要从Hive导入MySQL: From a practical standpoint, if you need to expose your data to a database that's more well-suited for OLTP. Sometimes you'll be doing some huge operation using Hive or some other tool on your cluster, but the output of that operation might be small enough to fit on a single database.
结语
We talked about making your Hadoop cluster look like a MySQL database or a SQL database, using Hive.
And we also talked about using your Hadoop cluster with a real MySQL database as well. Kind of two different directions there.
Next, let's talk about NoSQL. Sometimes you actually want to expose your data in a way that's more amenable to real-time queries, and there's a bunch of ways to do that and also ways of integrating Hadoop with systems that are more real-time in nature.