Feeding Data to your Cluster - Kafka & Flume
Kafka

What is streaming?

With streaming technologies such as Kafka, you can actually process new data as it's generated into your cluster, maybe you're gonna save it into HDFS, maybe you'll save it into HBase or some other database or maybe you'll actually process it in real time as it comes in.
Usually when we're talking about Big Data, there's a big flow of it coming in all the time and you want to be dealing with it as it comes instead of storing it up and dealing with it in batches.

Enter Kafka

The good thing is that Kafka because it stores it, consumers can catch up from where they last left off, so it will maintain the point where each consumer left off and allow them to just pick up whenever they want to. So it can publish data in real time to your consumers, but if your consumer goes off line or just wants to catch up from some point in the past, it can do that too.
Kafka architecture
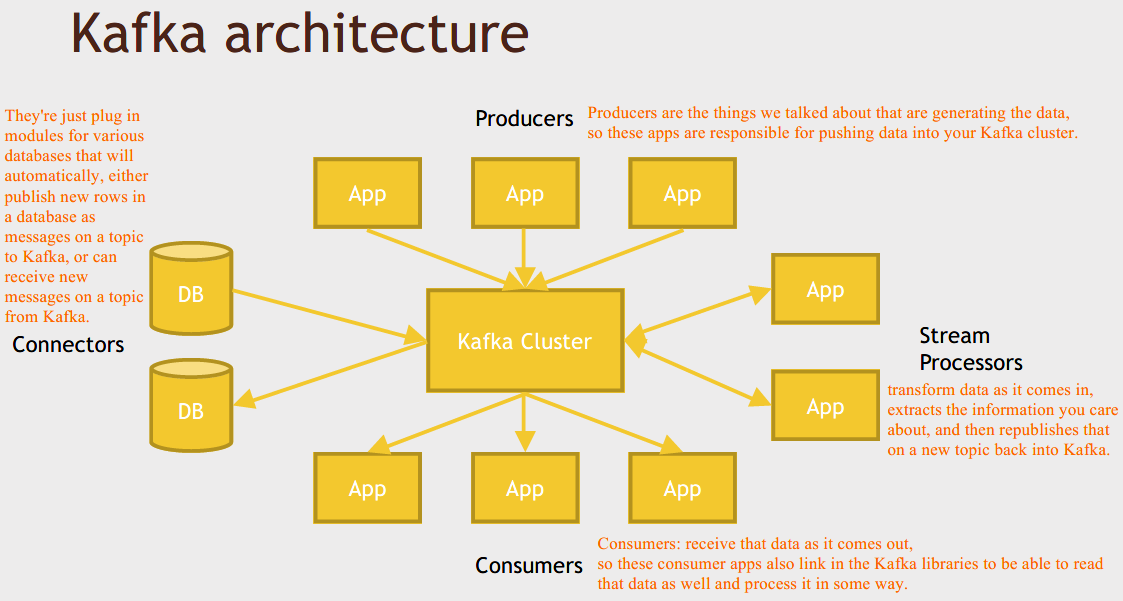
Even though it says app, that doesn't necessarily mean you're going to be developing an app in order to use Kafka, often there are ones you can just use off the shelf and Kafka even comes with some built-in that might serve your purposes.
You can make these pretty fancy systems that are very scalable, very fast, that can transform data and store it, and do whatever you want with it really, as it comes in.
How Kafka scales

Let's play

[Activity] Setting up Kafka, and publishing some data
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963832#overview
Kafka depends on ZooKeeper to keep track of what topics exists.
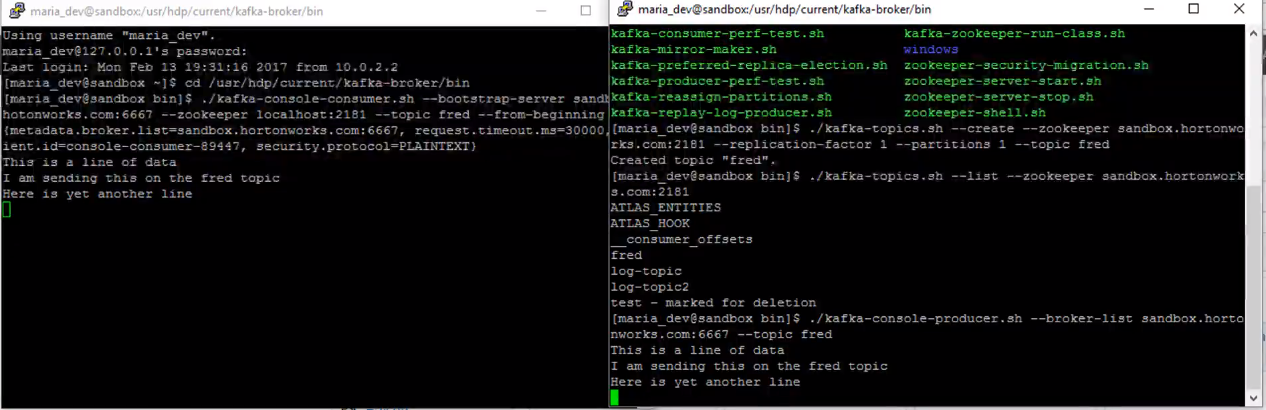
in the real world, this would be massive floods of data coming in from massive web server fleets and things. It can handle that and publish it scalably and reliably to wherever it needs to go. So that's really what it's all about, it's a scalable and reliable mechanism for publishing and subscribing to massive data streams.
[Activity] Publishing web logs with Kafka
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963846#overview
So let's do something a little bit closer to what you might do in reality. Let's use a built-in Kafka connector to actually monitor a file and publish new lines on that file to a given Kafka topic that then get written out to some other file somewhere else.
使用的一些Linux语句:


Flume

What is Flume?
You can really think of Flume as a bonafide part of the Hadoop ecosystem, as opposed to Kafka which is much more general purpose in its design.

Now you might think to yourself "Why can't I just directly transfer data across to my HDFS cluster?" Well, you need some sort of a buffer in between these two things.
Flume Agent
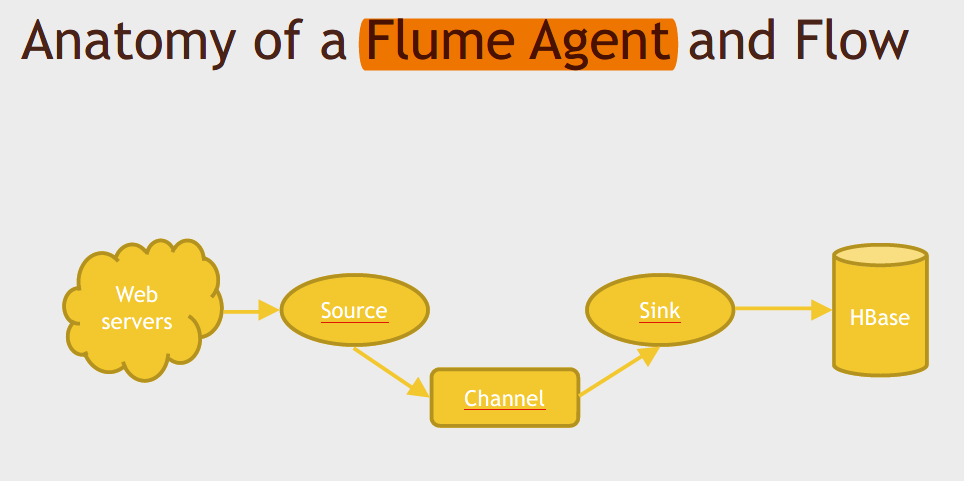

Flume与Kafka的一个区别:It's not really like Kafka where Kafka just stores up data indefinitely and people can pull that data in whenever they want to. Kafka does expire data after some amount of time, but with Flume, basically your sink grabs data from Flume and once it's been grabbed from the channel it gets deleted, so flume does not hang onto your messages or your events any longer than it needs to, as soon as your sync processes it, it throws it away. Kafka is a little bit more easier to set up if you have data going to multiple different places that might be pulling at different rates.
Built-in Source Types

Built-in Sink Types

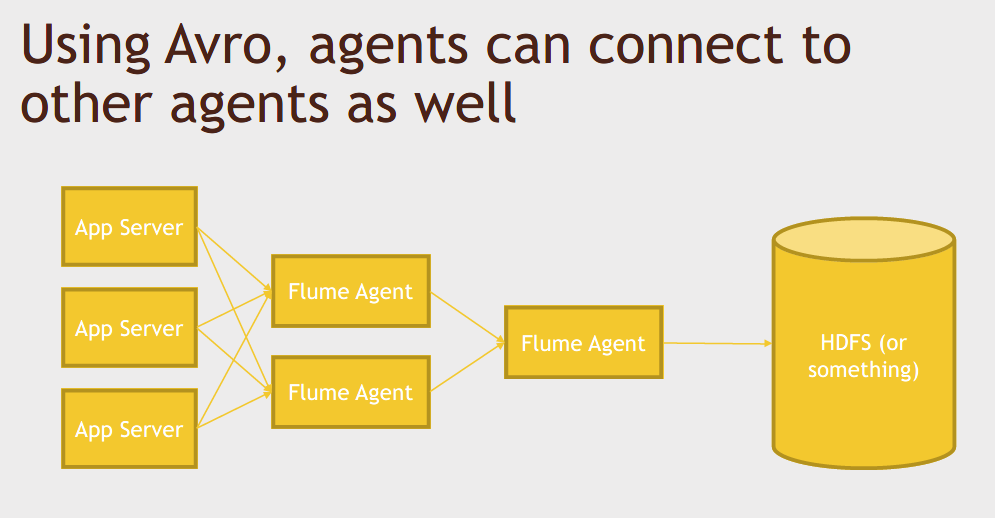

It's basically a way of smoothing out the traffic between the data coming in from your logs or whatever your source might be and where you're writing it to.
Let's play
[Activity] Set up Flume and publish logs with it
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/learn/lecture/5963868#overview
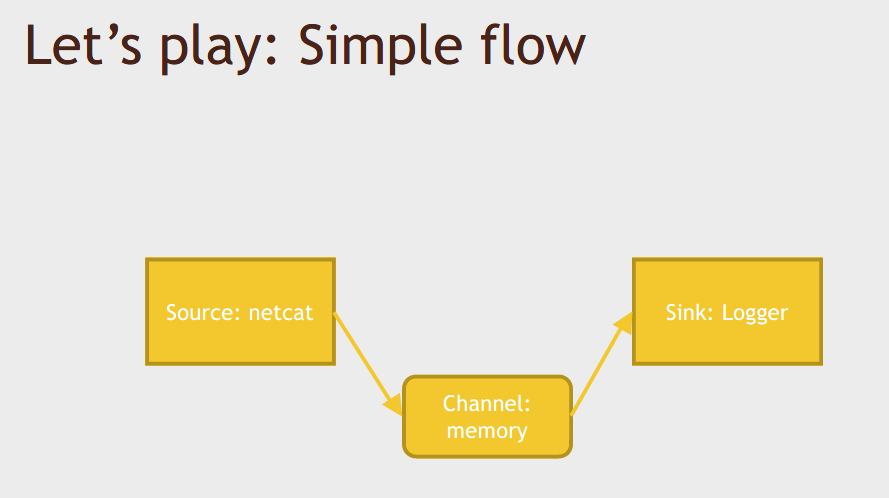
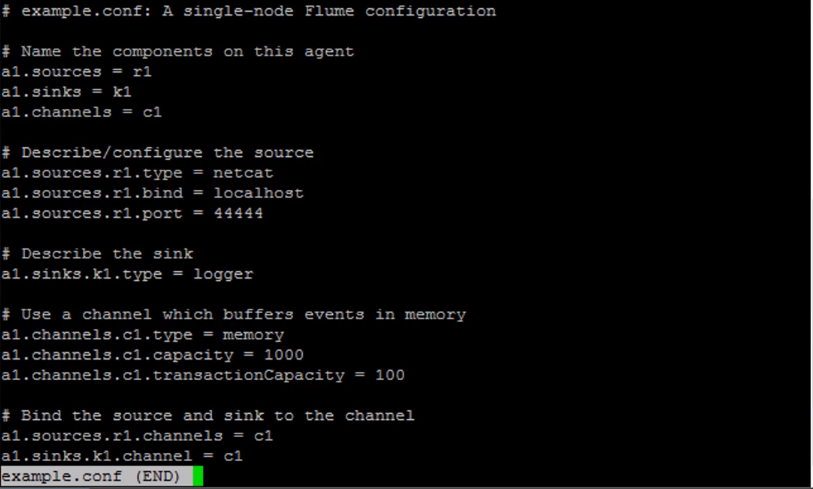
All you really need to do to get Flume running is write a configuration file that defines what sources channels and sinks are associated with each agent that you want in your Flume setup.

[Activity] Set up Flume to monitor a directory and store its data in HDFS
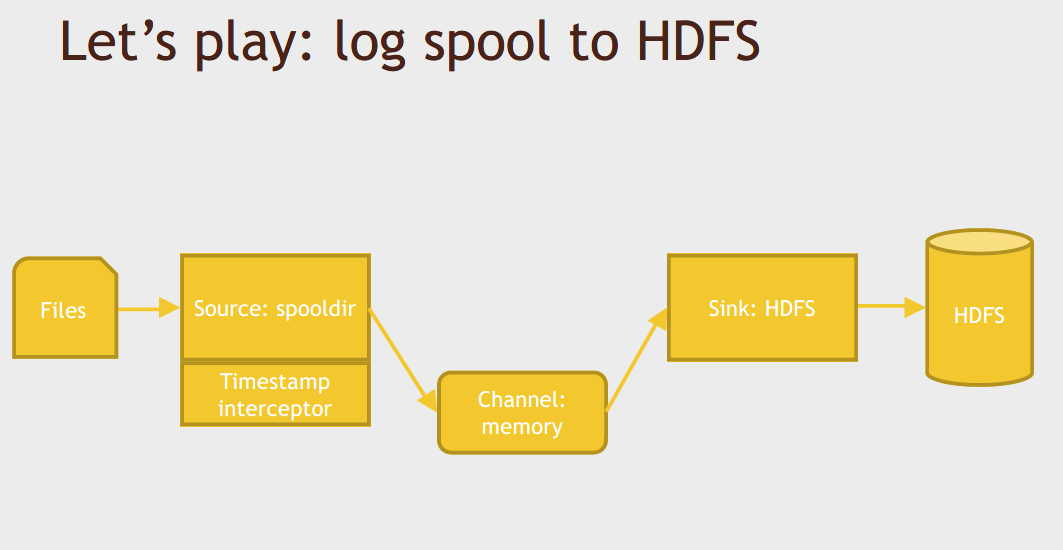
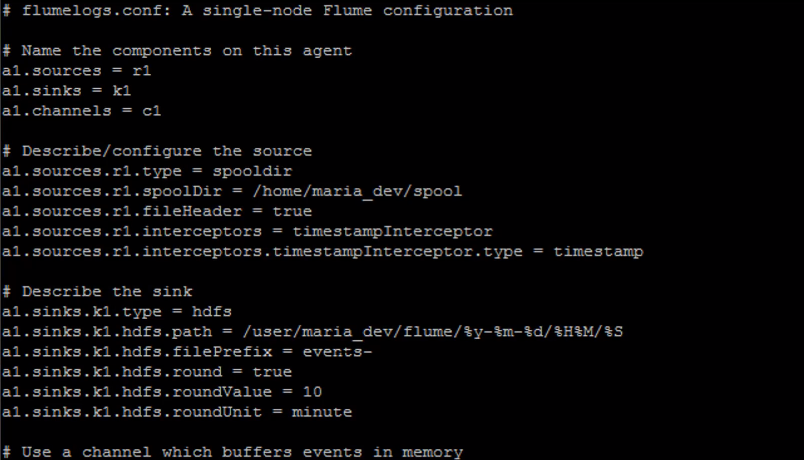
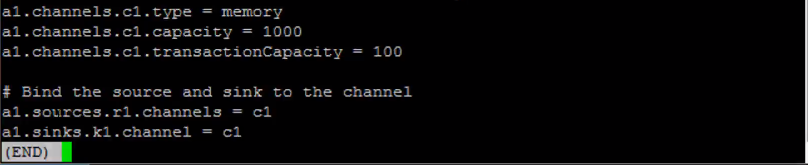
What ends up happening is that we get new subdirectories being generated for each 10 minute interval that goes by.
