Using non-relational data stores with Hadoop - NoSQL & HBase & MongoDB
Why NoSQL?
We've talked about integrating Hadoop with SQL solutions - MySQL - RDBMSs, if you will - relational database management systems - and those are very handy for giving you the power of a rich analytical query language like SQL to answer your business questions. But, you know, they do take a little bit of time to execute. So if you're doing analytic work, relational databases are awesome. Even if you're running a small, like, say, an internal web site or a very small-scale web site, something like MySQL can even vend that data to the outside world pretty well.
BUT let's imagine you need to take things up to the next level. You're going to start to run into some limitations with SQL and relational database systems.
Maybe you don't really need the ability to issue arbitrary queries across your entire dataset. Maybe all you need is just the ability to very quickly answer a specific question like "What movie should I recommend for this customer?" or "What web pages has this customer looked at in the past?"
And if you need to do that at a very large scale very quickly across a massive dataset, something like MySQL might not cut it. You know, if you're an Amazon or a Google, you might need something that can even handle tens of thousands of transactions per second without breaking a sweat. And that's where NoSQL comes in.
These are alternative database systems that give up a rich query language like SQL for the ability to very quickly and at great scale answer very simple questions. So for systems like that you want something called NoSQL, also known as non-relational databases, or not only SQL - that's a term that comes up sometimes, too. And these systems are built to scale horizontally forever, and also built to be very fast and very resilient.
Up first, let's talk about HBase. HBase is actually built on top of HDFS, so it allows you to have a very fast, very scalable transactional system to query your data that's stored on a horizontally partitioned HDFS file system. So if you need to expose your massive data that's sitting on your Hadoop cluster, Hbase can be a great way to expose that data to a web service, to web applications, anything that needs to operate very quickly and at a very high scale.


if you think about things like Amazon or Google, people are always buying new things or always searching for new things, new web sites are always coming out, so this data is always just getting bigger and bigger and bigger over time. So that has to live on some sort of a distributed cluster, like a Hadoop cluster. You're just not going to fit that into a single hard drive on a single database. You need something that's more horizontally scalable, where you can keep on adding capacity as your data continues to grow over time.
It's not just about random access to planet-size data - it's also planet-size access to that data. Imagine you're running a web site like Amazon, where you need to very quickly retrieve the list of things people ordered, or the things they looked at, or what movies they should be recommended, or on Google - what they searched for in the past. That all has to happen at extremely large scale. Tens of thousands of people per second might be hitting your service to actually retrieve this information in real time.
Again, a single Oracle database or MySQL database is not gonna cut it, when you're talking about that kind of transaction rates on that large of a data set.
过去没有NoSQL, Hadoop时,采用的方法:


All you need is an API that says, "given this customer ID, give me back this list of information", or "given
this item identifier, give me back this information about this item". So, more often than not, all you really need at runtime is a simple API that allows you to get information for a given key or put information into a given key.
These are basically, key-value data stores at a high level. And if that's all you need, then you don't need a big fancy relational database. All you need is a more scalable system that can be very easily horizontally partitioned for given key ranges, that just answers the question: "Give me this stuff for this key".
And you can always do both, too. For example, you can have a Hadoop cluster that you're running Hive on, or Pig, or Spark, to actually answer the more complex questions that you have, but for the things you are doing at a very high scale, at very high transaction rates, you can bolt on a NoSQL database to actually handle that part of the problem. It's not a question of one or the other - it's about having the right tools in place for the right jobs.

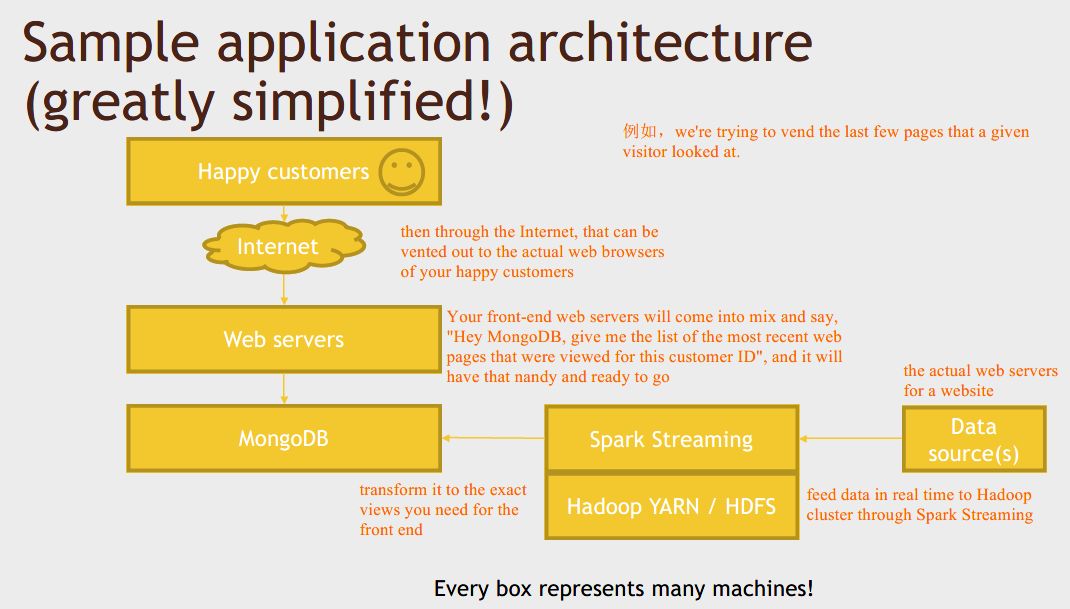

What is HBase

HBase is built on top of HDFS. So if you're storing massive datasets on an HDFS file system, HBase can be used to actually vend that to the outside world at a very large scale.

Just like every other NoSQL solution, it does not have a query language, but it does have an API that can very quickly answer the question "what are the values for this key?" or "store this value for this key".

CRUD

HBase architecture
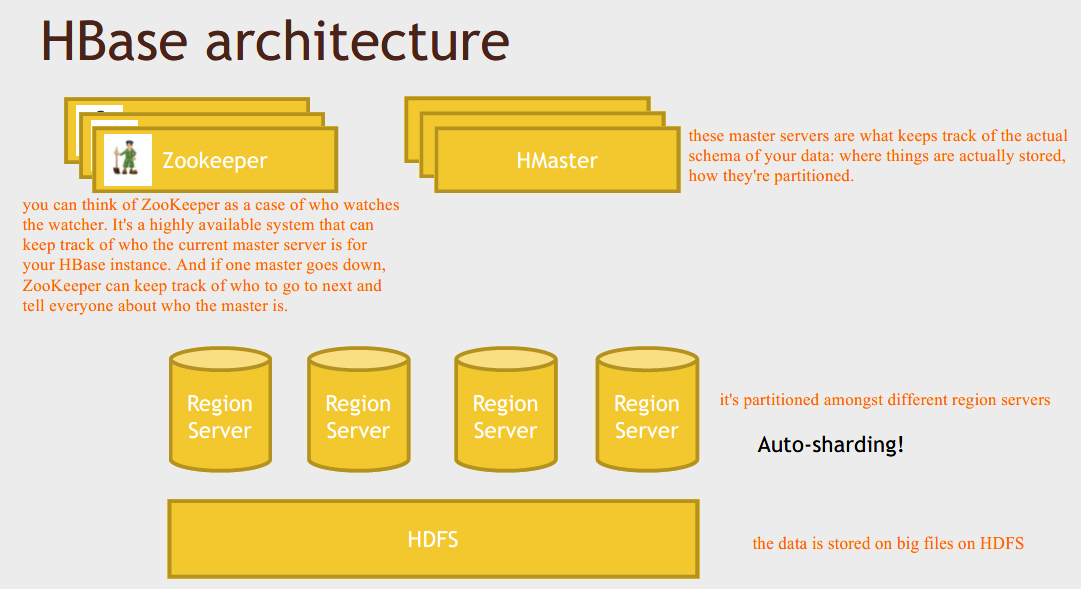
Basically, it's split up into different region servers. This is the core of HBase itself. When we talk about regions, we're talking about ranges of keys, so it's just like sharding or range partitioning in more traditional database systems. But the magic of it all is that it can automatically adapt, so, as your data grows, it can automatically repartition things, and if you add more servers to the mix, it can automatically deal with that at runtime.
So there's a very complex mechanism that involves write-ahead commit logs and, merging things together over time asynchronously. But you don't have to worry about those details - HBase does it for you. All you need to know is that it can automatically distribute your data amongst a fleet of region servers, so an entire cluster, if you will.
Now, when you have an application that's actually talking to HBase - a web application or a web server - it's not actually going to talk to these master nodes directly, it's going to be talking to region servers directly.
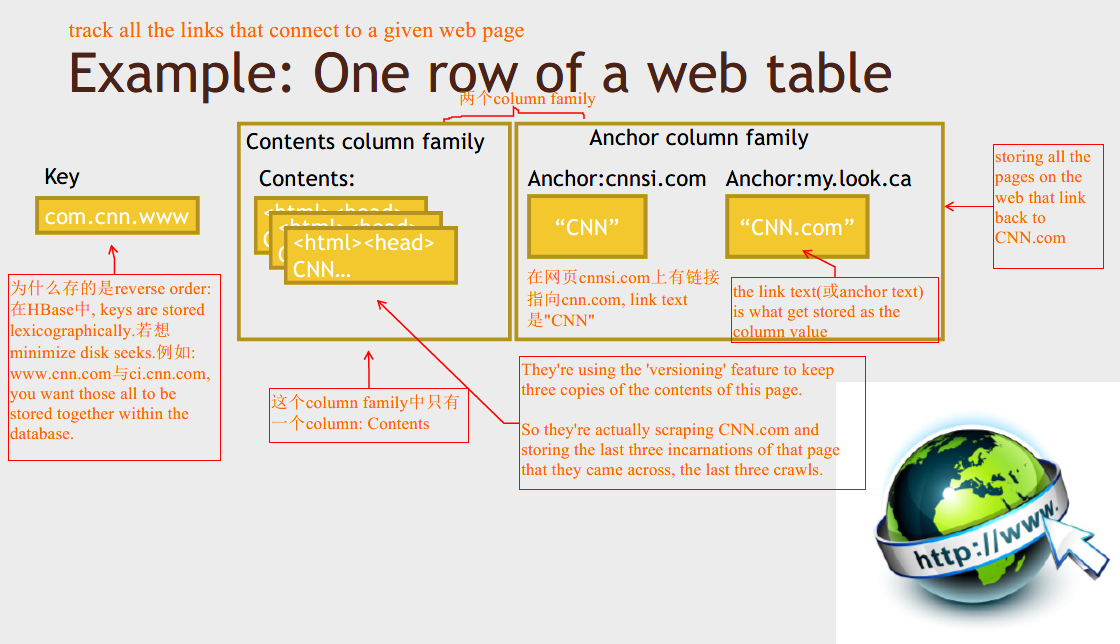
HBase data model

What's different about HBase is that it has the concept of column families. So you don't define a fixed set of columns for each row in your database. Instead you define column families, and each column family can contain a very large number of individual columns.
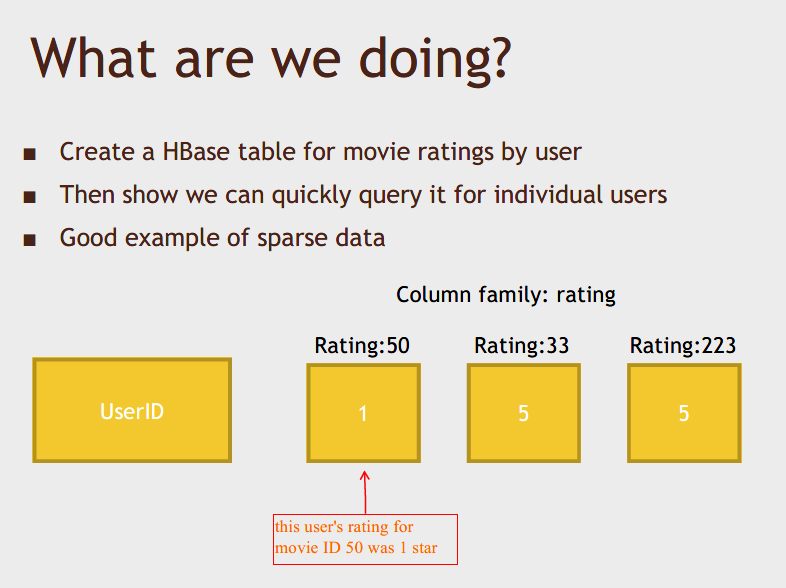
This comes in handy where you have cases of sparse data.
Ways to access HBase


[Activity] Import movie ratings into HBase
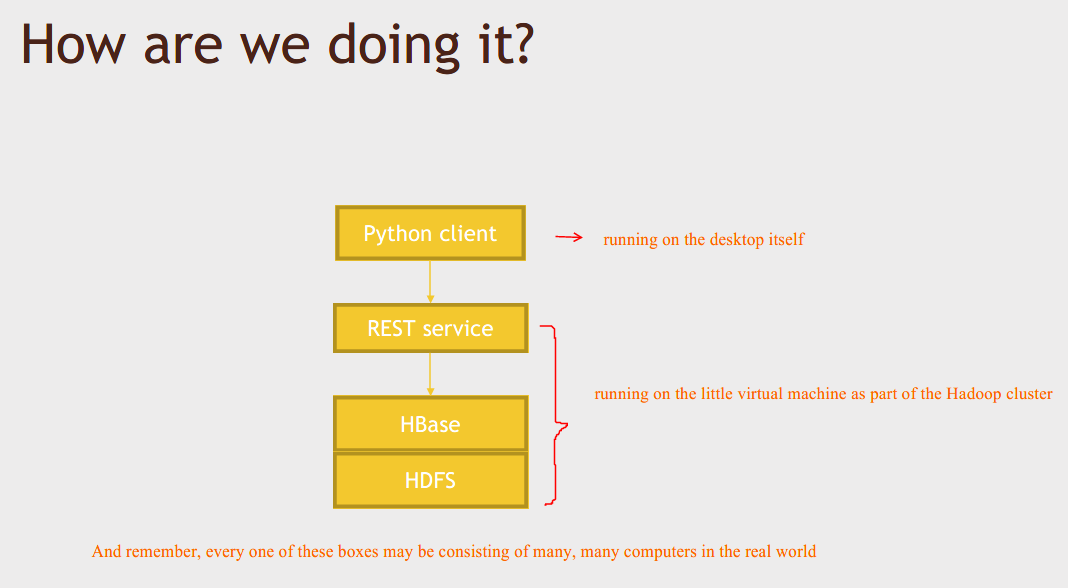
Now we're going to run a REST service on top of HBase. It's just a service that you can query through
HTTP requests, and we're going to write a client that actually queries that service to store and retrieve
data through the REST service.
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963426#overview
返回结果:

MongoDB Overview

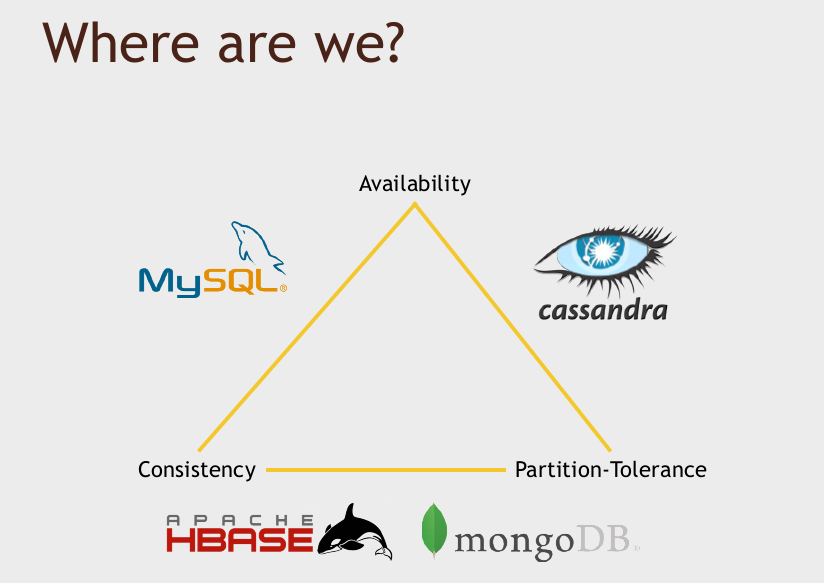
CAP theorem: MongoDB chooses consistency and partition-tolerance.
Since it dose have to deal with big data, partition-tolerance is something is has to do, and MongoDB chooses consistency over availability.
So MongoDB has a single master, a single primary database that you have to talk to all the time to ensure consistency. But if that master goes down, it will result in a period of unavailability, while a new primary database is put into place.
Document-based data model

The big thing that's different about MongoDB is that you can stick pretty much anything you want into MongoDB - basically, any JSON blob of data you can shove into a document in MongoDB. It doesn't have to be structured, you don't have to have the same schema across each document. You can put whatever you want in there.

You still need to think about what the queries are you going to be performing on this database and design your database schema accordingly. Think about what indices you might need for fast lookups for the queries you're going to do. At the end of the day, it's still a NoSQL database, so you cannot do joins efficiently, so you want to make sure your schema is denormalized as much as you can.
MongoDB terminology

在MongoDB中我们讨论 Databse, Collection, 和 Document, 而不是 Database, Table, 和 Row.
A MongoDB database contains collections, and a collection contains a collection of documents.
And the main restriction here is simply that you cannot move data between collections across different databases, so if you do need to reference data between different collections, they do need to be within the same database.
Replication Sets

MongoDB has a single-master architecture, the idea being that we want to have consistency over availability, but you can have these secondary databases that maintain copies over time from your primary database, so, as writes happen to your primary database, those writes get replicated through an operation log to any secondary nodes that you might have attached to it.
The way that replication chain works is kind of arbitrary. It actually just tries to figure out which server can it talk to most quickly.
And I want to stress again that we haven't even talked about big data yet. What we're talking about here in replica sets is just having a single monolithic MongoDB server, where all of the data sits on that single server, and we're replicating that data to backup servers.

Sharding (How MongoDB handles big data)
For actually scaling out data across more than one server with MongoDB, we need to set up something called sharding.
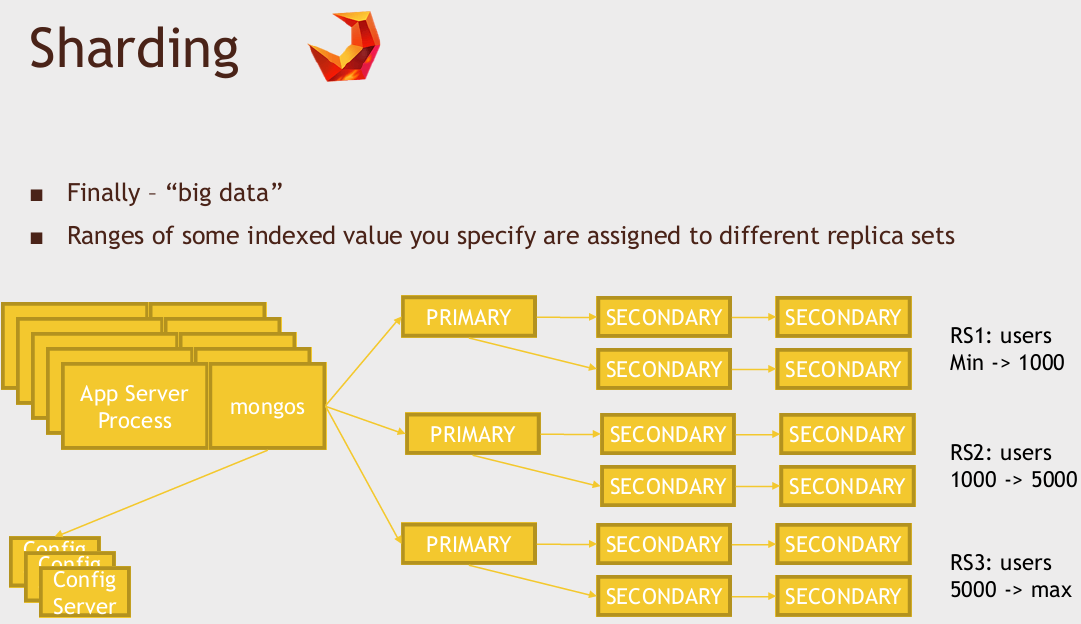
The way sharding works is that we actually have multiple replica sets, where each replica set is responsible for some range of values on some indexed value in my database. So in order to get sharding to work, it requires that you set up an index on some unique value on your collection, and that index is used to actually balance the load of information among multiple replica sets, and then on each application server, whatever you're using to talk to MongoDB, you'll run a process called "mongos", and "mongos" talks to exactly three configuration servers that you have running somewhere that knows about how things are partitioned and then uses that to figure out which replica set do I talk to to get the information that I want.
"mongos" is running something called a balancer in the background. So, over time, if it finds that it actually doesn't have an even distribution of values in whatever field you're partitioning on, it can rebalance things across your replica sets in real time over time.

Neat Things about MongoDB


[Activity] Install MongoDB and integrate Spark with MongoDB
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963458#overview
We're going to read in the "u.user" data file from the MovieLens dataset, convert that into a dataframe in Spark and then write that dataframe out to MongoDB, and then we're going to read it back and do a little query on it.
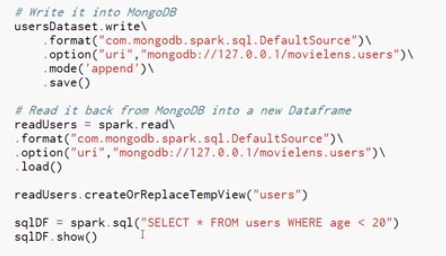
What we're not doing is loading this data into Spark locally and then running a query on it - what it's
actually doing is figuring out how do I translate this SQL query into a MongoDB query and actually
execute that on MongoDB and return the results back from MongoDB.
[Activity] Using the MongoDB Shell
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963462#overview
启动MongoDB Shell:


注意一点:we never set up an index. So when I said, "go find user ID 100", it couldn't do that very efficiently, and I actually had to do a full table scan, because MongoDB doesn't automatically index things for you.
I can do db.users.explain().find( {user_id: 100} ) , and
that will do an explain on the query, telling you what it will do under
the hood to actually execute the command "find" on the expression
"{user_id: 100}". And you can see here all it's doing is a scan on the
"winningPlan", looking for user ID 100 going forward. So it's kind of
just starts at the beginning of the entire database and chugs through it
forward one record, one document at a time, until it stumbles across
user ID 100, so, obviously, not the most efficient way of doing a
lookup.
So to fix that, let's make an index. To do that, I can say,
db.users.createIndex( {user_id: 1} ) -and what this means
is I want to create an index on the "user_id" field and the "1" just
means it's ascending. So that's going to give you back a sort order
that's in ascending order, if you want to optimize sorts as well.
Once it has its index on the "user_id" field, it can much more quickly look up where to find a given document for that user ID.
MongoDB does not set up an index for you on your primary key. You have to do it by hand, and if you forget to do it, your database is going to be horribly inefficient when you do lookups.
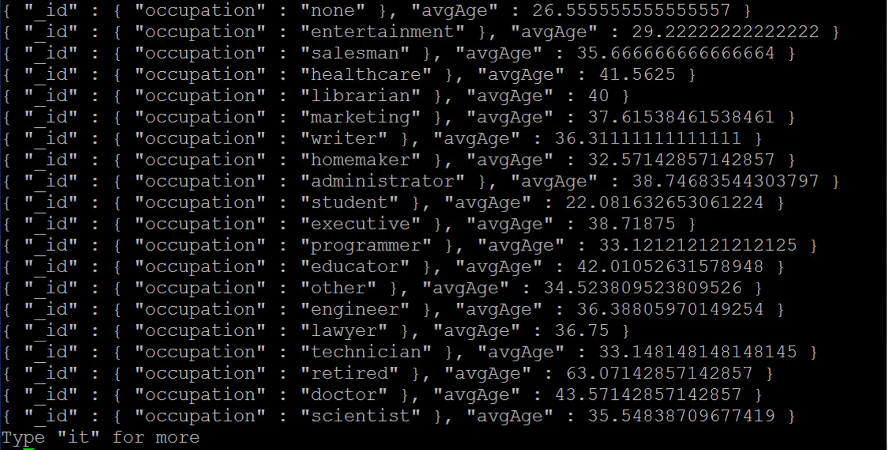
Let's aggregate all of the users by occupation and figure out the average age for each occupation.

In MongoDB things that start with a dollar sign mean that this has some sort of a special meaning to MongoDB, so "$group" is a command that MongoDB recognizes.
How many users are in our database?


Choosing a database technology
Integration considerations

Different technologies have different connectors for different other technologies.
例如, if you have a big analytics job that's currently running in Apache Spark, then you probably want to limit yourself to external databases that can connect easily to Apache Spark.
又例如, Maybe you have some front-end system that actually depends on having a SQL interface to a back-end database, and you're thinking about moving from a monolithic relational database to a distributed non-relational database. In that case, it might make life a lot easier if the non-relational database you're moving to offers some sort of SQL-like interface that can be easily migrated to from your front-end application.
Scaling requirements

How much data are you really talking about? Is it going to grow unbounded over time?
If so, then you need some sort of a database technology that is not limited to the data that you can store on one PC, right? You're going to have to look at something like Cassandra or MongoDB or HBase, where you can actually distribute the storage of your data across an entire cluster and scale horizontally instead of vertically.
Think, too, about your transaction rates: how many requests do you intend to get per second? You know, if we're talking about thousands, then, again, a single database server is not going to cut it. You need something that's distributed, where you can spread out the load of those transactions more evenly.
Support considerations

So do you actually have the in-house expertise to spin up this new technology and actually configure it properly? It's going to be harder than you think, especially if you're using this in the real world or in any sort of situation, where you have personally identifiable information in the mix from your end users. In that case, you need to make sure you're thinking very deeply about the security of your system, and the truth is most of the NoSQL databases we talked about, if you just configure them with their default settings, there'll be no security at all. Anybody at all can connect to these things and retrieve data or write data into them, so you need to make sure you have someone available who knows what they're doing for setting this up in a secure manner.
That might mean if you are in a big organization that has these experts in house, that's great, don't even think about it - but if you're in a smaller organization, you might want to consider: does this technology I'm choosing actually offer professional paid support that will help guide me through these setup decisions and the initial administration of my server over time? Or are there administrators that I can outsource the ongoing administration to over time? So in this case, you know, a more corporate solution like MongoDB might actually be a good choice, because, you know, they have paid support, and even for the more open-source Apache projects, there are companies out there that do offer paid professional support for them as well, so do your homework and try to figure out: can I really do this on my own, and if not, what resources are out there in the marketplace to help me?
CAP considerations
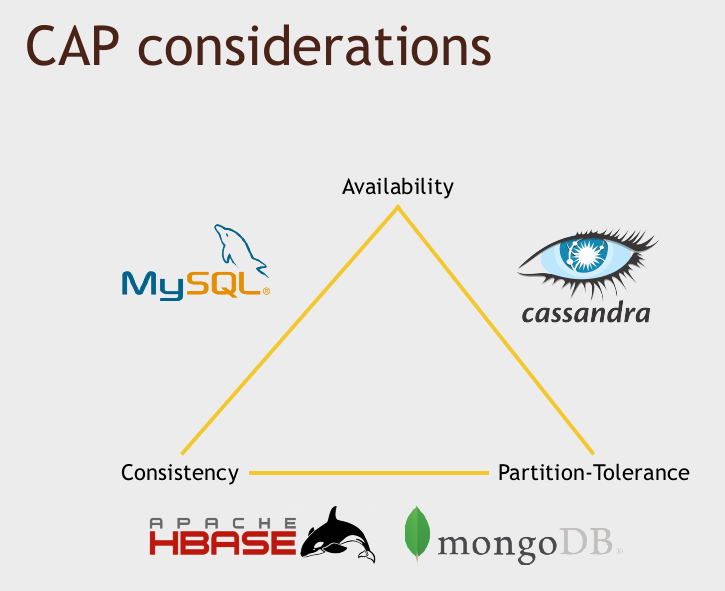
So again, the way to think about this is when you're thinking about the scale of your requirements, do you need to have partition tolerance? Do you have sufficient scale, where you know you're going to eventually need more than one server serving up the data just for handling the transactions you're talking about, and also for the scale of the data that you're talking about? If so, partition tolerance is non-negotiable, you need that one, and your only real choice in that case is consistency or availability.
And that will determine which one of these sides of the triangle you might want to lean toward. So the type of application will determine what you want there. Is it actually OK if your system goes down for a few seconds or a few minutes? If not, then availability's going to be your prime concern. Is it OK if you have eventual consistency, where, if you write something, people might get the old value back on subsequent reads for a few seconds? If so, who cares about consistency, right? Again, I would take availability instead. But if you're dealing with something that's dealing with real transactional information like, you know, stock transactions or some sort of financial transactions, you might value consistency above all else, and in that case, you want to really focus on that corner of the triangle.
注:Now, I should point out that the CAP theorem isn't really a hard-and-fast rule. The reality is these tradeoffs have become a little bit more loose in recent years. For example, consider Cassandra: is it really trading off consistency for availability and partition tolerance? Well, you can actually configure the amount of consistency that you want from Cassandra - you can tell it, "I want to make sure I get back the same result from every replica of this data before I actually consider that transaction to be final", and if you're running it in that mode, you're kind of getting all three.
The lines are getting blurred between these different tradeoffs over time. So the honest truth is any of these technologies can be made to work in pretty much any situation, if you try hard enough. It's really a question of choosing the technology that's best suited to the tradeoffs that you want to make.
Simplicity

If you don't need to set up a highly complex NoSQL cluster and something that needs a lot of maintenance, like, you know, MongoDB or HBase, where you have all these external servers that maintain its configuration, don't do it, if you don't need to.
Think about the minimum requirements that you need for your system and keep it as simple as possible.
If you don't need to deal with massive scale, don't deploy a NoSQL database, if you don't already have one, right? Just use a MySQL instance somewhere, it will be fine.
So keep it simple, do not deploy a whole new system that does not have good expertise within your organization, unless you really need to. Simple technologies and simple architectures are going to be a lot easier to maintain.
Examples

Go with MySQL.

Well, first of all, step back and ask yourself, "do I even have enough scale here to warrant a non-relational database at all? Why am I even thinking about this question - right? - if all I'm doing is analytics, that's what Hadoop is for, that's what Spark is for."
如果只是需要分析:You can import this data into HDFS on your cluster and analyze it offline.
如果是想要很快的得到结果:If we're not talking about high transaction rates here, where we care about very quickly getting the answer to a specific query over and over and over again, thousands of times per second, - that's the sort of a problem that NoSQL databases are meant for.
You could solve this problem just by importing your log data into HDFS, but it doesn't involve external databases at all. Once that data is residing on my HDFS cluster, I can write a Spark job that mines that data, assigns the appropriate structure to it, and it can actually run machine learning algorithms on it even using Spark's MLlib.

Just use your Hadoop cluster and the capabilities that the Hadoop ecosystem gives you, without resorting to outside database technologies.
There's no need here to set up an external database at all necessarily, unless you need to vend this data to a very large audience externally. So if you were actually building Google Analytics for real, where you had, you know, millions of people that wanted to hit it and get answers from it at once, then, sure, you'd want to expose that through some sort of an external database system that's integrated with your cluster.
But if you're just using this internally for analytic use, there's no need to even talk about things like NoSQL or Mongo or Cassandra or something like that.

Consistency: it's OK if, for a few seconds after new recommendations have been computed for a user, that you're still getting the old recommendations.
So, thinking back to the CAP theorem, we care about availability, we care about partition tolerance very much, the thing that we're willing to give up, maybe, is consistency.
In that case, Cassandra might be a good choice.

We posed this scenario, where you're building a massive stock trading system, where maybe you want to run a big analytics job on Hadoop or Spark in the background, but you still need to have some sort of a front-end interface to the actual stock trades themselves, so what would be a good choice of a database in this situation?
选择 MongoDB 或者 HBase 都可以。对于 MongoDB, there is a big company behind it that makes its living selling support for it. 另一方面,Now, there are other companies out there that do specialize in offering support for things like HBase or other Apache projects, so don't make that a hard decision there.