决策树
快速导航
C4.5对于ID3所做的改进
CART对于CR.4所做的改进
算法1.1 (信息增益的算法)
算法1.2 (ID3算法)
算法2.1 (C4.5的生成算法)
算法3.1 (CART生成算法)
算法3.2 (CART剪枝算法)
算法3.3 (最小二乘回归树生成算法)
GBDT算法步骤
篇零:决策树的分类
决策树分为两大类:分类树和回归树。前者用于预测离散的具体类别:是否晴天/好坏/网页是否是垃圾网页等等,后者预测的是连续的具体的值:年龄/身高等等。前者的累加是没有意义的比如‘男+男+女=?’,而后者结果的加减是有意义的,‘10+3-6=7’。
1.分类树
决策树的分类算法有很多,以具有最大熵的特征进行分类、以信息增益特征进行分类(ID3)、以增益率特征进行分类(C4.5)、以基尼系数特征进行分类(CART分类与回归树)等等。这一类决策树的特点就是最后的结果都是离散的具体的类别,比如苹果的好/坏,性别男/女。
2.回归树
回归树与分类树的流程大致一样,不同的是回归树在每个节点都会有一个预测值,以年龄为例,该节点的预测值就是所有属于该节点的样本的年龄的均值。
那回归树是根据什么来划分特征的呢?
分类树的最大熵、信息增益、增益率在回归树这都不适用了,回归树用的是均方误差。遍历每个特征,穷举每个特征的划分阈值,而这里不再使用最大熵,使用的是最小化均方差——\((每个人的年龄-预测年龄)^2/N\),N 代表节点内样本数。这很好理解,和预测年龄差距越大,均方差也就越大。因此要找到均方差最小的阈值作为划分点。
划分的结束条件一般有两个:第一是划分到每一个节点都只包含一个年龄值,但是这太难了;第二就是划分到一定的深度就停止,取节点内数据的均值作为最终的预测值。
篇一:决策树 (ID3, C4.5, CART)
本部分内容参考
公众号Datawhale https://mp.weixin.qq.com/s/jj3BtmnWRAwCS56ZU3ZXZA
以及《统计学习方法》和西瓜书
1. ID3
ID3 算法是建立在奥卡姆剃刀(用较少的东西,同样可以做好事情)的基础上:越是小型的决策树越优于大的决策树。
Occam's Razor: Given two models of similar generalization errors, one should prefer the simpler model over the more complex model. For complex models, there is a greater chance that it was fitted accidentally by errors in data.
来自 https://www.ismll.uni-hildesheim.de/lehre//////ml-08w/skript/decision_trees2.pdf
1.1 思想
从信息论的知识中我们知道:信息熵越大,样本纯度越低。ID3 算法的核心思想就是以信息增益来度量特征选择,选择信息增益最大的特征进行分裂。算法采用自顶向下的贪婪搜索,遍历可能的决策树空间(C4.5 也是贪婪搜索 ).
其大致步骤为:
- 初始化特征集合和数据集合;
- 计算数据集合信息熵和所有特征的条件熵,选择信息增益最大的特征作为当前决策节点;
- 更新数据集合和特征集合(删除上一步使用的特征,并按照特征值来划分不同分支的数据集合);
- 重复 2,3 两步,若子集值包含单一特征,则为分支叶子节点。
更详细步骤见 1.2.2 ID3算法.
1.2 划分标准
ID3 使用的分类标准是信息增益,它表示得知特征 A 的信息而使得样本集合不确定性减少的程度。
一般而言,信息增益越大,意味着使用特征 A 来划分所获得的“纯度提升“越大。
最优划分属性 \(a^*=argmax _{a ∈ A}\ Gain(D,a)\).
1.2.1 信息增益
以下内容来自《统计学习方法》和《数学之美》
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量,设 \(X\) 是一个取有限个值的离散随机变量,其概率分布为 \[ P(X=x_i)=p_i,i=1,2,...,n \] 则随机变量 \(X\) 的熵定义为 \[ H(X)=-\sum_{i=1}^n p_i\log p_i \] 若 \(p_i=0\),则定义 \(0\log0=0\)。通常对数以2为底或以e为底,这时熵的单位分别称作比特(bit)或纳特(nat)。由定义可知,熵只依赖于 \(X\) 的分布,而与 \(X\) 的取值无关,所以也可将 \(X\) 的熵记作 \(H(p)\),即 \[ H(p)=-\sum_{i=1}^n p_i\log p_i \] 熵越大,随机变量的不确定性就越大,要把它搞清楚,所需要的信息量也就越大。从定义可验证 \[ 0 \leq H(p) \leq \log n \]
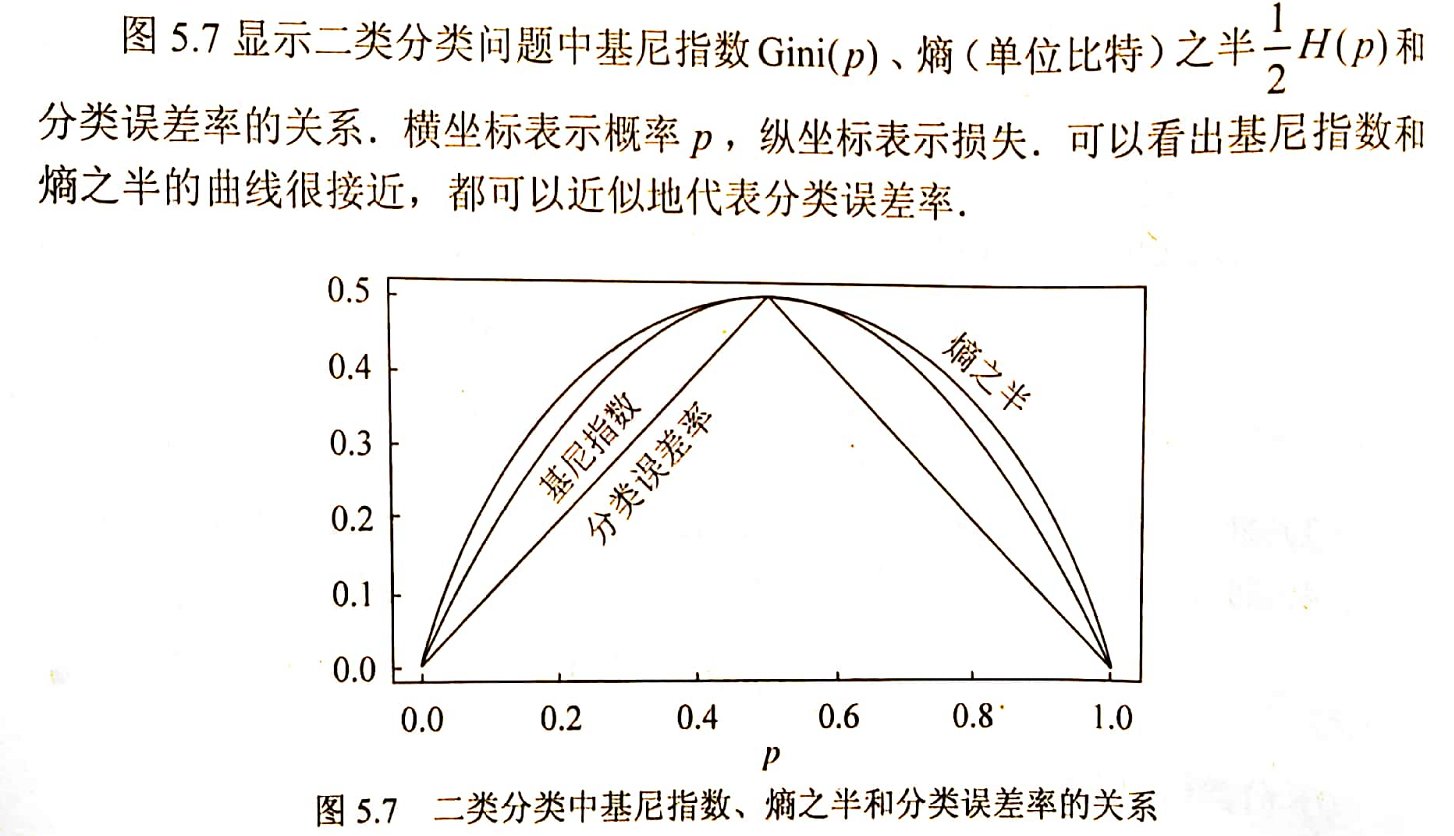
当随机变量只取两个值,例如1,0时,即 \(X\) 的分布为 \[ P(X=1)=p, \ P(X=0)=1-p, \quad 0\leq p\leq 1 \] 熵为 \[ H(p)=-p\log_2p-(1-p)\log_2(1-p) \] 这时,熵 \(H(p)\) 随概率 \(p\) 变化的曲线如下图所示(单位为比特)
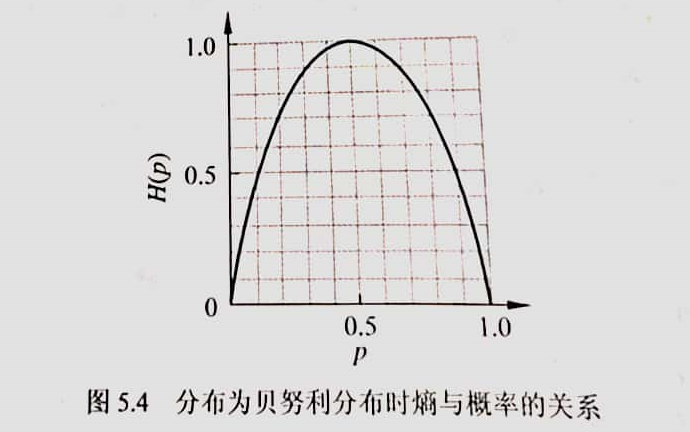
当 \(p=0\) 或 \(p=1\) 时 \(H(p)=0\),随机变量完全没有不确定性。当 \(p=0.5\) 时,\(H(p)=1\),熵取值最大,随机变量不确定性最大。
设有随机变量 \((X,Y)\),其联合概率分布为 \[ P(X=x_i,Y=y_i)=p_{ij},\quad i=1,2,...,n;j=1,2,...,m \] 随机变量 \(X\) 给定条件下随机变量 \(Y\) 的条件熵(conditional entropy)\(H(Y|X)\),表示在已知随机变量 \(X\) 的条件下随机变量 \(Y\) 的不确定性,定义为 \(X\) 给定条件下 \(Y\) 的条件概率分布的熵对 \(X\) 的数学期望 \[ \begin{align*} H(Y|X) &= -\sum_{x\in X,y\in Y}p(x,y)logp(x,y)\\ &=\sum_{i=1}^n p_iH(Y|X=x_i) \end{align*} \] 这里,\(p_i=P(X=x_i),\quad i=1,2,...,n.\)
可以证明, \(H(Y)\geq H(Y|X)\),也就是说多了 \(X\) 的信息之后,关于 \(Y\) 的不确定性下降了。在统计语言模型中,如果把 \(X\) 看成前一个字,那么在数学上就证明了二元模型的不确定性小于一元模型。同理,可以定义有两个条件的条件熵 \[ H(X|Y,Z)=-\sum_{x\in X,y\in Y,z\in Z}p(x,y,z)logp(x,y,z) \] 还可以证明, \(H(X|Y)\geq H(X|Y,Z)\)。也就是说,三元模型应该比二元好。
上述的等号什么时候成立?等号成立说明增加了信息,不确定性却没有降低。如果我们获取的信息与要研究的事物毫无关系,等号就成立。
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy). 此时,如果有概率0,令0log0=0 .
信息增益(information gain)表示得知特征\(X\)的信息而使得类\(Y\)的信息的不确定性减少的程度。
定义(信息增益) 特征 \(A\) 对训练数据集 \(D\) 的信息增益 \(g(D,A)\) ,定义为集合 \(D\) 的经验熵 \(H(D)\) 与特征 \(A\) 给定条件下 \(D\) 的经验条件熵 \(H(D|A)\) 之差,即 \[ g(D,A)=H(D)-H(D|A) \]
一般地,熵 \(H(Y)\) 与条件熵 \(H(Y|X)\) 之差称为互信息(mutual information). 决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
决策树学习应用信息增益准则选择特征。给定训练数据集 \(D\) 和特征 \(A\),经验熵 \(H(D)\) 表示对数据集 \(D\) 进行分类的不确定性。而经验条件熵 \(H(D|A)\) 表示在特征 \(A\) 给定的条件下对数据集 \(D\) 进行分类的不确定性。它们的差,即信息增益,就表示由于特征 \(A\) 而使得对数据集 \(D\) 的分类的不确定性减少的程度。显然,对于数据集 \(D\) 而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益。信息增益大的特征具有更强的分类能力。
根据信息增益准则的特征选择方法是:对训练数据集(或子集)\(D\),计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。
设训练数据集为 \(D\),\(|D|\) 表示其样本容量,即样本个数。设有 \(K\) 个类 \(C_k,k=1,2,...,K\),\(|C_k|\) 为属于类\(C_k\)的样本个数,\(\sum_{k=1}^K |C_k|=|D|.\) 设特征 \(A\) 有 \(n\) 个不同的取值 \(\{a_1,a_2,...,a_n\}\),根据特征 \(A\) 的取值将 \(D\) 划分为 \(n\) 个 \(D_1,D_2,...,D_n,|D_i|\) 为 \(D_i\) 的样本个数,\(\sum_{i=1}^n|D_i|=|D|.\) 记子集 \(D_i\) 中属于类 \(C_k\) 的样本的集合 \(D_{ik}\),即 \(D_{ik}=D_i∩C_k, |D_{ik}|\) 为 \(D_{ik}\) 的样本个数。于是信息增益的算法如下:
算法 1.1(信息增益的算法)
输入:训练数据集 \(D\) 和特征 \(A\) 输出:特征 \(A\) 对训练数据集 \(D\) 的信息增益 \(g(D,A)\)
(1)计算数据集 \(D\) 的经验熵 \(H(D)\) \[ H(D)=-\sum_{k=1}^K \frac{|C_k|}{|D|}log_2\frac{|C_k|}{|D|} \] (2)计算特征 \(A\) 对数据集 \(D\) 的经验条件熵 \(H(D|A)\) \[ H(D|A) = \sum_{i=1}^n \frac{|D_i|}{|D|}H(D_i)=- \sum_{i=1}^n \frac{|D_i|}{|D|} \sum_{k=1}^K \frac{|D_{ik}|}{|D_i|}log_2 \frac{|D_{ik}|}{|D_i|} \] (3)计算信息增益 \[ g(D,A)=H(D)-H(D|A) \]
1.2.2 ID3算法
以下内容来自《统计学习方法》
ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决策树。ID3相当于用极大似然法进行概率模型的选择。
算法 1.2 (ID3算法)
输入:训练数据集 \(D\),特征集 \(A\),阈值 \(\varepsilon\) 输出:决策树 \(T\).
(1)若 \(D\) 中所有实例属于同一类 \(C_k\),则 \(T\) 为单结点树,并将类 \(C_k\) 作为该结点的类标记,返回 \(T\) (2)若 \(A=\varnothing\),则 \(T\) 为单结点树,并将 \(D\) 中实例数最大的类 \(C_k\) 作为该结点的类标记,返回 \(T\) (3)否则,按算法1.1计算 \(A\) 中各特征对 \(D\) 的信息增益,选择信息增益最大的特征 \(A_g\) (4)若 \(A_g\) 的信息增益小于阈值 \(\varepsilon\),则置 $ T$ 为单结点树,并将 \(D\) 中实例数最大的类 \(C_k\) 作为该结点的类标记,返回 \(T\) (5)否则,对 \(A_g\) 的每一可能值 \(a_i\),依 \(A_g=a_i\) 将 \(D\) 分割为若干非空子集 \(D_i\),将 \(D_i\) 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树 \(T\),返回 \(T\) (6)对第 \(i\) 个子结点,以 \(D_i\) 为训练集,以 \(A-\{A_g\}\) 为特征集递归地调用步(1) ~ 步(5),得到子树 \(T_i\),返回 \(T_i\)
例:对表5.1的训练数据集,利用ID3算法建立决策树


1.3 缺点
- ID3 没有剪枝策略,该算法生成的树容易过拟合;
- 信息增益准则对可取值数目较多的特征有所偏好,类似“编号”的特征其信息增益接近于 1(但实际上这并不是一个好的特征选择);
- 只能用于处理离散分布的特征;
- 没有考虑缺失值。
2. C4.5
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题。 C4.5 算法最大的特点是克服了 ID3 对特征数目的偏重这一缺点,引入信息增益率来作为分类标准。
2.1 思想
C4.5 相对于 ID3 的缺点对应有以下改进方式:
引入悲观剪枝策略进行后剪枝;
引入信息增益率作为划分标准;
将连续特征离散化,假设 n 个样本的连续特征 A 有 m 个取值,C4.5 将其排序并取相邻两样本值的平均数共 m-1 个划分点,分别计算以该划分点作为二元分类点时的信息增益,并选择信息增益最大的点作为该连续特征的二元离散分类点;(具体内容见 2.4 连续值处理)
对于缺失值的处理可以分为两个子问题:1. 在特征值缺失的情况下如何进行划分特征的选择?(即如何计算特征的信息增益率)2. 选定该划分特征,对于缺失该特征值的样本如何处理?(即到底把这个样本划分到哪个结点里)(具体内容见 2.5 缺失值处理)
针对问题一,C4.5 的做法是:对于具有缺失值特征,用没有缺失的样本子集所占比重来折算;
针对问题二,C4.5 的做法是:将样本同时划分到所有子节点,不过要调整样本的权重值,其实也就是以不同概率划分到不同节点中。
2.2 划分标准
2.2.1 信息增益率

👆(intrinsic value)
\(H_A(D)\)表示训练数据集 \(D\) 关于特征 \(A\) 的值的熵,\(n\) 是特征 \(A\) 取值的个数。特征 \(A\) 的可能取值数目越大(即n越大),则 \(H_A(D)\) 的值通常会越大。
这里需要注意,信息增益率对可取值较少的特征有所偏好(分母越小,整体越大),因此 C4.5 并不是直接用增益率最大的特征进行划分,而是使用一个启发式方法:先从候选划分特征中找到信息增益高于平均值的特征,再从中选择增益率最高的。
2.2.2 C4.5算法
算法 2.1 (C4.5的生成算法)
输入:训练数据集 \(D\),特征集 \(A\),阈值 \(\varepsilon\) 输出:决策树 \(T\)
(1)如果 \(D\) 中所有实例属于同一类 \(C_k\),则置 \(T\) 为单结点树,并将 \(C_k\)作为该结点的类,返回 \(T\) (2)如果 \(A=\varnothing\),则直 \(T\) 为单结点树,并将 \(D\) 中实例数最大的类 \(C_k\) 作为该结点的类,返回 \(T\) (3)否则,计算 \(A\) 中各特征对 \(D\) 的信息增益率,选择信息增益率最大的特征 \(A_g\) (4)若 \(A_g\) 的信息增益率小于阈值 \(\varepsilon\),则置 $ T$ 为单结点树,并将 \(D\) 中实例数最大的类 \(C_k\) 作为该结点的类标记,返回 \(T\) (5)否则,对 \(A_g\) 的每一可能值 \(a_i\),依 \(A_g=a_i\) 将 \(D\) 分割为若干非空子集 \(D_i\),将 \(D_i\) 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树 \(T\),返回 \(T\) (6)对第 \(i\) 个子结点,以 \(D_i\) 为训练集,以 \(A-\{A_g\}\) 为特征集递归地调用步(1) ~ 步(5),得到子树 \(T_i\),返回 \(T_i\).
2.3 剪枝策略
为什么要剪枝:过拟合的树泛化能力表现非常差。
以下内容来自西瓜书
剪枝(pruning)是决策树学习算法对付过拟合的主要手段。在决策树学习中,为例尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得“太好”了,以致于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。
剪枝的基本策略有“预剪枝”(pre-pruning)和“后剪枝”(post-pruning). 预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
如何判断决策树泛化性能是否提升呢?可采用留出法,即预留一部分数据用作“验证集”以进行性能评估。
2.3.1 预剪枝
在节点划分前来确定是否继续增长,及早停止增长的主要方法有:
- 节点内数据样本低于某一阈值;
- 所有节点特征都已分裂;
- 节点划分前准确率比划分后准确率高。
预剪枝不仅可以降低过拟合的风险而且还可以减少训练时间,但另一方面它是基于“贪心”策略,会带来欠拟合风险。

(👆 https://www.ismll.uni-hildesheim.de/lehre//////ml-08w/skript/decision_trees2.pdf)
以下内容来自西瓜书
例子:
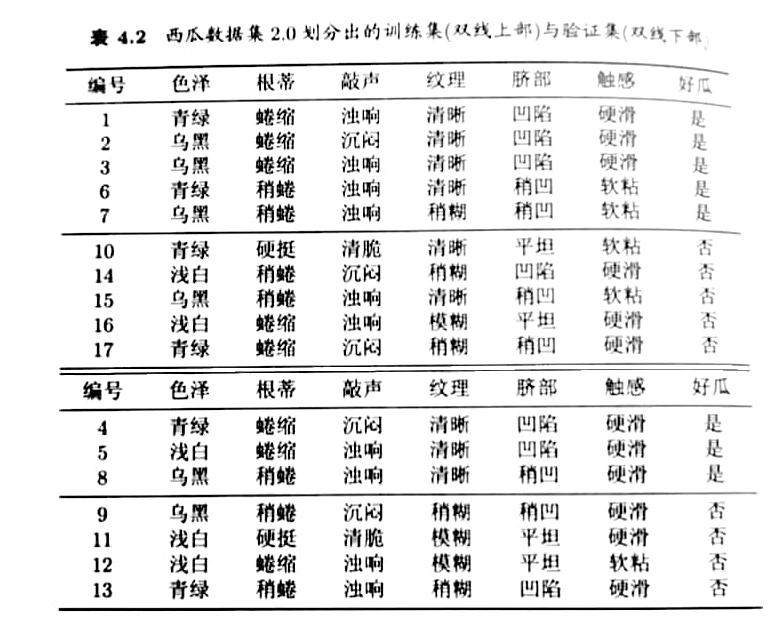
假定采用信息增益准则进行划分属性选择,则从表4.2的训练集将会生成一棵如图4.5所示的决策树。
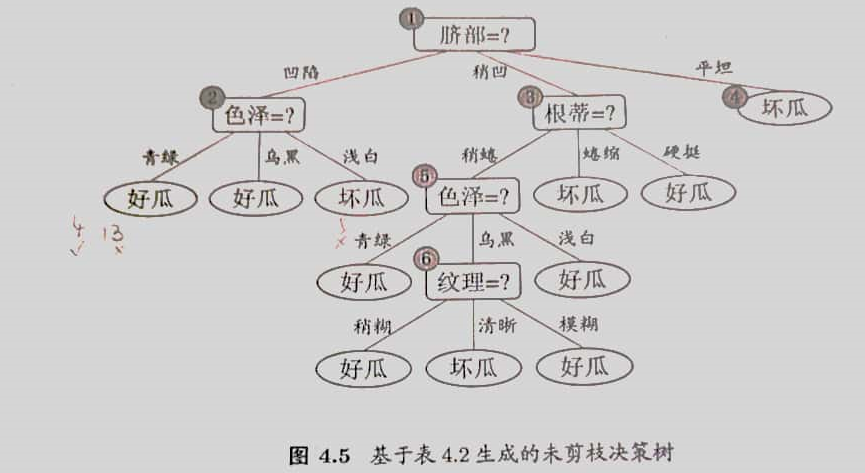
基于信息增益准则,我们会选取属性“脐部”来对训练集进行划分,并产生3个分支,如图4.6所示。然而,是否应该进行这个划分呢?预剪枝要对划分前后的泛化性能进行评估。
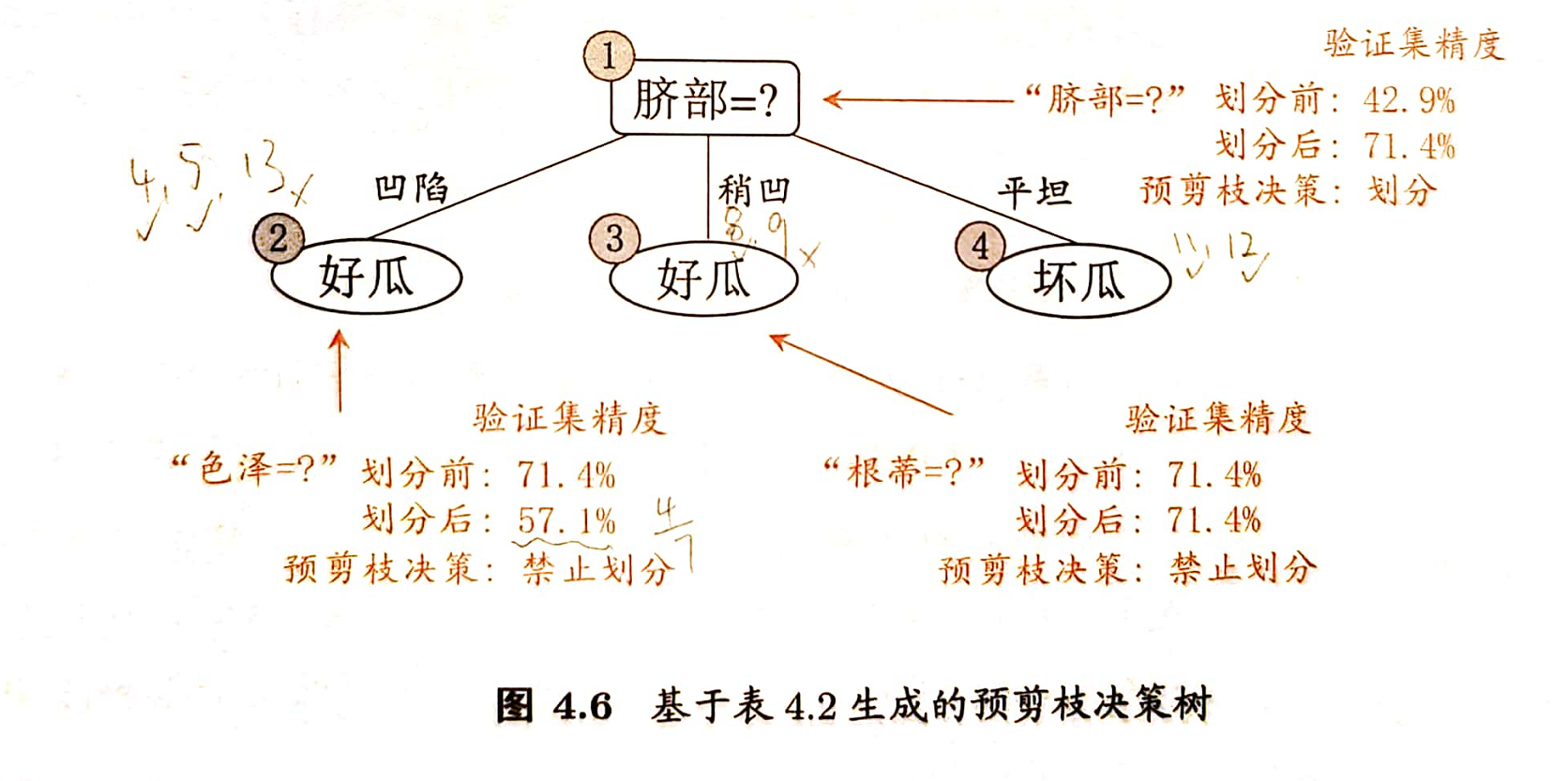
在划分之前,所有样例集中在根结点。若不进行划分,该结点将被标记为叶结点,其类别标记为训练样例数最多的类别,假设我们将这个叶结点标记为“好瓜”(当样例最多的类不唯一时,可任选其中一类). 用表4.2的验证集对这个单结点决策树进行评估,编号为{4,5,8}的样例被分类正确,另外4个样例分类错误,于是验证集的精度为 \(\frac{3}{7}\times 100\%=42.9\%\).
在用属性“脐部”划分之后,图4.6中的结点②、③、④分别包含编号为 {1,2,3,14}, {6,7,15,17}, {10,16}的训练样例,因此这3个结点分别被标记为叶结点“好瓜”,“好瓜”,“坏瓜”。此时,验证集中编号为 {4,5,8,11,12}的样例被分类正确,验证集精度为 \(\frac{5}{7}\times 100\%=71.4\% > 42.9\%\). 于是,用“脐部”进行划分得以确定。
然后,决策树算法对结点②进行划分,基于信息增益准则将挑选出属性“色泽”。然而,在使用“色泽”划分后,编号为 {5} 的验证集样本分类结果会由正确转为错误,(其余样本分类结果不变)使得验证集精度下降为 57.1%. 于是,预剪枝策略将禁止结点②被划分。
对结点③,最优划分属性为“根蒂”,划分后验证集精度仍为71.4%. 这个划分不能提升验证集精度,于是,预剪枝策略禁止结点③被划分。
对结点④,其所含训练样例已属于同一类,不再进行划分。
于是,基于预剪枝策略从表4.2数据所生成的决策树如图4.6所示,其验证集精度为71.4%.
对比图4.6和图4.5可以看出,预剪枝使得决策树的很多分支都没有“展开”,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间开销。但另一方面,有些分支的当前划分虽不能提升泛化性能,甚至可能导致泛化性能暂时下降,但在其基础上进行的后续划分却有可能导致性能显著提高;预剪枝基于“贪心”本质禁止这些分支展开,给预剪枝决策树带来了欠拟合的风险。
2.3.2 后剪枝
后剪枝是人们普遍关注的决策树剪枝策略,与预剪枝恰好相反,后剪枝的执行步骤是先构造完成完整的决策树,再通过某些条件遍历树进行剪枝,其主要思路是通过删除节点的分支并用叶节点替换,剪去完全成长的树的子树,这个节点所标识的类别通过大多数原则(majority class criterion)确定(既将一些子树删除而用叶子节点代替,这个叶节点所表示的类别用这棵子树中的大多数训练样本所属类别来进行标识)。

(👆 https://www.ismll.uni-hildesheim.de/lehre//////ml-08w/skript/decision_trees2.pdf)
目前主要应用的后剪枝方法有四种:
- 悲观错误剪枝(Pessimistic Error Pruning,PEP)
- 最小错误剪枝(Minimum Error Pruning,MEP)
- 代价复杂度剪枝(Cost-Complexity Pruning,CCP)
- 基于错误的剪枝(Error-Based Pruning,EBP),也叫错误率降低剪枝(Reduced Error Pruning, REP)
(👆 来自 https://zhuanlan.zhihu.com/p/165647069)

C4.5 采用的悲观错误剪枝,CART采用的代价复杂度剪枝
2.3.2.1 基于错误的剪枝
参考 https://www.cnblogs.com/zhangchaoyang/articles/2842490.html
这个思路很直接,完全的决策树不是过度拟合么,我再搞一个测试数据集来纠正它。对于完全决策树中的每一个非叶子节点的子树,我们尝试着把它替换成一个叶子节点,该叶子节点的类别我们用子树所覆盖训练样本中存在最多的那个类来代替,这样就产生了一个简化决策树,然后比较这两个决策树在测试数据集中的表现,如果简化决策树在测试数据集中的错误比较少,并且该子树里面没有包含另外一个具有类似特性的子树(所谓类似的特性,指的就是把子树替换成叶子节点后,其测试数据集误判率降低的特性),那么该子树就可以替换成叶子节点。该算法以bottom-up的方式遍历所有的子树,直至没有任何子树可以替换使得测试数据集的表现得以改进时,算法就可以终止。
以下内容来自西瓜书
基于表4.2的数据得到如图4.5的决策树。易知,该决策树的验证集精度为 42.9%. 如下展示的后剪枝为基于错误的后剪枝(EBP)?

2.3.2.2 悲观错误剪枝
参考
https://www.cnblogs.com/zhangchaoyang/articles/2842490.html
https://blog.csdn.net/weixin_41647586/article/details/89052754
https://www.ismll.uni-hildesheim.de/lehre//////ml-08w/skript/decision_trees2.pdf
基于错误的剪枝方法很直接,但是需要一个额外的测试数据集,能不能不要这个额外的数据集呢?为了解决这个问题,于是就提出了悲观剪枝。该方法和基于错误的剪枝思路是一致的,不同之处在于如何估计泛化误差。
把一颗子树(具有多个叶子节点)的分类用一个叶子节点来替代的话,在训练集上的误判率肯定是上升的(这是显然的,同样的样本子集,如果用子树分类可以分成多个类,而用单颗叶子节点来分的话只能分成一个类,多个类肯定要准确一些),但是在新数据上不一定。于是我们需要对子树的误判数加上一个经验性的惩罚因子。对于一颗叶子节点,假设它覆盖了N个样本,其中有E个错误,那么该叶子节点的错误率为(E+0.5)/N。这个0.5就是惩罚因子。那么一颗子树,它有L个叶子节点,那么该子树的误判率估计为
\(\frac{\sum_{i=1}^L E_i+0.5*L}{\sum_{i=1}^L
N_i}\)。剪枝后内部节点变成了叶子节点,其误判个数 J
也需要加上一个惩罚因子,变成 J+0.5。

一句话概括,基于错误的剪枝利用额外的测试集去估计泛化误差,悲观剪枝直接利用训练集估计泛化误差
子树是否可以被剪枝取决于剪枝后的错误 J+0.5 是否在 \(\sum_{i=1}^L E_i+0.5*L\) 的标准差内。对于样本的误差率 e,我们可以根据经验把它估计成各种各样的分布模型,比如是二项式分布、正态分布。
那么一棵树错误分类一个样本值为1,正确分类一个样本值为0,该树错误分类的概率(误判率)为e(e为分布的固有属性,可以通过 \(\frac{\sum_{i=1}^L E_i+0.5*L}{\sum_{i=1}^L N_i}\) 统计出来),那么树的误判次数就是伯努利分布,我们可以估计出该树的误判次数均值和标准差:
\[ \begin{align*} E(subtree\_err\_count)&=N∗e \\ std(subtree\_err\_count)&=N∗e∗(1−e) \end{align*} \]
把子树替换成叶子节点后,该叶子的误判次数也是一个伯努利分布,其概率误判率e为(E+0.5)/N,因此叶子节点的误判次数均值为 \[ E(leaf\_err\_count)=N∗e \]
这里我们采用一种保守的分裂方案,即有足够大的置信度保证分裂后准确率比不分裂时的准确率高时才分裂,否则就不分裂,也就是应该剪枝。如果要分裂(即不剪枝),至少要保证分裂后的误判数E(subtree_err_count)要小于不分裂的误判数E(leaf_err_count),而且为了保证足够高的置信度,这里甚至要是 \[ E(subtree\_err\_count)+std(subtree\_err\_count)<E(leaf\_err\_count) \] 这里加了一个标准差可以有95%的置信度。
反之就是不分裂,即剪枝的条件: \[ E(subtree\_err\_count)+std(subtree\_err\_count)>E(leaf\_err\_count) \] (此处公式存疑,看到许多不同的说法)
例: 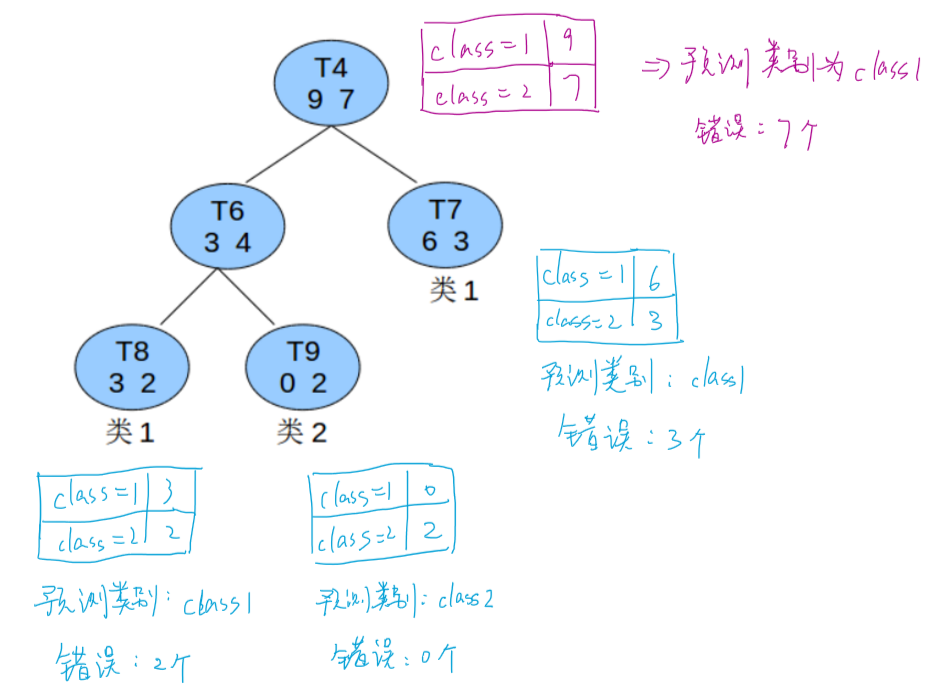
T4这棵子树的误差率:(即分裂后的误差率) \[ \frac{(2+3)+0.5∗3}{16}=0.40625 \] 子树误差率的标准差: \[ \sqrt{16*0.40625*(1-0.40625)}=1.96 \] 子树替换为一个叶节点后,其误差率为:(即分裂前的误差率) \[ \frac{7+0.5}{16}=0.46875 \]
因为 \(16∗0.40625+1.96=8.46>16∗0.46875=7.5\),所以应该把T4的所有子节点全部剪掉,T4变成一个叶子节点。
C4.5 采用悲观剪枝方法,用递归的方式从底往上针对每一个非叶子节点,评估用一个最佳叶子节点去代替这课子树是否有益。如果剪枝后与剪枝前相比其错误率是保持或者下降,则这棵子树就可以被替换掉。C4.5 通过训练数据集上的错误分类数量来估算未知样本上的错误率。
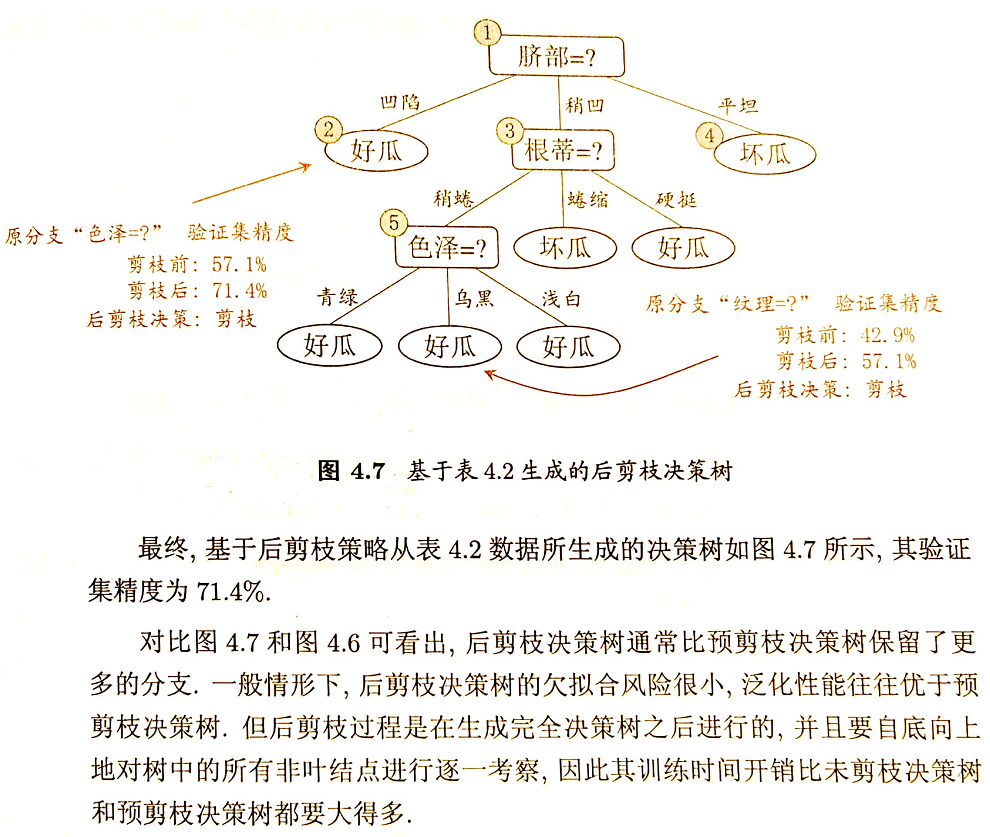
后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。但同时其训练时间会大的多。
2.4 连续值处理
以下内容来自西瓜书
到目前为止我们仅讨论了基于离散属性来生成决策树。现实学习任务中常会遇到连续属性,有必要讨论如何在决策树学习中使用连续属性。
由于连续属性的可取值数目不再有限,因此不能直接根据连续属性的可取值来对结点进行划分。此时,连续属性离散化技术可派上用场。最简单的策略是采用二分法(bi-partition)对连续属性进行处理,这正是C4.5决策树算法中采用的机制。(不再是根据"特征A = xxx"来划分,而是"特征A<=xxx"来划分)
给定样本集 \(D\) 和连续属性 \(a\),假定 \(a\) 在 \(D\) 上出现了 \(n\) 个不同的取值,将这些值从小到大进行排序,记为 \(\{a^1,a^2,...,a^n \}\). 基于划分点 \(t\) 可将 \(D\) 分为子集 \(D_t^-\) 和 \(D_t^+\),其中 \(D_t^-\) 包含那些在属性 \(a\) 上取值不大于 \(t\) 的样本,而 \(D_t^+\) 则包含那些在属性 \(a\) 上取值大于 \(t\) 的样本。显然,对相邻的属性取值 \(a^i\)与 \(a^{i+1}\) 来说,\(t\) 在区间 \([a^i,a^{i+1})\) 中取任意值所产生的划分结果相同。因此,对连续属性 \(a\),我们可考察包含 \(n-1\) 个元素的候选划分点集合 \[ T_a=\{\frac{a^i+a^{i+1}}{2}|1\leq i \leq n-1 \}. \] 即把区间 \([a^i,a^{i+1})\) 的中位点 \(\frac{a^i+a^{i+1}}{2}\)作为候选划分点。
可将划分点设为该属性在训练集中出现的不大于中位点的最大值,从而使得最终决策树使用的划分点都在训练集中出现过
然后就可以像离散属性值一样来考察这些划分点,选取最优的划分点进行样本集合的划分。例如: \[ Gain(D,a)=\max_{t∈T_a} Gain(D,a,t)=\max_{t∈T_a} Ent(D) - \sum_{\lambda∈\{-,+\}} \frac{|D_t^\lambda|}{|D|}Ent(D_t^\lambda) \] 其中 \(Gain(D,a,t)\) 是样本集 \(D\) 基于划分点 \(t\) 二分后的信息增益。于是,我们就可选择使 \(Gain(D,a,t)\) 最大化的划分点。
例:
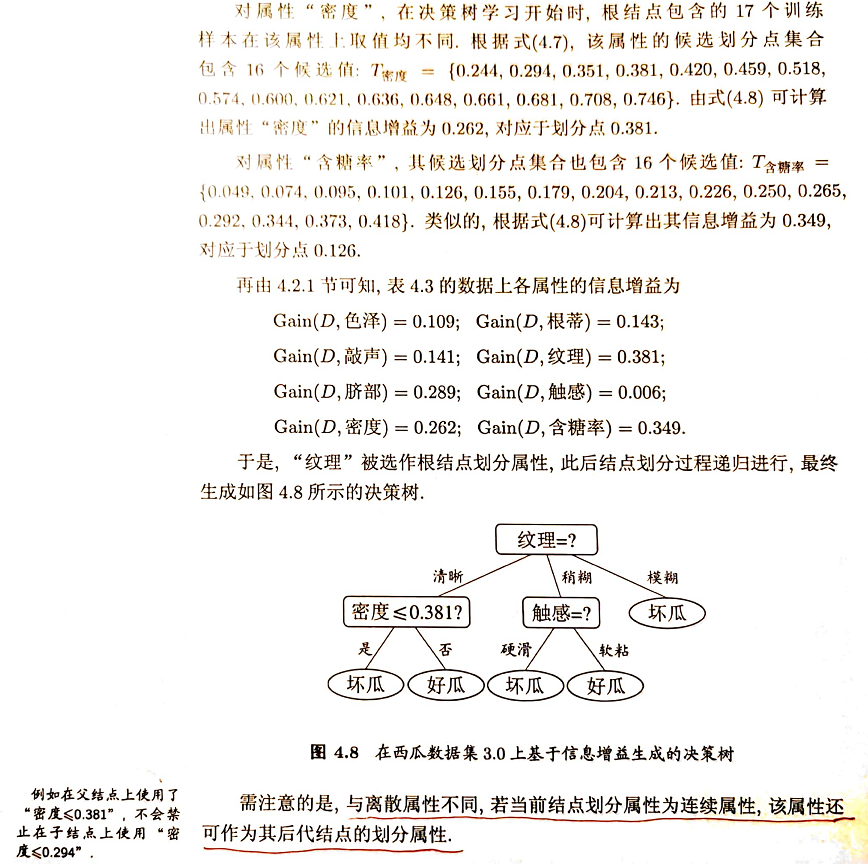
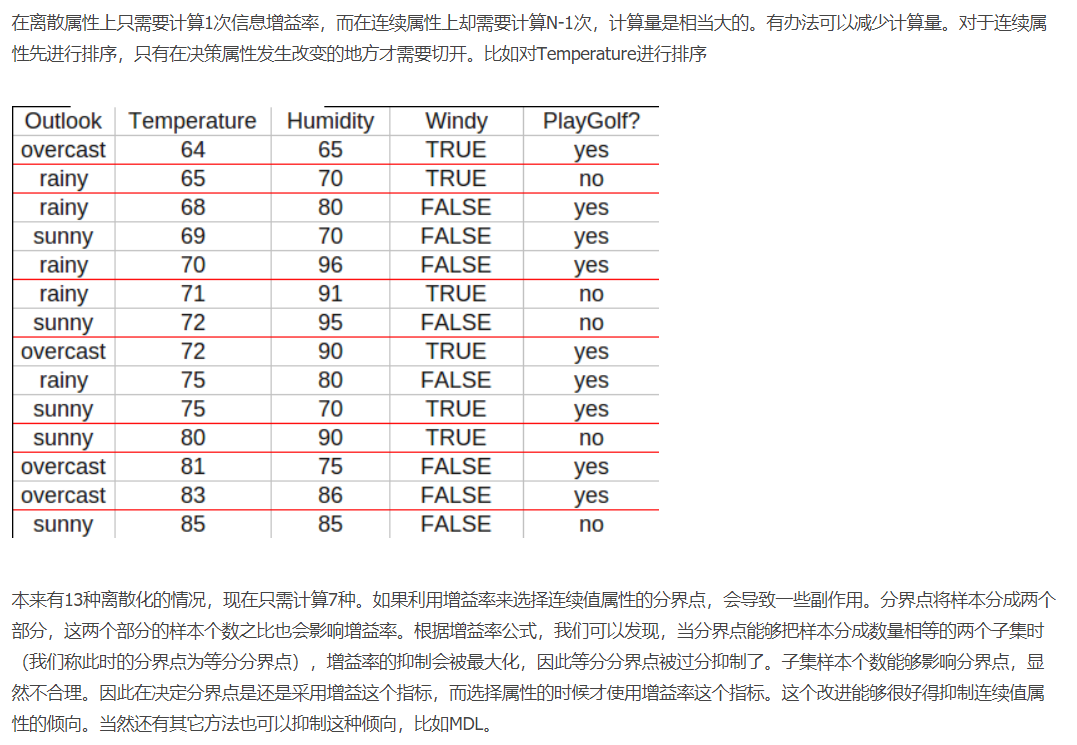
(👆 来自 https://www.cnblogs.com/zhangchaoyang/articles/2842490.html)
2.5 缺失值处理
以下内容来自西瓜书
现实任务中常会遇到不完整样本,即样本的某些属性值缺失。若简单地放弃不完整样本,仅使用无缺失值的样本来进行学习,显然是对数据信息极大的浪费。例如,表4.4中,若放弃不完整样本,则仅有编号 {4,7,14,16} 的4个样本能被使用。显然,有必要考虑利用缺失属性值的训练样例来进行学习。
我们需解决两个问题:
(1)如何在属性值缺失的情况下进行划分属性选择? (2)给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
给定训练集 \(D\) 和属性 \(a\),令 \(\tilde D\) 表示 \(D\) 中在属性 \(a\) 上没有缺失值的样本子集。对问题(1),显然我们仅可根据 \(\tilde D\) 来判断属性 \(a\) 的优劣.假定属性 \(a\) 有 \(V\) 个可取值 \(\{ a^1,a^2,...,a^V\}\),令 \(\tilde D^v\) 表示 \(\tilde D\) 中在属性 \(a\)上取值为 \(a^v\) 的样本子集,\(\tilde D_k\) 表示 \(\tilde D\) 中属于第 \(k\) 类 (\(k=1,2,...,K\)),则显然有 \(\tilde D = \cup _{k=1}^K \tilde D_k, \tilde D = \cup _{v=1}^V \tilde D^v\). 假定我们为每个样本 \(x\) 赋予一个权重 \(w_x\)(在决树学习开始阶段,根结点中各样本的权重初始化为1),并定义 \[ \begin{align*} \rho &= \frac{\sum_{x\in \tilde D} w_x}{\sum_{x \in D}w_x},\\ \tilde p_k &= \frac{\sum_{x\in \tilde D_k} w_x}{\sum_{x\in \tilde D} w_x} \quad (1\leq k \leq K),\\ \tilde r_v &=\frac{\sum_{x\in \tilde D^v} w_x}{\sum_{x\in \tilde D} w_x} \quad (1\leq v \leq V). \end{align*} \] 直观地看,对属性 \(a\),\(\rho\) 表示无缺失值样本所占的比例,\(\tilde p_k\)表示无缺失值样本中第 \(k\) 类所占的比例,\(\tilde r_v\) 则表示无缺失值样本中在属性 \(a\) 上取值 \(a^v\) 的样本所占的比例。显然 \(\sum_{k=1}^K\tilde p_k=1, \sum_{v=1}^V\tilde r_v=1.\)

C4.5算法使用了上述解决方案。下面以表4.4的数据集为例来生成一棵决策树。
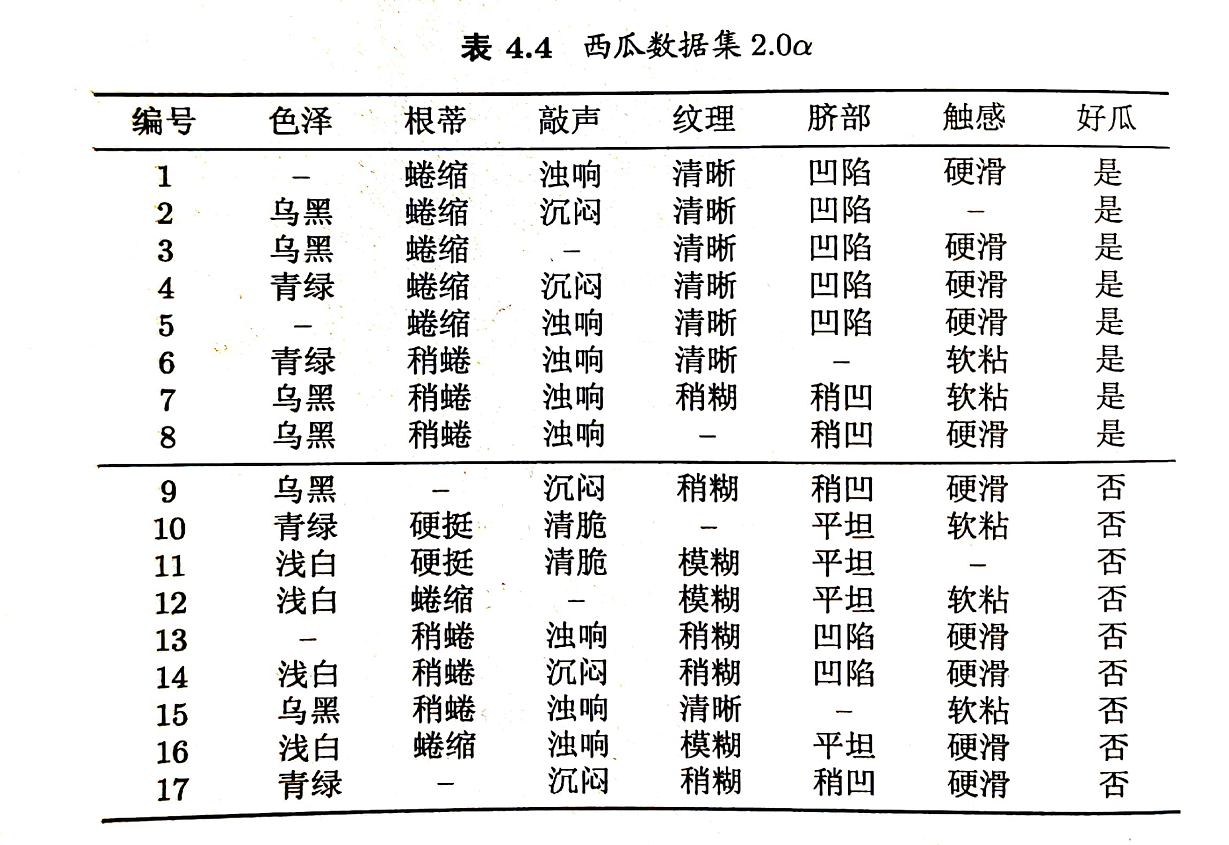


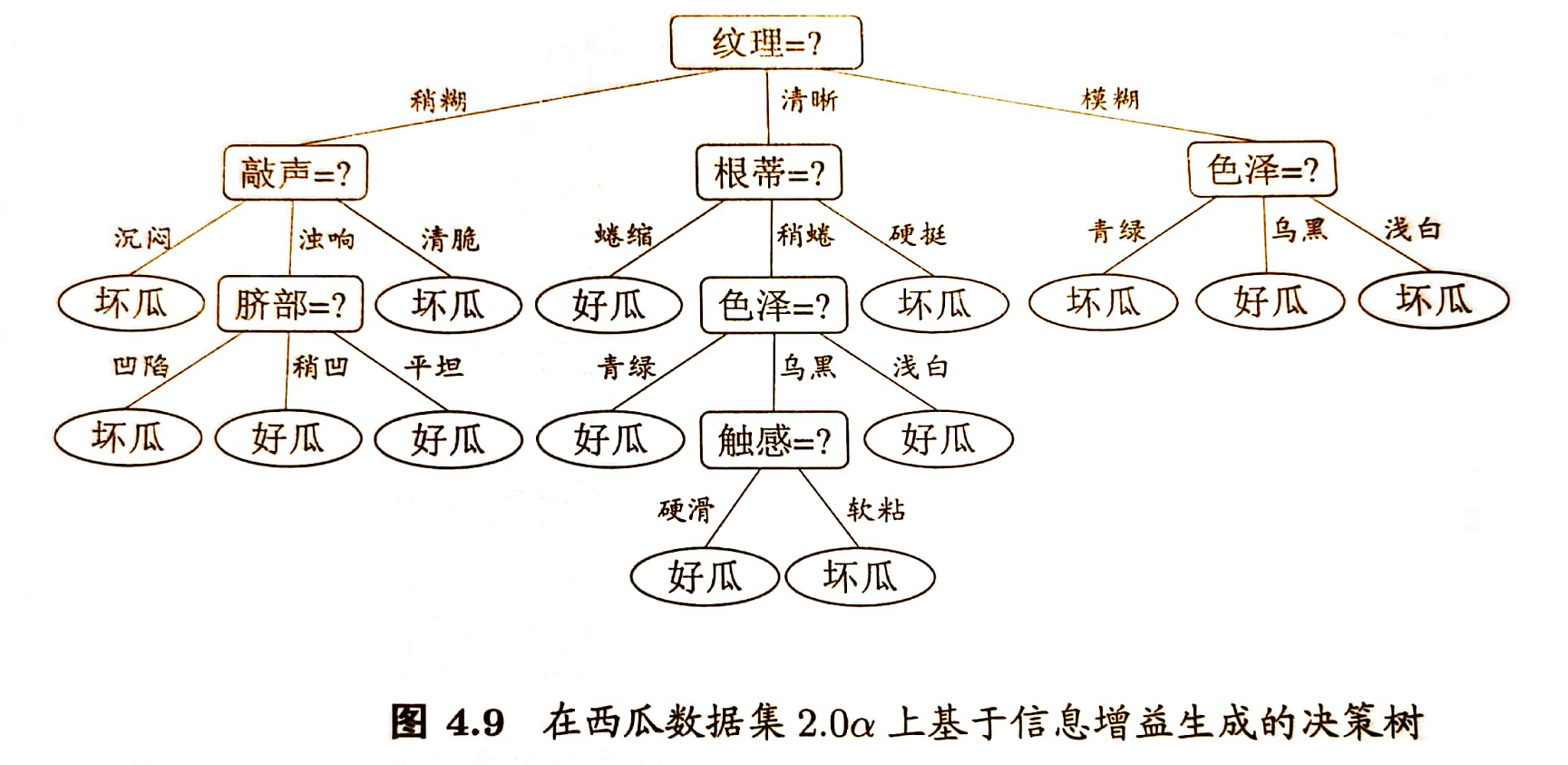
2.6 缺点
- 剪枝策略可以再优化;
- C4.5 用的是多叉树,用二叉树效率更高;
- C4.5 只能用于分类;
- C4.5 使用的熵模型拥有大量耗时的对数运算,连续值还有排序运算;
- C4.5 在构造树的过程中,对数值属性值需要按照其大小进行排序,从中选择一个分割点,所以只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时,程序无法运行。
3. CART
ID3 和 C4.5 虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但是其生成的决策树分支、规模都比较大,CART 算法的二分法可以简化决策树的规模,提高生成决策树的效率。
3.1 思想
CART 是在给定输入随机变量 \(X\) 条件下输出随机变量 \(Y\) 的条件概率分布的学习方法。CART 假设决策树是二叉树,内部结点特征的取值为 ”是“ 和 ”否“,左分支是取值为”是“的分支,右分支是取值为”否“的分支。这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。(《统计学习方法》)
CART 包含的基本过程有分裂,剪枝和树选择。
- 分裂:分裂过程是一个二叉递归划分过程,其输入和预测特征既可以是连续型的也可以是离散型的,CART 没有停止准则,会一直生长下去;
- 剪枝:采用代价复杂度剪枝,从最大树开始,每次选择训练数据熵对整体性能贡献最小的那个分裂节点作为下一个剪枝对象,直到只剩下根节点。CART 会产生一系列嵌套的剪枝树,需要从中选出一颗最优的决策树;
- 树选择:用单独的测试集评估每棵剪枝树的预测性能(也可以用交叉验证)。
CART 在 C4.5 的基础上进行了很多提升。
- C4.5 为多叉树,运算速度慢,CART 为二叉树,运算速度快;
- C4.5 只能分类,CART 既可以分类也可以回归;
- CART 使用 Gini 系数 作为变量的不纯度量,减少了大量的对数运算;
- CART 采用代理测试来估计缺失值,而 C4.5 以不同概率划分到不同节点中;
- CART 采用“基于代价复杂度剪枝”方法进行剪枝,而 C4.5 采用悲观剪枝方法。
3.2 划分标准
最优划分属性 \(a^*=\arg\min_{a∈A}Gini\)_\(index (D,a)\).
对回归树用平方误差最小化准则,对分类树用基尼指数(Gini index)最小化准则,进行特征选择,生成二叉树。关于回归树,见后面 3.6 回归树.
熵模型拥有大量耗时的对数运算,基尼指数在简化模型的同时还保留了熵模型的优点。基尼指数代表了模型的不纯度,基尼系数越小,不纯度越低,特征越好。这和信息增益(率)正好相反。
3.2.1 基尼指数
以下内容来自《统计学习方法》
分类树用基尼指数选择最优特征,同时决定该特征的最优二值切分点。
定义 (基尼指数) 分类问题中,假设有 \(K\) 个类,样本点属于第 \(k\) 类的概率为 \(p_k\),则概率分布的基尼指数定义为 \[ Gini(p)=\sum_{k=1}^K p_k(1-p_k)=1-\sum_{k=1}^K p_k^2 \] 对于二分类问题,若样本点属于第1个类的概率是 \(p\),则概率分布的基尼指数为 \[ Gini(p)=2p(1-p) \]
对于给定的样本集合 \(D\),其基尼指数为 \[ Gini(D)=1-\sum_{k=1}^K (\frac{|C_k|}{|D|})^2 \] 这里, \(C_k\) 是 \(D\) 中属于第 \(k\) 类的样本子集,\(K\) 是类的个数。
直观来说,\(Gini(D)\) 反映了从数据集 \(D\) 中随机抽取两个样本,其类别标记不一致的概率。因此 \(Gini(D)\) 越小,则数据集 \(D\) 的纯度越高。
如果样本集合 \(D\) 根据特征 \(A\) 是否取某一可能值 \(a\) 被分割成 \(D_1\) 和 \(D_2\) 两部分,即 \[ D_1=\{(x,y)∈D|A(x)=a\},\quad D_2=D-D_1 \] 则在特征 \(A\) 的条件下,集合 \(D\) 的基尼指数定义为 \[ Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2) \] 基尼指数 \(Gini(D)\) 表示集合 \(D\) 的不确定性(不纯度),基尼指数 \(Gini(D,A)\) 表示经 \(A=a\) 分割后集合 \(D\) 的不确定性。基尼指数越大,样本集合的不确定性也就越大,这一点与熵相似。
3.2.2 CART算法
算法3.1(CART生成算法)
输入:训练数据集 \(D\),停止计算的条件 输出:CART决策树
根据训练数据集,从根结点开始,递归地对每个结点进行以下操作,构建二叉决策树 (1)设结点的训练数据集为 \(D\),计算现有特征对该数据集的基尼指数。此时,对每一个特征 \(A\),对其可能取值的每个值 \(a\),根据样本点对 \(A=a\) 的测试为”是“或”否“将 \(D\) 分割成 \(D_1\) 和 \(D_2\) 两部分,计算 \(A=a\) 时的基尼指数 (2)在所有可能的特征 \(A\) 以及它们所有可能的切分点 \(a\) 中,选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点。依最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去 (3)对两个子结点递归地调用(1), (2),直至满足停止条件 (4)生成CART决策树 算法停止计算的条件是结点中的样本个数小于预定阈值,或样本的基尼指数小于预定阈值(样本基本属于同一类),或者没有更多特征。
例:根据表5.1所给训练数据集,应用CART算法生成决策树。(表5.1见1.2.2 ID3算法)

基尼指数偏向于特征值较多的特征,类似信息增益。基尼指数可以用来度量任何不均匀分布,是介于0~1之间的数,0是完全相等,1是完全不相等。
3.3 缺失值处理
上文说到,模型对于缺失值的处理会分为两个子问题:
1.在特征值缺失的情况下进行划分特征的选择? 2.选定该划分特征,对于缺失该特征值的样本如何处理?
对于问题 1,CART 一开始严格要求分裂特征评估时只能使用在该特征上没有缺失值的那部分数据,在后续版本中,CART 算法使用了一种惩罚机制来抑制提升值,从而反映出缺失值的影响(例如,如果一个特征在节点的 20% 的记录是缺失的,那么这个特征就会减少 20% 或者其他数值)。
对于问题 2,CART 算法的机制是为树的每个节点都找到代理分裂器,无论在训练数据上得到的树是否有缺失值都会这样做。在代理分裂器中,特征的分值必须超过默认规则的性能才有资格作为代理(即代理就是代替缺失值特征作为划分特征的特征),当 CART 树中遇到缺失值时,这个实例划分到左边还是右边是决定于其排名最高的代理,如果这个代理的值也缺失了,那么就使用排名第二的代理,以此类推,如果所有代理值都缺失,那么默认规则就是把样本划分到较大的那个子节点。代理分裂器可以确保无缺失训练数据上得到的树可以用来处理包含确实值的新数据。
3.4 剪枝策略
采用一种“基于代价复杂度的剪枝”方法进行后剪枝,这种方法会生成一系列树,每个树都是通过将前面的树的某个或某些子树替换成一个叶节点而得到的,这一系列树中的最后一棵树仅含一个用来预测类别的叶节点。然后用一种成本复杂度的度量准则来判断哪棵子树应该被一个预测类别值的叶节点所代替。这种方法需要使用一个单独的测试数据集来评估所有的树,根据它们在测试数据集熵的分类性能选出最佳的树。
我们来看具体看一下代价复杂度剪枝算法:


以下内容来自《统计学习方法》
CART 剪枝算法从”完全生长“的决策树的底端剪去一些子树,使决策树变小(模型变简单)。CART 剪枝算法由两步组成:首先从生成算法产生的决策树 \(T_0\) 底端开始不断剪枝,直到 \(T_0\) 的根结点,形成一个子树序列 \(\{ T_0,T_1, ...,T_n\}\);然后通过交叉验证法在独立的验证数据集上对字数序列进行测试,从中选择最优子树。
1.剪枝,形成一个子树序列


2.在剪枝得到的字数序列 $ T_0,T_1, ...,T_n$ 中通过交叉验证选取最优子树 \(T_\alpha\)

算法3.2 (CART剪枝算法)
输入:CART 算法生成的决策树 \(T_0\) 输出:最优决策树 \(T_\alpha\)
(1)设 \(k=0,T=T_0\) (2)设 \(\alpha=+\infty\) (3)自下而上地对各内部结点 \(t\) 计算 \(C(T_t),|T_t|\)以及 \[ g(t)=\frac{C(t)-C(T_t)}{|T_t|-1}\\ \alpha=min(\alpha,g(t)) \] 这里,\(T_t\) 表示以 \(t\) 为根结点的子树,\(C(T_t)\) 是对训练数据的预测误差,\(|T_t|\) 是 \(T_t\) 的叶结点个数。 (4)对 \(g(t)=\alpha\) 的内部结点 \(t\) 进行剪枝,并对叶结点 \(t\) 以多数表决法决定其类,得到树 \(T\) (5)设 \(k=k+1,\alpha_k=\alpha,T_k=T\). (6)如果 \(T_k\) 不是由根结点及两个叶结点构成的树,则回到不再(3);否则令 \(T_k=T_n\) (7)采用交叉验证法在子树序列 $ T_0,T_1, ...,T_n$ 中选取最优子树 \(T_\alpha\).
3.5 类别不平衡
CART 的一大优势在于:无论训练数据集有多失衡,它都可以将其自动消除不需要建模人员采取其他操作。
CART 使用了一种先验机制,其作用相当于对类别进行加权。这种先验机制嵌入于 CART 算法判断分裂优劣的运算里,在 CART 默认的分类模式中,总是要计算每个节点关于根节点的类别频率的比值,这就相当于对数据自动重加权,对类别进行均衡。

通过这种计算方式就无需管理数据真实的类别分布。假设有 K 个目标类别,就可以确保根节点中每个类别的概率都是 1/K。这种默认的模式被称为“先验相等”。
先验设置和加权不同之处在于先验不影响每个节点中的各类别样本的数量或者份额。先验影响的是每个节点的类别赋值和树生长过程中分裂的选择。
3.6 回归树
CART(Classification and Regression Tree,分类回归树),从名字就可以看出其不仅可以用于分类,也可以应用于回归。其回归树的建立算法上与分类树部分相似,这里简单介绍下不同之处。
3.6.1 连续值处理
对于连续值的处理,CART 分类树采用基尼系数的大小来度量特征的各个划分点。在回归模型中,我们使用常见的和方差度量方式,对于任意划分特征 \(A\),对应的任意划分点 \(s\) 两边划分成的数据集\(D_1\)和 \(D_2\),求出使\(D_1\)和\(D_2\) 各自集合的均方差最小,同时\(D_1\)和\(D_2\) 的均方差之和最小所对应的特征和特征值划分点。表达式为:
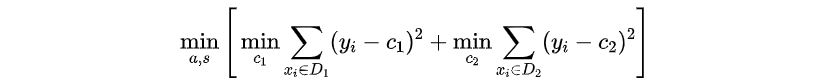
其中,\(c_1\)表示 \(D_1\) 的输出值,\(c_2\)表示 \(D_2\) 的输出值。\(D_1\)上的最优值输出值 \(\hat c_1\) 是 \(D_1\) 数据集的样本输出均值,即 \(\hat c_1 = ave(y_i|x_i\in D_1)\),同理,\(\hat c_2 = ave(y_i|x_i\in D_2)\).
3.6.2 预测方式
对于决策树建立后做预测的方式,上面讲到了 CART 分类树采用叶子节点里概率最大的类别作为当前节点的预测类别。而回归树输出不是类别,它采用的是用最终叶子的均值或者中位数来预测输出结果。
3.6.3 回归树的生成
以下内容来自《统计学习方法》


算法3.3 (最小二乘回归树生成算法)

4. 总结
最后通过总结的方式对比下 ID3、C4.5 和 CART 三者之间的差异。
- 划分标准的差异:ID3 使用信息增益,偏向特征值多的特征,C4.5 使用信息增益率克服信息增益的缺点,偏向于可取值较少的特征,CART 使用基尼指数克服 C4.5 需要求 log 的巨大计算量,偏向于特征值较多的特征。
- 使用场景的差异:ID3 和 C4.5 都只能用于分类问题,CART 可以用于分类和回归问题;ID3 和 C4.5 是多叉树,速度较慢,CART 是二叉树,计算速度很快;
- 样本数据的差异:ID3 只能处理离散数据且对缺失值敏感,C4.5 和 CART 可以处理连续型数据且有多种方式处理缺失值;从样本量考虑的话,小样本建议 C4.5,大样本建议 CART。C4.5 处理过程中需对数据集进行多次扫描排序,处理成本耗时较高,而 CART 本身是一种大样本的统计方法,小样本处理下泛化误差较大 ;
- 样本特征的差异:ID3 和 C4.5 层级之间只使用一次特征,CART 可多次重复使用特征;
- 剪枝策略的差异:ID3 没有剪枝策略,C4.5 是通过悲观剪枝策略来修正树的准确性(后剪枝),而 CART 是通过代价复杂度剪枝(后剪枝)。




信息增益,信息增益率 -> 选最大
基尼系数 -> 选最小
篇二:Random Forest, Adaboost, GBDT算法
本部分内容主要参考公众号Datawhale
https://mp.weixin.qq.com/s/Nl_-PdF0nHBq8yGp6AdI-Q
主要介绍基于集成学习的决策树,其主要通过不同学习框架生产基学习器(base learners),并综合所有基学习器的预测结果来改善单个基学习器的识别率和泛化性。
1.集成学习
常见的集成学习框架有三种:Bagging,Boosting 和 Stacking。
In averaging methods, the driving principle is to build several estimators independently and then to average their predictions. On average, the combined estimator is usually better than any of the single base estimator because its variance is reduced.
Examples: Bagging methods, Forests of randomized trees, …
By contrast, in boosting methods, base estimators are built sequentially and one tries to reduce the bias of the combined estimator. The motivation is to combine several weak models to produce a powerful ensemble.
Examples: AdaBoost, Gradient Tree Boosting, …
(来自 https://scikit-learn.org/stable/modules/ensemble.html)
1.1 Bagging
Bagging 全称叫 Bootstrap aggregating,每个基学习器都会对训练集进行有放回抽样得到子训练集,比较著名的采样法为 0.632 自助法。每个基学习器基于不同子训练集进行训练,并综合所有基学习器的预测值得到最终的预测结果。Bagging 常用的综合方法是投票法,票数最多的类别为预测类别。
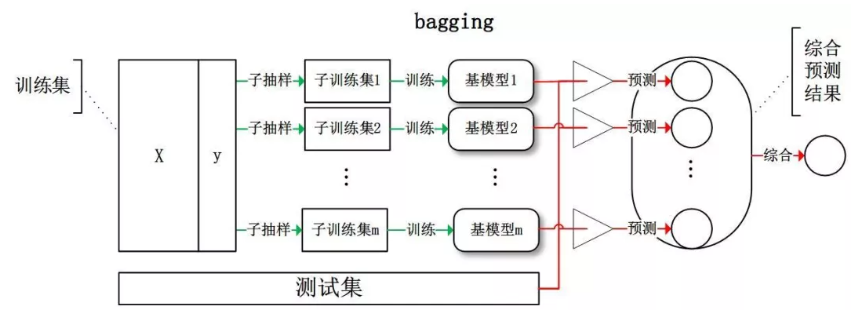
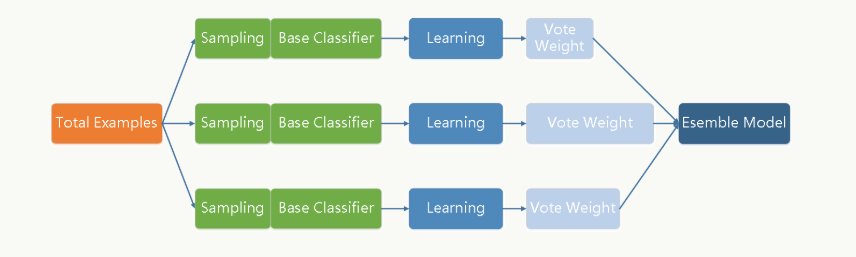
每个基础分类器(可以是树形结构、神经网络等等任何分类模型)的特点是低偏差、高方差,框架通过(加权)投票方式降低方差,使得整体趋于低偏差、低方差。
1.2 Boosting
Boosting 训练过程为阶梯状,基模型的训练是有顺序的,每个基模型都会在前一个基模型学习的基础上进行学习,最终综合所有基模型的预测值产生最终的预测结果,用的比较多的综合方式为加权法。
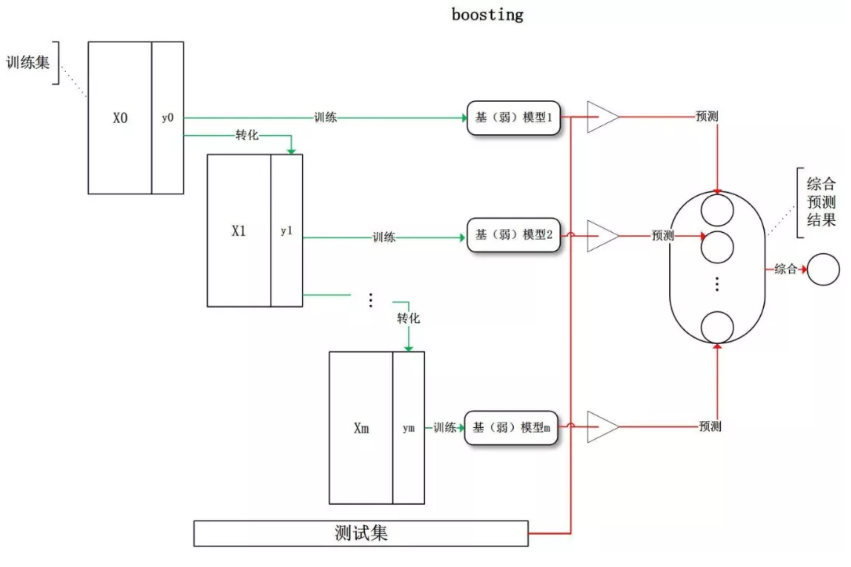
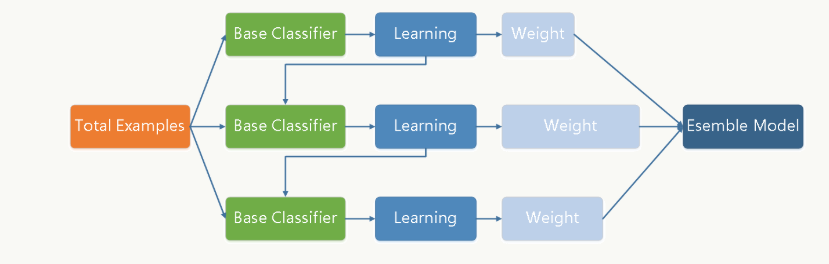
Boosting 通过迭代方式训练若干基础分类器,每个分类器依据上一轮分类器产生的残差做权重调整,每轮的分类器需要够“简单”(弱分类器),具有高偏差、低方差的特点,框架再辅以(加权)投票方式降低偏差,使得整体趋于低偏差、低方差。
1.3 Stacking
Stacking 是先用全部数据训练好基模型,然后每个基模型都对每个训练样本进行预测,其预测值将作为训练样本的特征值,最终会得到新的训练样本,然后基于新的训练样本进行训练得到模型,然后得到最终预测结果。
为什么集成学习会好于单个学习器呢?原因可能有三:
- 训练样本可能无法选择出最好的单个学习器,由于没法选择出最好的学习器,所以干脆结合起来一起用;
- 假设能找到最好的学习器,但由于算法运算的限制无法找到最优解,只能找到次优解,采用集成学习可以弥补算法的不足;
- 可能算法无法得到最优解,而集成学习能够得到近似解。比如说最优解是一条对角线,而单个决策树得到的结果只能是平行于坐标轴的,但是集成学习可以去拟合这条对角线。
2.偏差与方差
如何从偏差和方差的角度来理解集成学习。
2.1 集成学习的偏差与方差
偏差(Bias)描述的是预测值和真实值之差;方差(Variance)描述的是预测值作为随机变量的离散程度(不同样本下模型效果的离散程度)。
放一张很经典的图:
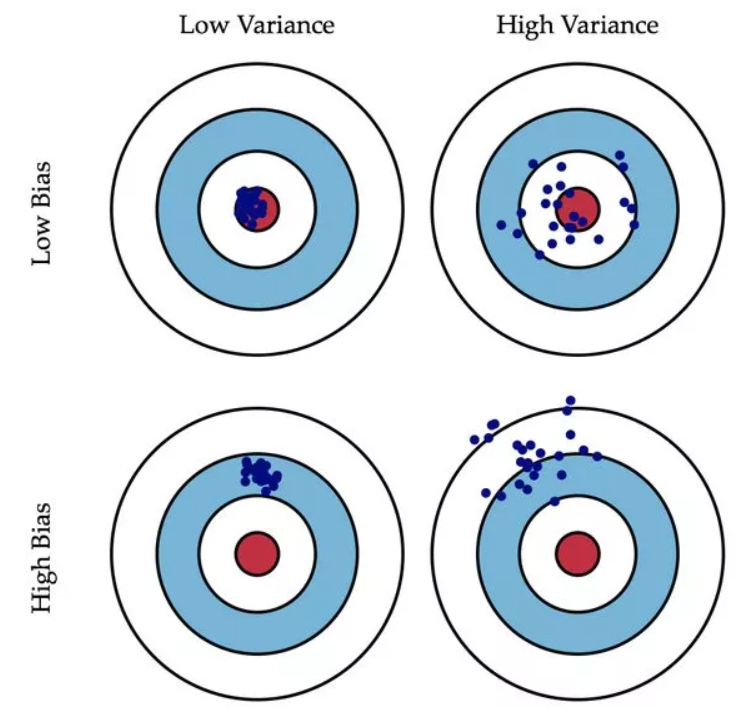
We can create a graphical visualization of bias and variance using a bulls-eye diagram. Imagine that the center of the target is a model that perfectly predicts the correct values. As we move away from the bulls-eye, our predictions get worse and worse. Imagine we can repeat our entire model building process to get a number of separate hits on the target. Each hit represents an individual realization of our model, given the chance variability in the training data we gather. Sometimes we will get a good distribution of training data so we predict very well and we are close to the bulls-eye, while sometimes our training data might be full of outliers or non-standard values resulting in poorer predictions. These different realizations result in a scatter of hits on the target.
模型的偏差与方差
- 偏差:描述样本拟合出的模型的预测结果的期望与样本真实结果的差距,要想偏差表现的好,就需要复杂化模型,增加模型的参数,但这样容易过拟合,过拟合对应上图的 High Variance,点会很分散。低偏差对应的点都打在靶心附近,描得很准,但不一定很稳;
- 方差:描述样本上训练出来的模型在测试集上的表现,要想方差表现的好,需要简化模型,减少模型的复杂度,但这样容易欠拟合,欠拟合对应上图 High Bias,点偏离中心。低方差对应就是点都打的很集中,但不一定是靶心附近,手很稳,但不一定瞄的准。
我们常说集成学习中的基模型是弱模型,通常来说弱模型是偏差高(在训练集上准确度低)方差小(防止过拟合能力强)的模型。但是,并不是所有集成学习框架中的基模型都是弱模型。Bagging 和 Stacking 中的基模型为强模型(偏差低方差高),Boosting 中的基模型为弱模型。

2.2 Bagging 的偏差与方差

(👆 应为方差公式第二项的改变对整体方差的作用很小?)
在此我们知道了为什么 Bagging 中的基模型一定要为强模型,如果 Bagging 使用弱模型则会导致整体模型的偏差提高,而准确度降低。
Random Forest 是经典的基于 Bagging 框架的模型,并在此基础上通过引入特征采样和样本采样来降低基模型间的相关性,从而在方差公式中,第一项显著减少,第二项稍微增加,整体方差仍是减少。
2.3 Boosting 的偏差与方差
对于 Boosting 来说,基模型的训练集抽样是强相关的,那么模型的相关系数近似等于1,故我们也可以针对 Boosting 化简公式为: \[ E(F)=r\sum_i^mE(f_i)\\ Var(F)=m^2r^2\sigma^2\rho+mr^2\sigma^2(1-\rho)=m^2r^2\sigma^2 \] 通过观察整体方差的表达式,我们容易发现:
- 若基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,Boosting框架中的基模型必须为弱模型
- 因为基模型为弱模型,导致了每个基模型的准确度都不是很高。随着基模型数的增多,整体模型的期望值增加,更接近真实值,因此整体模型的准确度提高。但是准确度一定会无限逼近1吗?仍然并不一定,因为训练过程中准确度的提高的主要功臣是整体模型在训练集行的准确度提高,而随着训练的进行,整体模型的方差变大,导致防止过拟合的能力变弱,最终导致了准确度反而有所下降。
基于 Boosting 框架的 Gradient Boosting Decision Tree 模型中基模型也为树模型,同 Random Forest,我们也可以对特征进行随机抽样来使基模型间的相关性降低,从而达到减少方差的效果。
2.4 小结
- 我们可以使用模型的偏差和方差来近似描述模型的准确度;
- 对于 Bagging 来说,整体模型的偏差与基模型近似,而随着模型的增加可以降低整体模型的方差,故其基模型需要为强模型;
- 对于 Boosting 来说,整体模型的方差近似等于基模型的方差,而整体模型的偏差由基模型累加而成,故基模型需要为弱模型。
3.Random Forest
RF 算法由很多决策树组成,每一棵决策树之间没有关联。建立完森林后,当有新样本进入时,每棵决策树都会分别进行判断,然后基于投票法给出分类结果。组成随机森林的树可以是分类树,也可以是回归树。(而GBDT只由回归树组成)
3.1 思想
Random Forest(随机森林)是 Bagging 的扩展变体,它在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机特征选择,因此可以概括 RF 包括四个部分:
- 随机选择样本(有放回抽样);
- 随机选择特征;
- 构建决策树;
- 随机森林投票(平均)。
随机选择样本和 Bagging 相同,采用的是 Bootstrap 自助采样法;随机选择特征是指在每个节点在分裂过程中都是随机选择特征的(区别于每棵树随机选择一批特征)。
For each split on a tree, you take a random subset of the features but still use the same splitting criteria.
Does random forest select a subset of features for every tree or every node?
That’s a good question, since the earlier random decision forests by Tin Kam Ho used the “random subspace method,” where each tree got a random subset of features.
“Our method relies on an autonomous, pseudo-random procedure to select a small number of dimensions from a given feature space …”
—— Ho, Tin Kam. “The random subspace method for constructing decision forests.” IEEE transactions on pattern analysis and machine intelligence 20.8 (1998): 832-844.
However, a few years later, Leo Breiman described the procedure of selecting different subsets of features for each node (while a tree was given the full set of features) — Leo Breiman’s formulation has become the “trademark” random forest algorithm that we typically refer to these days when we speak of “random forest”
“… random forest with random features is formed by selecting at random, at each node, a small group of input variables to split on.”
—— Breiman, Leo. “Random Forests” Machine learning 45.1 (2001): 5-32.
To answer your question: Each tree gets the full set of features, but at each node, only a random subset of features is considered.
(来自 https://sebastianraschka.com/faq/docs/random-forest-feature-subsets.html)
这种随机性导致随机森林的偏差会有稍微的增加(相比于单棵不随机树),但是由于随机森林的“平均”特性,会使得它的方差减小,而且方差的减小补偿了偏差的增大,因此总体而言是更好的模型。
随机采样由于引入了两种采样方法保证了随机性,所以每棵树都是最大可能的进行生长就算不剪枝也不会出现过拟合。
3.2 优缺点
优点
- 在数据集上表现良好,相对于其他算法有较大的优势
- 易于并行化,在大数据集上有很大的优势;
- 能够处理高维度数据,不用做特征选择。
4.AdaBoost
AdaBoost(Adaptive Boosting,自适应增强),其自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
4.1 思想
Adaboost 迭代算法有三步:
- 初始化训练样本的权值分布,每个样本具有相同权重;
- 训练弱分类器,如果样本分类正确,则在构造下一个训练集中,它的权值就会被降低;反之提高。用更新过的样本集去训练下一个分类器;
- 将所有弱分类组合成强分类器,各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,降低分类误差率大的弱分类器的权重。
4.2 细节
4.2.1 算法过程
来自 https://blog.csdn.net/weixin_38629654/article/details/80516045

最后总结一下Adaboost算法,理解它的关键就在于了解权值分布\(D_t\)是如何影响误差率\(e_t\)、权值\(\alpha_t\)以及更新权值分布\(D_{t+1}\)。具体的例子,可见 https://blog.csdn.net/guyuealian/article/details/70995333
AdaBoost 通过训练多个弱分类器来组合得到一个强分类器,每次迭代会生成一棵高偏差、低方差的弱分类器,每一轮的训练会更关注上一轮被分类器分错的样本,为其加大权重。
训练过程:
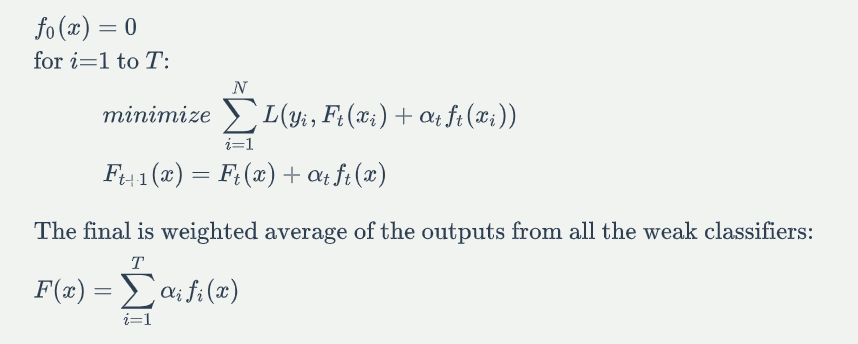
4.2.2 损失函数


4.2.3 正则化

4.3 优缺点
优点
(1)可以用各种回归分类模型来构建弱学习器,非常灵活,且不容易发生过拟合。 Adaboost提供一种框架,在框架内可以使用各种方法构建子分类器。可以使用简单的弱分类器,不用对特征进行筛选,也不存在过拟合的现象。
(2)分类精度高。 Adaboost算法不需要弱分类器的先验知识,最后得到的强分类器的分类精度依赖于所有弱分类器。无论是应用于人造数据还是真实数据,Adaboost都能显著的提高学习精度。
(3)Adaboost算法不需要预先知道弱分类器的错误率上限,且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,可以深挖分类器的能力。Adaboost可以根据弱分类器的反馈,自适应地调整假定的错误率,执行的效率高。
(4)Adaboost可以在不改变训练数据,只改变数据权值分布,使得数据在不同学习器中产生不同作用,类似于重采样。
缺点
在Adaboost训练过程中,Adaboost会使得难于分类样本的权值呈指数增长,训练将会过于偏向这类困难的样本,导致Adaboost算法易受噪声干扰(对异常点敏感,异常点会获得较高权重)。此外,Adaboost依赖于弱分类器,而弱分类器的训练时间往往很长。
5.GBDT
参考:
https://mp.weixin.qq.com/s/Nl_-PdF0nHBq8yGp6AdI-Q
https://blog.csdn.net/sb19931201/article/details/52506157
https://www.zybuluo.com/vivounicorn/note/446479
https://www.cnblogs.com/bnuvincent/p/9693190.html
GBDT(Gradient Boosting Decision Tree)是一种迭代的决策树算法,该算法由多棵决策树组成,从名字中我们可以看出来它是属于 Boosting 策略。GBDT 是被公认的泛化能力较强的算法。
GBDT 是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。
不同于Adaboost加大误分样本权重的策略,GBDT每次迭代加的是上一轮梯度更新值。其训练过程如下:
5.1 思想
GBDT 通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因此训练的过程是通过降低偏差来不断提高最终分类器的精度。
弱分类器一般会选择为CART TREE(也就是分类回归树)。由于上述高偏差和简单的要求,每个分类回归树的深度不会很深。最终的总分类器是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
模型最终可以描述为: \[ F_M(x)=\sum_{m=1}^MT(x;\theta_m) \]
模型一共训练 \(M\) 轮,每轮产生一个弱分类器 \(T(x;\theta_m)\)。弱分类器的损失函数
\[ \theta_m = argmin_{\theta_m}\sum_{i=1}^N L(y_i,F_{m-1}(x_i)+T(x_i;\theta_m)) \] \(F_{m-1}(x)\) 为当前的模型,GBDT 通过经验风险极小化来确定下一个弱分类器的参数。具体到损失函数本身的选择也就是 \(L\) 的选择,有平方损失函数,0-1损失函数,对数损失函数等等。如果我们选择平方损失函数,那么这个差值其实就是我们平常所说的残差。
如何让损失函数尽可能快的减小:让损失函数沿着梯度方向下降。这个就是 GBDT 的 GB 的核心了。 利用损失函数的负梯度在当前模型的值 \[ -[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)}]_{f(x)=f_{m-1}(x)} \] 作为回归问题提升树算法中的残差的近似值去拟合一个回归树。gbdt 每轮迭代的时候,都去拟合损失函数在当前模型下的负梯度。这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
5.1.1 Boosting
GBDT 的全称是 Gradient Boosting Decision Tree,Gradient Boosting 和 Decision Tree是两个独立的概念。因此我们先说说Boosting。Boosting的概念很好理解,意思是用一些弱分类器的组合来构造一个强分类器。因此,它不是某个具体的算法,它说的是一种理念。和这个理念相对应的是一次性构造一个强分类器。像支持向量机,逻辑回归等都属于后者。通常,我们通过相加来组合弱分类器,形式如下: \[ F_m(x) = f_0 + \alpha_1f_1(x) +\alpha_2f_2(x) + ... + \alpha_m f_m(x) \]
5.1.2 Gradient Boosting Modeling (GBM)
给定一个问题,我们如何构造这些弱分类器呢?Gradient Boosting Modeling (GBM) 就是构造这些弱分类器的一种方法。同样,它指的不是某个具体的算法,仍然只是一个理念。
5.1.2.1 最深梯度下降法(Steepest Gradient Descent)
在理解 Gradient Boosting Modeling 之前,我们先看看一个典型的优化问题: \[ find\ \hat x = \mathop{\arg\min}_x f(x) \] 针对这种优化问题,有一个经典的算法叫 Steepest Gradient Descent(最深梯度下降法)。 这个算法的过程大致如下:
1.给定一个起始点 \(x_0\)
2.对 \(i = 1, 2, ..., K\) 分别做如下迭代: \[ x_i = x_{i-1} + \gamma_{i-1}*g_{i-1},这里g_{i-1}=-\frac{\partial f}{\partial x}|_{x=x_{i-1}}表示 f 在 x_{i-1}处的梯度 \] 直到 \(g_{i-1}\) 足够小,或者 \(|x_i-x_{i-1}|\) 足够小。
以上迭代过程可以这么理解:整个寻优的过程就是个小步快跑的过程,每跑一小步,都往函数当前下降最快的那个方向走一点。
这样寻优得到的结果可以表示成加和形式,即: \[ x_k = x_0 + \gamma_1*g_1 +\gamma_2*g_2 + ... + \gamma_k*g_k \]
5.1.2.2 Gradient Boosting
Gradient Boosting 正是由此启发而来。 构造 \(F_m(x)\) 本身也是一个寻优的过程,只不过我们寻找的不是一个最优点,而是一个最优的函数。优化的目标通常都是通过一个损失函数来定义,即: \[ find\ F_m = \mathop{\arg \min_F} L(F)= \mathop{\arg \min_F} \sum_{i=0}^N Loss(F(x_i),y_i) \] 其中 \(Loss(F(x_i),y_i)\) 表示损失函数 Loss 在第 i 个样本上的损失值。常见的损失函数如平方差函数: \[ Loss(F(x_i),y_i)=(F(x_i)-y_i)^2 \] 类似最深梯度下降法,可以通过梯度下降法来构造弱分类器 \(f_1,f_2,...,f_m\),只不过每次迭代时,令 \[ g_i=-\frac{\partial L}{\partial F}|_{F=F_{i-1}} \] 即对损失函数L,以 F 为参考求取梯度。这里有个小问题,一个函数对函数的求导不好理解,而且通常都无法通过上述公式直接求解到梯度函数 \(g_i\)。为此,采取一个近似的方法,把函数 \(F_{i−1}\) 理解成在所有样本上的离散的函数值,即:\([F_{i-1}(x_1),F_{i-1}(x_2),...F_{i-1}(x_N)]\),不难理解,这是一个 N 维向量。然后计算 \[ \hat g_i(x_k)=-\frac{\partial L}{\partial F(x_k)}|_{F=F_{i-1}} \quad for\ k = 1,2,3,...,N \] 严格来说 \(\hat g_i(x_k) \quad for\ k = 1,2, ... , N\) 只是描述了 \(g_i\) 在某些个别点上的值,并不足以表达 \(g_i\),但我们可以通过函数拟合的方法从 \(\hat g_i(x_k) \quad for\ k = 1,2, ... , N\) 构造 \(g_i\),这样我们就通过近似的方法得到了函数对函数的梯度求导。
5.1.2.3 GBM 的过程总结
1.选择一个起始常量函数 \(f_0\)(常量函数 \(f_0\) 通常取样本目标值的均值,即 \(f_0 = \frac{1}{N}\sum_{i=0}^Ny_i\).)
2.对 \(i=1,2,...,K\) 分别做如下迭代:
- 计算离散梯度值 \(\hat g_i(x_j)=-\frac{\partial L}{\partial F(x_j)}|_{F=F_{i-1}}, \quad for\ j = 1,2,3,...,N\)
- 对 \(\hat g_{i-1}(x_j) \quad for\ j = 1,2,3,...,N\) 做函数拟合得到 \(g_i-1\)
- 通过 line search 得到 \(\gamma_{i-1}=\arg \min L(F_{i-1}+\gamma_{i-1}*g_{i-1})\)
- 令 \(F_i = F_{i-1}+\gamma_{i-1}*g_{i-1}\)
3.直到 \(|\hat g_{i-1}|\) 足够小,或者迭代次数完毕
5.1.3 Gradient Boosting Decision Tree
以上 Gradient Boosting Modeling 的过程中,还没有说清楚如何通过离散值 \(\hat g_{i−1}(x_j) \quad for\ j = 1,2,3,...N\) 构造拟合函数 \(g_{i−1}\)。函数拟合是个比较熟知的概念,有很多现成的方法,不过有一种拟合方法广为应用,那就是决策树 Decision Tree。GBDT 是 Gradient Boosting 的一种具体实例,只不过这里的弱分类器是决策树。如果你改用其他弱分类器 XYZ,也可以称之为 Gradient Boosting XYZ。只不过 Decision Tree 很好用,GBDT 才如此引人注目。
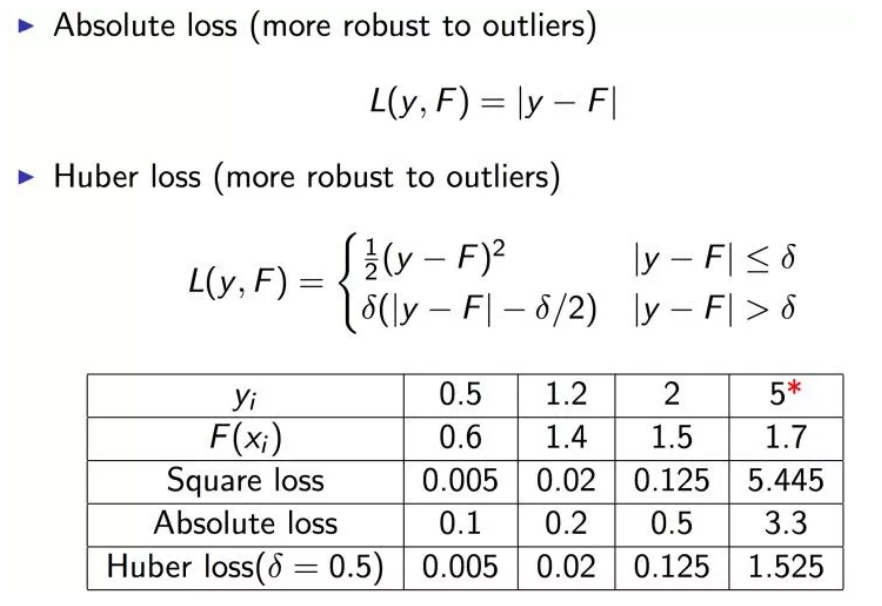
GBDT 无论用于分类还是回归一直都是使用的CART 回归树。对于分类树而言,其值加减无意义(如性别),而对于回归树而言,其值加减才是有意义的(如说年龄)。GBDT 的核心在于累加所有树的结果作为最终结果,所以 GBDT 中的树都是回归树,不是分类树,这一点相当重要。
回归树在分枝时会穷举每一个特征的每个阈值以找到最好的分割点,衡量标准是最小化均方误差。
5.1.4 梯度迭代(Gradient Boosting)
上面说到 GBDT 的核心在于累加所有树的结果作为最终结果,GBDT 的每一棵树都是以之前树得到的残差来更新目标值,这样每一棵树的值加起来即为 GBDT 的预测值。
举个例子:比如说 A 用户年龄 20 岁,第一棵树预测 12 岁,那么残差就是 8,第二棵树用 8 来学习,假设其预测为 5,那么其残差即为 3,如此继续学习即可。
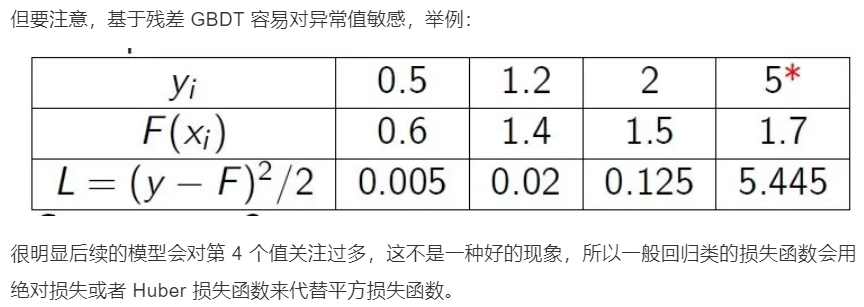
那么Gradient 从何体现?其实很简单,其残差其实是最小均方损失函数关于预测值的反向梯度。 \[ F_i(x) = F_{i-1}(x) + (-\frac{\partial(\frac{1}{2}(y-F_{i-1}(x))^2)}{\partial F(x)} ) \]
GBDT 的 Boosting 不同于 Adaboost 的 Boosting,GBDT 的每一步残差计算其实变相地增大了被分错样本的权重,而对于分对样本的权重趋于 0,这样后面的树就能专注于那些被分错的样本。
参考 https://blog.csdn.net/sb19931201/article/details/52506157
GBDT算法步骤:

算法第 1 步初始化 ,估计使损失函数极小化的常数值,它是只有一个根结点的树。第 2 (a) 步计算损失函数的负梯度在当前模型的值,将它作为残差的估计。对于平方损失函数,它就是通常所说的残差;对于一般损失函数,它就是残差的近似值。第 2 (b) 步估计回归树叶结点区域,以拟合残差的近似值。第 2(c) 步利用线性搜索估计叶结点区域的值,使损失函数极小化。第 2(d) 步更新回归树,第 3 步得到输出的最终模型。
In pseudocode, the generic gradient boosting method is:



5.1.5 避免过拟合 - 缩减(Shrinkage)
Shrinkage 的思想认为,每走一小步逐渐逼近结果的效果要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即它并不是完全信任每一棵残差树。
更新规则: \[ F_m(x)=F_{m-1}(x)+\nu \cdot \gamma_m h_m(x), (0< v \leq 1) \] Shrinkage 不直接用残差修复误差,而是只修复一点点,把大步切成小步。本质上 Shrinkage 为每棵树设置了一个 weight,累加时要乘以这个 weight,当 weight 降低时,基模型数会配合增大。
Empirically it has been found that using small learning rates (such as \(\nu\) <0.1) yields dramatic improvements in models' generalization ability over gradient boosting without shrinking (\(\nu\) =1). However, it comes at the price of increasing computational time both during training and querying: lower learning rate requires more iterations.
5.1.6 对GBDT损失函数的理解
谈到 GBDT,常听到一种简单的描述方式:“先构造一个(决策)树,然后不断在已有模型和实际样本输出的残差上再构造一颗树,依次迭代”。其实这个说法不全面,它只是 GBDT 的一种特殊情况,为了看清这个问题,需要对损失函数的选择做一些解释。
从对 GBM 的描述里可以看到 Gradient Boosting 过程和具体用什么样的弱分类器是完全独立的,可以任意组合,因此这里不再刻意强调用决策树来构造弱分类器,转而我们来仔细看看弱分类器拟合的目标值,即梯度\(\hat g_{i−1}(x_j)\)。
以平方差损失函数为例 \[ \frac{\partial L}{\partial F(x_k)}|_{F=F_{i-1}}=2(F_{i-1}(x_k)-y_k) \] 忽略倍数2,这正好是当前已经构造好的函数 \(F_{i-1}\) 在样本上和目标值 \(y_k\) 之间的差值。
对于绝对差值损失函数,梯度是个符号函数: \[ Loss(F(x_i),y_i)=|F(x_i)-y_i| \]
\[ \frac{\partial L}{\partial F(x_k)}|_{F=F_{i-1}}=sign(F_{i-1}(x_k)-y_k) \]
由此可以看到,只有当损失函数为平方差函数时,才能说 GBDT 是通过拟合残差来构造弱分类器的。
5.1.7 利用 GBDT 构建特征组合
其实说 GBDT 能够构建特征并非很准确,GBDT 本身是不能产生特征的,但是我们可以利用 GBDT 去产生特征的组合。在CTR预估中,工业界一般会采用逻辑回归去进行处理,逻辑回归本身是适合处理线性可分的数据,如果我们想让逻辑回归处理非线性的数据,其中一种方式便是组合不同特征,增强逻辑回归对非线性分布的拟合能力。
长久以来,我们都是通过人工的先验知识或者实验来获得有效的组合特征,但是很多时候,使用人工经验知识来组合特征过于耗费人力,造成了机器学习当中一个很奇特的现象:有多少人工就有多少智能。关键是这样通过人工去组合特征并不一定能够提升模型的效果。所以我们的从业者或者学界一直都有一个趋势便是通过算法自动、高效的寻找到有效的特征组合。Facebook 在2014年 发表的一篇论文便是这种尝试下的产物,利用 GBDT 去产生有效的特征组合,以便用于逻辑回归的训练,提升模型最终的效果。
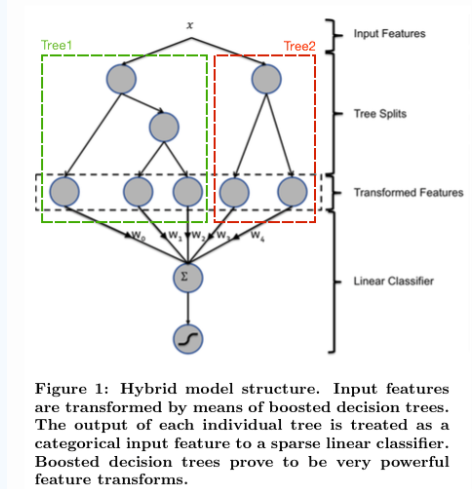
如上图所示,我们使用 GBDT 生成了两棵树,两棵树一共有五个叶子节点。我们将样本 X 输入到两棵树当中去,样本 X 落在了第一棵树的第二个叶子节点,第二棵树的第一个叶子节点,于是我们便可以依次构建一个五维的特征向量,每一个维度代表一个叶子节点,样本落在这个叶子节点上面的话那么值为1,没有落在该叶子节点的话,那么值为 0。于是对于该样本,我们可以得到一个向量 [0,1,0,1,0] 作为该样本的组合特征,和原来的特征一起输入到逻辑回归当中进行训练。实验证明这样会得到比较显著的效果提升。
(具体例子见原网页)
5.1.8 GBDT 如何用于分类
首先明确一点,GBDT 无论用于分类还是回归一直都是使用的CART 回归树。这里面的核心是因为 GBDT 每轮的训练是在上一轮训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的。如果选用的弱分类器是分类树,类别相减是没有意义的。
具体到分类这个任务上面来,假设样本 \(X\) 总共有 \(K\) 类。来了一个样本 \(x\),我们需要使用 GBDT 来判断 \(x\) 属于哪一类。

第一步,我们在训练的时候,是针对样本 \(X\) 每个可能的类都训练一个分类回归树。举例说明,目前样本有三类( K = 3)。样本 \(x\) 属于 第二类,那么针对该样本 \(x\) 的分类结果,我们可以用一个三维向量 [0,1,0] 来表示。
针对样本有三类的情况,我们实质上是在每轮训练时,同时训练三棵树。第一棵树针对样本 \(x\) 的第一类,输入为 \((x,0)\)。第二棵树输入针对样本 \(x\) 的第二类,输入为 \((x,1)\)。第三棵树针对样本 \(x\) 的第三类,输入为 \((x, 0)\)。
在这里每棵树的训练过程,其实就是之前提到过的 CART TREE 的生成过程。参照之前的生成树的程序可以解出三棵树,以及三棵树对 \(x\) 类别的预测值 \(f_1(x),f_2(x),f_3(x)\)。在此类训练中,我们仿照多分类的逻辑回归 ,使用 softmax 来产生概率,则属于类别 1 的概率 \[ p_1=\frac{exp(f_1(x))}{∑_{k=1}^3 exp(f_k(x))} \] 并且我们可以针对类别 1 求出残差 \(y_1(x)=0−p_1(x)\); 类别 2 求出残差 \(y_2(x)=1−p_2(x)\); 类别 3 求出残差 \(y_3(x)=0−p_3(x)\).
然后开始第二轮训练。针对第一类输入为 \((x,y_1(x))\), 针对第二类输入为 \((x,y_2(x))\), 针对第三类输入为 \((x,y_3(x))\). 继续训练出三棵树。一直迭代 M 轮,每轮构建 3 棵树。
所以当 K = 3 时,我们应该有三个式子 \[ \begin{align*} F_{1M}(x)=∑_{m=1}^M C_{1m}I(x\in R_{1m})\\ F_{2M}(x)=∑_{m=1}^M C_{2m} I(x\in R_{2m})\\ F_{3M}(x)=∑_{m=1}^M C_{3m} I(x\in R_{3m}) \end{align*} \] 当训练完毕以后,新来一个样本 \(x_1\) ,我们需要预测该样本的类别的时候,便可以用这三个式子产生三个值,\(f1(x_1),f2(x_1),f3(x_1)\)。样本属于某个类别 \(c\) 的概率为 \[ p_c=\frac{exp(f_c(x_1))}{∑_{k=1}^3exp(f_k(x_1))} \] (GBDT 多分类举例说明 Iris 数据集见原网页.)
5.1.9 GBDT总结
来自 https://blog.csdn.net/sb19931201/article/details/52506157
Gradient Boosting:每一次的计算是为了减少上一次的残差(residual),而为了消除残差,我们可以在残差减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boost中,每个新的模型的建立是为了使得之前模型的残差往梯度方向减少(当然也可以变向理解成每个新建的模型都给予上一模型的误差更多的关注),与传统Boost对正确、错误的样本进行直接加权还是有区别的。
Size of trees(J):模型叶结点的数量J需要根据现有数据调整,它控制着模型变量之间的相互作用,一般情况下都选择J的大小在4到8之间,J=2一般不能满足需要,J>10的情况也不太可能需要。

5.2 优缺点
优点
- 预测精度高
- 适合低维数据
- 可以自动进行特征组合,拟合非线性数据。可以灵活处理各种类型的数据,包括连续值和离散值
- 预测阶段计算速度快,树与树之间可并行化计算
- 在分布稠密的数据集上,泛化能力和表达能力都很好,这使得GBDT在Kaggle的众多竞赛中,经常名列榜首
- 具有较好的解释性和鲁棒性,能够自动发现特征间的高阶关系,并且也不需要对数据进行特殊的预处理归一化等。
缺点
- 对异常点敏感。
- GBDT在高维稀疏的数据集上,表现不如SVM或者神经网络
- GBDT在处理文本分类特征问题上,相对其他模型的优势不如它在处理数值型特征时明显
- 训练过程需要串行训练,只能在决策树内部采用一些局部并行的手段提高训练速度(可以通过自采样的SGBT达到部分并行)
5.3 与 Adaboost 的对比
相同:
- 都是 Boosting 家族成员,使用弱分类器;
- 都使用前向分布算法;
不同:
- 迭代思路不同:Adaboost 是通过提升错分数据点的权重来弥补模型的不足(利用错分样本),而 GBDT 是通过算梯度来弥补模型的不足(利用残差);
- 损失函数不同:AdaBoost 采用的是指数损失,GBDT 使用的是绝对损失或者 Huber 损失函数;
5.4 随机森林与GBDT的比较
随机森林采用的bagging思想,GBDT采用的boosting思想,组成随机森林的树可以并行生成,GBDT只能串行生成,因为每个学习器是在之前的学习器的基础上进行训练的
组成随机森林的树可以是分类树,也可以是回归树;而GBDT只能由回归树组成。
对于最终的输出结果而言,随机森林采用多数投票等;而GBDT则是将所有结果累加起来,或者加权累加起来。
随机森林对异常值不敏感;GBDT对异常值非常敏感。
随机森林是通过减少模型方差提高性能;GBDT是通过减少模型偏差提高性能。
Random Forest and Gradient Boosted Decision Trees have vastly different optimal max_depth: Random Forest usually have max_depth ≥ 15, while for GBDT it is typically 4 ≤ max_depth ≤ 8.
When would one use Random Forests over Gradient Boosted Machines (GBMs)?
There are two main reasons why you would use Random Forests over Gradient Boosted Decision Trees, and they are both pretty related:
- RF are much easier to tune than GBM
- RF are harder to overfit than GBM
Related to (1), RF basically has only one hyperparameter to set: the number of features to randomly select at each node. However there is a rule-of-thumb to use the square root of the number of total features which works pretty well in most cases[1]. On the other hand, GBMs have several hyperparameters that include the number of trees, the depth (or number of leaves), and the shrinkage (or learning rate).
And, regarding (2), while it is not true that RF do not overfit (as opposed as many are led to believe by Breiman's strong assertions[2]), it is true that they are more robust to overfitting and require less tuning to avoid it.
随机森林更不容易过拟合。
GBMs are more sensitive to overfitting if the data is noisy.
(https://medium.com/@aravanshad/gradient-boosting-versus-random-forest-cfa3fa8f0d80)In some sense, RF is a tree ensemble that is more "plug'n'play" than GBM. However, it is generally true that a well-tuned GBM can outperform a RF.
Also, as Tianqi Chen mentioned, RF has traditionally been easier to parallelism. However, that is not a good reason anymore given there are efficient ways to do it with GBMs also.
(https://www.quora.com/When-would-one-use-Random-Forests-over-Gradient-Boosted-Machines-GBMs)
篇三:XGBoost
本部分内容参考公众号Datawhale https://mp.weixin.qq.com/s/LoX987dypDg8jbeTJMpEPQ
以及文章: https://mp.weixin.qq.com/s/qongHAx-X2SWrUxjk8tg0A
XGBoost原论文: https://arxiv.org/pdf/1603.02754.pdf
(注:以下内容只包含XGBoost部分,LightGBM部分可见原文链接)
XGBoost
XGBoost 是大规模并行 boosting tree 的工具,它是目前最快最好的开源 boosting tree 工具包,比常见的工具包快 10 倍以上。Xgboost 和 GBDT 两者都是 boosting 方法,除了工程实现、解决问题上的一些差异外,最大的不同就是目标函数的定义。
1.1 数学原理
1.1.1 目标函数


👆 以基模型为回归树为例,我们的目标其实就是训练一群回归树,使这群树的预测值尽量接近真实值,并且有尽可能强大的泛化能力。前一项表示的是预测误差,后一项表示的是树的复杂度函数,\(f_t\)表示第t棵树,一共有k棵树。
我们要做的就是使预测误差尽量小,叶子节点数尽量少,预测值尽量不极端(什么叫预测值尽量不极端?举个栗子,一个人的真实年龄是4岁,有两个模型,第一个模型的第一棵回归树预测值是3岁,第二棵回归树预测值是1岁,第二个模型的第一棵回归树预测值是2岁,第二棵预测值也是2岁,那我们更倾向于选择第二个模型,因为第一个模型学习的太多,有过拟合的风险)


\[ g_i=\frac{\partial\ l(y_i,\hat{y_i}^{t-1})}{\partial\,\hat{y_i}^{t-1}} \]
\[ h_i=\frac{\partial^2 l(y_i,\hat{y_i}^{t-1})}{\partial (\hat{y_i}^{t-1})^2} \]

又因为有 \[ \sum_{i=1}^{t} \Omega(f_i)=\Omega(f_t)+\sum_{i=1}^{t-1}\Omega(f_i) \] 并且\(\sum_{i=1}^{t-1}\Omega(f_i)\)在前t-1棵树已知下为常数,所以目标函数可写为: \[ Obj^{(t)}≈\sum_{i=1}^{n}[g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\Omega(f_t) \]
(最优化目标函数,就相当于求解\(f_{t}\))
1.1.2 基于决策树的目标函数
我们知道 Xgboost 的基模型不仅支持决策树,还支持线性模型,这里我们主要介绍基于决策树的目标函数。
下面讨论基于决策树时,\(\Omega(f_t)\) 的表达式。

(注:这里的节点权重\(w_{j}\)指的就是该叶子节点的预测值)
另一种描述:
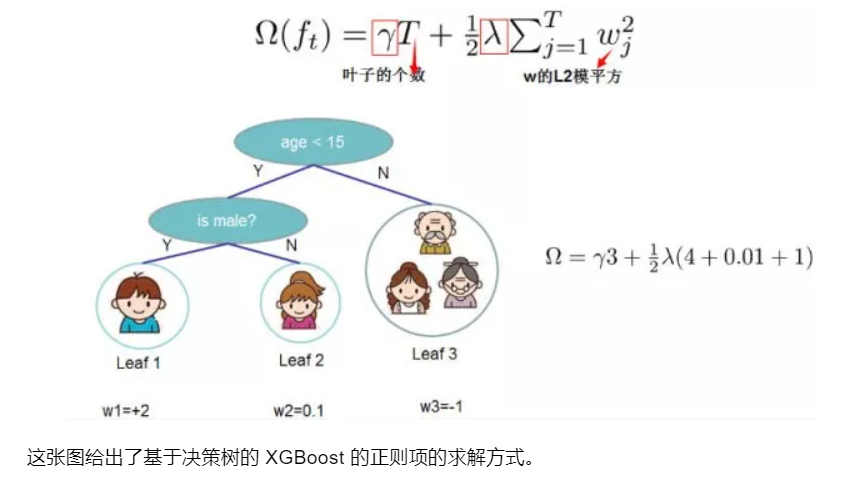
现在定义\(\Omega(f_t)\):假设我们待训练的第t棵树有T个叶子结点,叶子结点的输出向量表示如下: \[ [w_1,w_2,...,w_T] \] 假设 \(q(x):R^d \rightarrow \{1,2,3,...,T\}\) 表示样本到叶子结点的映射,那么\(f_t(x)=w_{q(x)},w∈R^T\).那么我们定义: \[ \Omega(f_t)=\gamma T+\frac{1}{2}\lambda\sum_{j=1}^Tw_j^2 \] 其中\(T\)为叶子结点数,\(w_j\)为叶子结点\(j\)的输出,\(\gamma\)为系数。


另一种描述:


1.1.3 最优切分点划分算法
我们刚刚的假设前提是已知前t-1棵树,现在我们讨论怎么生成树。根据决策树的生成策略,在每次分裂节点的时候我们需要考虑能使得损失函数减小最快的节点,将分裂前损失函数减去分裂后损失函数称之为Gain:
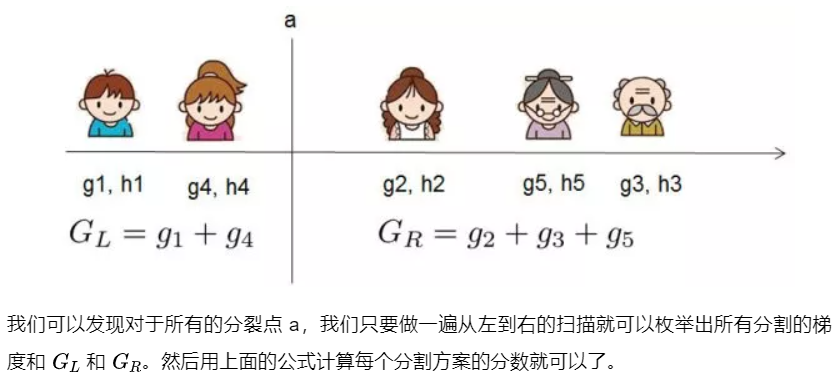
对于某个节点,有 \[ Gain = \frac{1}{2}[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}]-\gamma \] 其中 \[ G_L=\sum_{i\in I_L} g_i, \quad G_R = \sum_{i\in I_R}g_i, \quad H_L = \sum_{i\in I_L} h_i, \quad H_R=\sum_{i\in I_R}h_i \] \(I_L\),\(I_R\) 分别表示分裂后左右子节点的样本集合, \(I=I_L \cup L_R\) .
Gain越大越能说明分裂后目标函数值减小越多。
如何找到叶子的节点的最优切分点:Xgboost 支持两种分裂节点的方法——贪心算法和近似算法。
1)贪心算法 (精确贪心算法 Basic Exact Greedy Algorithm)
在决策树(CART)里面,我们使用的是精确贪心算法,也就是将所有特征的所有取值排序(耗时耗内存巨大),然后比较每一个点的Gini,找出变化最大的节点。当特征是连续特征时,我们对连续值离散化,取两点的平均值为分割节点。可以看到,这里的排序算法需要花费大量的时间,因为要遍历整个样本所有特征,而且还要排序。
步骤:
- 从深度为 0 的树开始,对每个叶节点枚举所有的可用特征;
- 针对每个特征,把属于该节点的训练样本根据该特征值进行升序排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的分裂收益;
- 选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,在该节点上分裂出左右两个新的叶节点,并为每个新节点关联对应的样本集
- 回到第 1 步,递归执行到满足特定条件为止
那么如何计算每个特征的分裂收益呢?


2)近似算法 (Approximate Algorithm)
贪婪算法可以得到最优解,但当数据量太大时则无法读入内存进行计算,近似算法主要针对贪婪算法这一缺点给出了近似最优解。
对于每个特征,只考察分位点可以减少计算复杂度。
该算法会首先根据特征分布的分位数提出候选划分点,然后将连续型特征映射到由这些候选点划分的桶中,然后聚合统计信息找到所有区间的最佳分裂点。
另一种描述:
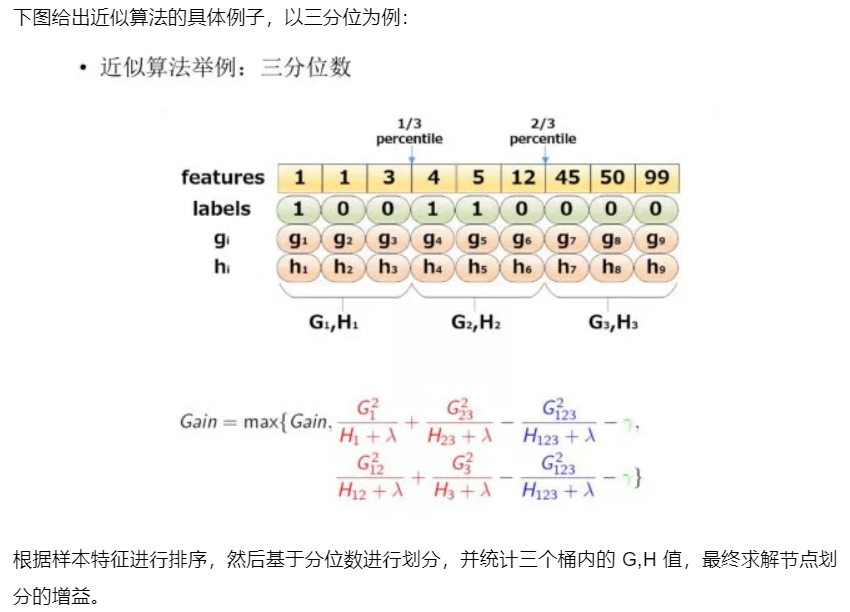
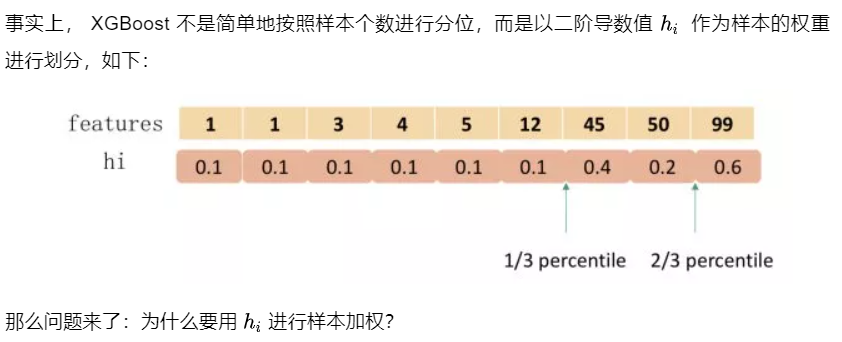
该算法首先根据特征分布的百分位数(percentiles)提出候选分裂点,将连续特征映射到由这些候选点分割的桶中,汇总统计信息并根据汇总的信息在提案中找到最佳解决方案。对于某个特征k,算法首先根据特征分布的分位数找到特征切割点的候选集合\(S_k=\{S_{k_1},S_{k_2},...,S_{k_l}\}\) , 然后将特征k的值根据集合\(S_k\) 划分到桶(bucket)中,接着对每个桶内的样本统计值G、H进行累加,最后在这些累计的统计量上寻找最佳分裂点。
在提出候选切分点时有两种策略:
- Global:学习每棵树前就提出候选切分点,并在每次分裂时都采用这种分割;
- Local:每次分裂前将重新提出候选切分点。
直观上来看,Local 策略需要更多的计算步骤,而 Global 策略因为节点没有划分所以需要更多的候选点。
下图给出不同种分裂策略的 AUC 变换曲线,横坐标为迭代次数,纵坐标为测试集 AUC,eps 为近似算法的精度,其倒数为桶的数量。
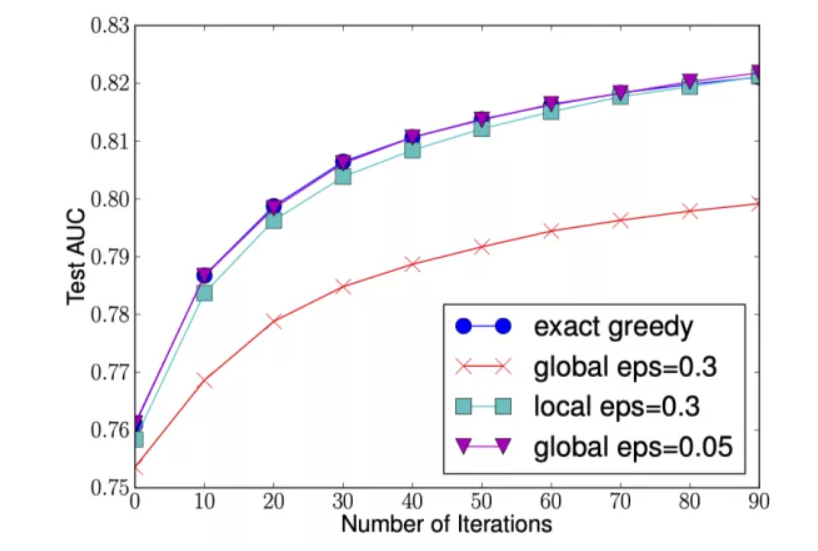
我们可以看到 Global 策略在候选点数多时(eps 小)可以和 Local 策略在候选点少时(eps 大)具有相似的精度。此外我们还发现,在 eps 取值合理的情况下,分位数策略可以获得与贪婪算法相同的精度。

1.1.4 加权分位数缩略图(weighted quantile sketch)

1.1.5 稀疏感知算法(缺失值处理)
实际应用中,稀疏数据无法避免,产生稀疏数据的原因:(1)数据缺失;(2)统计上的0;(3)特征表示中的one-hot形式。
在决策树的第一篇文章中我们介绍 CART 树在应对数据缺失时的分裂策略,XGBoost 也给出了其解决方案。
XGBoost 在构建树的节点过程中只考虑非缺失值的数据遍历,而为每个节点增加了一个缺省方向,当样本相应的特征值缺失时,可以被归类到缺省方向上,最优的缺省方向可以从数据中学到。至于如何学到缺省值的分支,其实很简单,分别枚举特征缺省的样本归为左右分支后的增益,选择增益最大的枚举项即为最优缺省方向。
假设样本的第i个特征缺失,无法使用该特征进行样本划分,那我们就把缺失样本默认的分到某个节点,具体分到哪个节点还要根据算法:
算法思想:分别假设缺失属于左节点和右节点,而且只在不缺失的样本上迭代,分别计算样本属于左子树和右子树的增益,选择增益最大的方向作为缺失数据的默认方向。
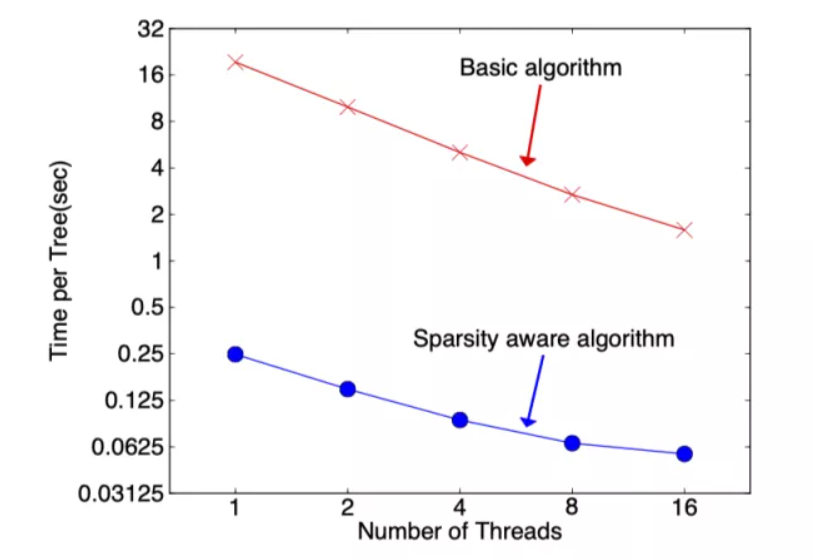
在构建树的过程中需要枚举特征缺失的样本,乍一看该算法的计算量增加了一倍,但其实该算法在构建树的过程中只考虑了特征未缺失的样本遍历,而特征值缺失的样本无需遍历只需直接分配到左右节点,故算法所需遍历的样本量减少,下图可以看到稀疏感知算法比 basic 算法速度块了超过 50 倍。
1.1.6 避免过拟合(正则化、shrinkage与采样技术)
1) 正则化
一说起过拟合,我们的第一反应就是正则化。XGBoost也是这样做的。
我们在loss_function里看到了正则化项(树的复杂度函数),正则化的目的就是防止过拟合。我们再看看这个函数:

这里出现了γ和λ,这是XGBoost自己定义的,在使用XGBoost时,你可以设定它们的值,显然,γ越大,表示越希望获得结构简单的树,因为要整体最小化的话就要最小化T。λ越大也是越希望获得结构简单的树。
2) Shrinkage
除了使用正则化,我们还有shrinkage与采样技术来避免过拟合的出现。
所谓的shrinkage就是在每次的迭代产生的树中,对每个叶子结点乘以一个缩减权重 (learning_rate,也叫eta),主要的目的就是缩减该次迭代产生的树的影响力,留给后边迭代生成的树更多发挥的空间。
举个栗子:比如第一棵树预测值为3.3,label为4.0,第二棵树才学0.7,那后面的树就没啥可学的了,所以给他打个折扣,比如3折,那么第二棵树训练的残差为4.0-3.3*0.3=3.01,这就可以发挥了啦,以此类推,作用的话,就是防止过拟合。
3) 采样技术
采样技术有两种,分别是行采样 (subsample) 和列采样 (colsample_bytree)。
列采样效果比较好的是按层随机的方法:之前提到,每次分裂节点的时候我们都要遍历所有的特征和分割点,来确定最优分割点。如果加入列采样,我们会在同一层的结点分割前先随机选一部分特征,遍历的时候只用遍历这部分特征就行了。
行采样则是采用bagging的思想,每次只抽取部分样本进行训练,不使用全部的样本,可以增加树的多样性。
1.2 工程实现
1.2.1 块结构设计 - 支持并行化
一直听别人说XGBoost能并行计算,感觉这才是XGBoost最bug的地方,但是直观上并不好理解,明明每次分裂节点都用到了上一次的结果,明明是个串行执行的过程,并行这个小妖精到底在哪?答案就是:选哪个feature进行分裂的时候,就是在枚举,选择最佳分裂点的时候进行。
注意:同层级节点之间可以并行。节点内选择最佳分裂点,候选分裂点计算增益使用并行。
(来自 https://mp.weixin.qq.com/s/qongHAx-X2SWrUxjk8tg0A)
我们知道,决策树的学习最耗时的一个步骤就是在每次寻找最佳分裂点是都需要对特征的值进行排序。而 XGBoost 在训练之前对根据特征对数据进行了排序,然后保存到块结构中,并在每个块结构中都采用了稀疏矩阵存储格式(Compressed Sparse Columns Format,CSC)进行存储,后面的训练过程中会重复地使用块结构,可以大大减小计算量。
- 每一个块结构包括一个或多个已经排序好的特征;
- 缺失特征值将不进行排序;
- 每个特征会存储指向样本梯度统计值的索引,方便计算一阶导和二阶导数值;
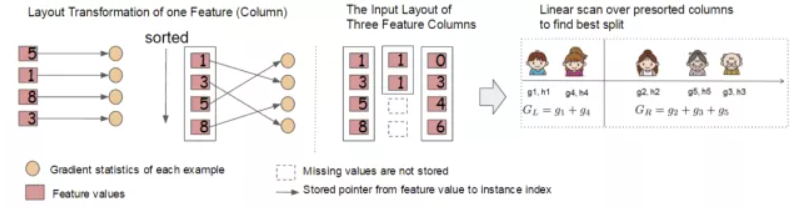
这种块结构存储的特征之间相互独立,方便计算机进行并行计算。在对节点进行分裂时需要选择增益最大的特征作为分裂,这时各个特征的增益计算可以同时进行,这也是 Xgboost 能够实现分布式或者多线程计算的原因。
1.2.2 缓存访问优化算法
块结构的设计可以减少节点分裂时的计算量,但特征值通过索引访问样本梯度统计值的设计会导致访问操作的内存空间不连续,这样会造成缓存命中率低,从而影响到算法的效率。
为了解决缓存命中率低的问题,XGBoost 提出了缓存访问优化算法:为每个线程分配一个连续的缓存区,将需要的梯度信息存放在缓冲区中,这样就是实现了非连续空间到连续空间的转换,提高了算法效率。
此外适当调整块大小,也可以有助于缓存优化。
1.2.3 “核外”块计算
当数据量过大时无法将数据全部加载到内存中,只能先将无法加载到内存中的数据暂存到硬盘中,直到需要时再进行加载计算,而这种操作必然涉及到因内存与硬盘速度不同而造成的资源浪费和性能瓶颈。为了解决这个问题,XGBoost 独立一个线程专门用于从硬盘读入数据,以实现处理数据和读入数据同时进行。
此外,XGBoost 还用了两种方法来降低硬盘读写的开销:
- 块压缩:对 Block 进行按列压缩,并在读取时进行解压;
- 块拆分:将每个块存储到不同的磁盘中,从多个磁盘读取可以增加吞吐量。
1.3 优缺点
1.3.1 优点
- 精度更高:GBDT 只用到一阶泰勒展开,而 XGBoost 对损失函数进行了二阶泰勒展开。XGBoost 引入二阶导一方面是为了增加精度,另一方面也是为了能够自定义损失函数,二阶泰勒展开可以近似大量损失函数;
- 灵活性更强:GBDT 以 CART 作为基分类器,XGBoost 不仅支持 CART 还支持线性分类器,(使用线性分类器的 XGBoost 相当于带 L1 和 L2 正则化项的Logistic回归(分类问题)或者线性回归(回归问题))。此外,XGBoost 工具支持自定义损失函数,只需函数支持一阶和二阶求导;
- 正则化:XGBoost 在目标函数中加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、叶子节点权重的 L2 范式。正则项降低了模型的方差,使学习出来的模型更加简单,有助于防止过拟合;
- Shrinkage(缩减):相当于学习速率。XGBoost 在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间;
- 列抽样:XGBoost 借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算;
- 缺失值处理:XGBoost 采用的稀疏感知算法极大的加快了节点分裂的速度;
- 可以并行化操作:块结构可以很好的支持并行计算。
1.3.2 缺点
- 虽然利用预排序和近似算法可以降低寻找最佳分裂点的计算量,但在节点分裂过程中仍需要遍历数据集;
- 预排序过程的空间复杂度过高,不仅需要存储特征值,还需要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存。
1.4 与GBDT的比较
来自 https://mp.weixin.qq.com/s/qongHAx-X2SWrUxjk8tg0A
1.4.1 共同点
二者都是由一堆回归树构成的模型(本次训练的模型基于上次训练的模型)。传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的Logistic回归(分类问题)或者线性回归(回归问题)。
二都是最小化损失函数的思想,求最优的决策树。
1.4.2 不同点
第一眼的感觉XGBoost更好的地方其实就是正则化+并行化。
二者最小化损失函数的方法不同。GBDT使用的是Gradient Descent方法,优化时只用到了损失函数的一阶导数信息(有人说残差其实就是这里的梯度,不是很理解),拟合上一个模型产生的残差。而XGBoost使用的则是牛顿法,优化时同时用到了一阶导数和二阶导数信息(−gi(1+hi)),其实这个值就是每个叶子节点的预测值(对推导过程有兴趣的朋友请移步参考博文2)。
GBDT分割点的选择通过枚举训练样本集上的特征值来完成,分割点的选择依据则是减少Loss。 XGBoost使用的则是将最小化的目标函数值作为打分函数,提出了一个Gain的公式来划分样本。
XGBoost还支持自定义损失函数,只要能够二阶泰勒展开的函数都可以作为损失函数。
采样方法(Shrinkage)
分裂结点的算法(Weighted Quantile Sketch)
XGBoost动手实践
本部分内容来源于 我的XGBoost学习经历及动手实践
1. 引入基本工具库
1 | # 引入基本工具库 |
2. XGBoost原生工具库的上手
更详细的参数设置见后面
1 | import xgboost as xgb # 引入工具库 |
3. XGBoost的参数设置
(括号内的名称为sklearn接口对应的参数名字)
更详细的介绍见 官方文档.
XGBoost的参数分为三种:
3.1. 通用参数
- booster: 使用哪个弱学习器训练,默认gbtree,可选gbtree,gblinear或 dart
- booster参数:控制每一步的booster (tree/regression). 因为tree的性能比线性回归好得多,因此我们很少用线性回归.
gbtreeanddartuse tree based models whilegblinearuses linear functions.- nthread:用于运行XGBoost的并行线程数,默认为最大可用线程数
- verbosity:打印消息的详细程度。默认值为1,有效值为0(静默),1(警告),2(信息),3(调试)。
tree booster:
Tree Booster的参数:
eta(learning_rate):learning_rate,在更新中使用步长收缩以防止过度拟合,默认= 0.3,范围:[0,1];典型值一般设置为:0.01-0.2
gamma(min_split_loss):默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。范围:[0,∞]
max_depth:默认= 6,一棵树的最大深度。增加此值将使模型更复杂,并且更可能过度拟合。范围:[0,∞]
min_child_weight:默认值= 1,如果新分裂的节点的样本权重和小于min_child_weight则停止分裂 。这个可以用来减少过拟合,但是也不能太高,会导致欠拟合。范围:[0,∞]
max_delta_step:默认= 0,允许每个叶子输出的最大增量步长。如果将该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守。通常不需要此参数,但是当类极度不平衡时,它可能有助于逻辑回归。将其设置为1-10的值可能有助于控制更新。范围:[0,∞]
subsample:默认值= 1,构建每棵树对样本的采样率,如果设置成0.5,XGBoost会随机选择一半的样本作为训练集。范围:(0,1]
sampling_method:默认= uniform,用于对训练实例进行采样的方法。
- uniform:每个训练实例的选择概率均等。通常将subsample> = 0.5 设置 为良好的效果。
- gradient_based:每个训练实例的选择概率与规则化的梯度绝对值成正比,具体来说就是 \(\sqrt{g^2+\lambda h^2}\),subsample可以设置为低至0.1,而不会损失模型精度。
colsample_bytree:默认= 1,列采样率,也就是特征采样率。范围为(0,1]
lambda(reg_lambda):默认=1,L2正则化权重项。增加此值将使模型更加保守。
alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。
tree_method:默认=auto,XGBoost中使用的树构建算法。可选:
auto,exact,approx,hist,gpu_hist
- auto:使用启发式选择最快的方法。
- 对于小型数据集,将使用精确贪婪
exact。- 对于较大的数据集,将选择近似算法
approx。建议尝试hist,gpu_hist,对于大量的数据有更高的性能。gpu_hist支持 external memory 外部存储器。
- exact:精确的贪婪算法。枚举所有拆分的候选点。
- approx:使用分位数和梯度直方图的近似贪婪算法。
- hist:更快的直方图优化的近似贪婪算法。(LightGBM也是使用直方图算法)
- gpu_hist:GPU hist算法的实现。
scale_pos_weight: 默认值1,控制正负权重的平衡,这对于不平衡的类别很有用。Kaggle竞赛一般设置 sum(negative instances) / sum(positive instances),在类别高度不平衡的情况下,将参数设置大于0,可以加快收敛。
num_parallel_tree:默认=1,每次迭代期间构造的并行树的数量。此选项用于支持增强型随机森林。
monotone_constraints:可变单调性的约束,在某些情况下,如果有非常强烈的先验信念认为真实的关系具有一定的质量,则可以使用约束条件来提高模型的预测性能。(例如params_constrained['monotone_constraints'] = "(1,-1)",(1,-1)告诉XGBoost对第一个预测变量施加增加的约束,对第二个预测变量施加减小的约束。)
linear booster:
Linear Booster的参数:
lambda(reg_lambda):默认= 0,L2正则化权重项。增加此值将使模型更加保守。归一化为训练示例数。(Normalised to number of training examples.)
alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。归一化为训练示例数。
updater:默认= shotgun。
- shotgun:基于shotgun算法的平行坐标下降算法。使用“ hogwild”并行性,因此每次运行都产生不确定的解决方案。
- coord_descent:普通坐标下降算法。同样是多线程的,但仍会产生确定性的解决方案。
feature_selector:默认= cyclic。特征选择和排序方法
- cyclic:通过每次循环一个特征来实现的。
- shuffle:类似于cyclic,但是在每次更新之前都有随机的特征变换。
- random:一个随机(有放回)特征选择器。
- greedy:选择梯度最大的特征。(贪婪选择)
- thrifty:近似贪婪特征选择(近似于greedy)
top_k:默认值为0,要选择的最重要特征数(在greedy和thrifty内)。The number of top features to select in
greedyandthriftyfeature selector. The value of 0 means using all the features.
3.2. 任务参数
学习目标参数。这个参数用来控制理想的优化目标和每一步结果的度量方法。
objective:默认=
reg:squarederror,表示最小平方误差。
reg:squarederror:最小平方误差。
reg:squaredlogerror:对数平方损失。
reg:logistic:逻辑回归
reg:pseudohubererror: 使用伪Huber损失进行回归,这是绝对损失的两倍可微选择。
binary:logistic:logistic regression for binary classification, output probability.
binary:logitraw:logistic regression for binary classification, output score before logistic transformation.
binary:hinge:二元分类的铰链损失(hinge loss)。这使预测为0或1,而不是产生概率。(SVM就是铰链损失函数)
count:poisson:计数数据的泊松回归,输出泊松分布的平均值。
survival:cox:针对正确的(right censored)生存时间数据进行Cox回归(负值被视为正确的生存时间)。
survival:aft:用于检查生存时间数据的加速故障时间模型。
aft_loss_distribution:Probabilty Density Function used bysurvival:aftobjective andaft-nloglikmetric.
multi:softmax:设置XGBoost以使用softmax目标进行多类分类,还需要设置num_class(类数)
multi:softprob:与softmax相同,但输出向量,可以进一步重整为矩阵。结果包含属于每个类别的每个数据点的预测概率。
rank:pairwise:使用LambdaMART进行成对排名,从而使成对损失最小化。
rank:ndcg:使用LambdaMART进行列表式排名,使标准化折让累积收益(NDCG)最大化。
rank:map:使用LambdaMART进行列表平均排名,使平均平均精度(MAP)最大化。
reg:gamma:使用对数链接(log-link)进行伽马回归。输出是伽马分布的平均值。
reg:tweedie:使用对数链接进行Tweedie回归。eval_metric:验证数据的评估指标,将根据objective分配默认指标 (rmse for regression, and error for classification, mean average precision for ranking),用户可以添加多个评估指标 (Python users: remember to pass the metrics in as list of parameters pairs instead of map)
rmse,均方根误差;
rmsle:均方根对数误差;Default metric of
reg:squaredlogerrorobjective.mae:平均绝对误差;
mphe:平均伪Huber错误;
logloss:负对数似然;
error:二元分类错误率; It is calculated as
#(wrong cases)/#(all cases)merror:多类分类错误率;
mlogloss:多类logloss;
auc:曲线下面积;
aucpr:PR曲线下的面积;
ndcg:归一化累计折扣;
map:平均精度;
seed :随机数种子,[默认= 0]。
3.3. 命令行参数
这里不说了,因为很少用命令行控制台版本。(only used in the console version of XGBoost)
4. XGBoost的调参说明
参数调优的一般步骤:
- 1.确定(较大)学习速率和提升参数调优的初始值
- 2.max_depth 和 min_child_weight 参数调优
- 3.gamma参数调优
- 4.subsample 和 colsample_bytree 参数调优
- 5.正则化参数alpha调优
- 6.降低学习速率和使用更多的决策树
5. XGBoost详细攻略
更详细内容见官方文档
1). 安装XGBoost
1 | pip3 install xgboost |
2). 数据接口(XGBoost可处理的数据格式DMatrix)
The XGBoost python module is able to load data from:
- LibSVM text format file
- Comma-separated values (CSV) file
- NumPy 2D array
- SciPy 2D sparse array
- cuDF DataFrame
- Pandas data frame, and
- XGBoost binary buffer file.
(See Text Input Format of DMatrix for detailed description of text input format.)
The data is stored in a DMatrix
object.
1 | # 1.LibSVM文本格式文件 |
笔者推荐:先保存到XGBoost二进制文件中将使加载速度更快,然后再加载进来
Saving DMatrix
into a XGBoost binary file will make loading faster:
1 | # 1.保存DMatrix到XGBoost二进制文件中 |
3). 参数的设置方式
1 | # 加载并处理数据 |
XGBoost can use either a list of pairs or a dictionary to set parameters. For instance:
Booster parameters
1
2
3param = {'max_depth': 2, 'eta': 1, 'objective': 'binary:logistic'}
param['nthread'] = 4
param['eval_metric'] = 'auc'You can also specify multiple eval metrics:
1
2
3
4
5param['eval_metric'] = ['auc', 'ams@0']
# alternatively:
# plst = param.items()
# plst += [('eval_metric', 'ams@0')]Specify validations set to watch performance
1
evallist = [(dtest, 'eval'), (dtrain, 'train')]
4). 训练
注:貌似现在不需要plst = param.items(),直接传
param
1 | # 2.训练 |
5). 保存模型
1 | # 3.保存模型 |
6) . 加载保存的模型
1 | # 4.加载保存的模型: |
7). 设置早停机制
1 | # 5.也可以设置早停机制(需要设置验证集) |
The model will train until the validation score stops improving.
Validation error needs to decrease at least every
early_stopping_rounds to continue training.
If early stopping occurs, the model will have three additional
fields: bst.best_score, bst.best_iteration and
bst.best_ntree_limit. Note that xgboost.train()
will return a model from the last iteration, not the best one.
This works with both metrics to minimize (RMSE, log loss, etc.) and
to maximize (MAP, NDCG, AUC). Note that if you specify more than one
evaluation metric the last one in param['eval_metric'] is
used for early stopping.
8). 预测
1 | # 6.预测 |
If early stopping is enabled during training, you can get predictions
from the best iteration with bst.best_ntree_limit:
1 | ypred = bst.predict(dtest, ntree_limit=bst.best_ntree_limit) |
9). 绘图
1 | # 1.绘制重要性 |
6. 实战案例
1). 分类案例
- Iris数据集
1 | from sklearn.datasets import load_iris |
1 | accuarcy: 96.67% |
- Titanic数据集
来自 https://mp.weixin.qq.com/s/qongHAx-X2SWrUxjk8tg0A

2). 回归案例
1 | import xgboost as xgb |
3). XGBoost调参(结合sklearn网格搜索)
1 | import xgboost as xgb |
决策树算法十问及经典面试问题
参考 https://mp.weixin.qq.com/s/vkbZweJ5oRo4IPt-3kg64g
https://blog.csdn.net/jaffe507/article/details/105004324
简介和算法
决策树是机器学习最常用的算法之一,它将算法组织成一颗树的形式。其实这就是将平时所说的if-then语句构建成了树的形式。这个决策树主要包括三个部分:内部节点、叶节点和边。内部节点是划分的属性,边代表划分的条件,叶节点表示类别。构建决策树就是一个递归的选择内部节点,计算划分条件的边,最后到达叶子节点的过程。


核心公式

| model | feature select | 树的类型 |
|---|---|---|
| ID3 | {分类:信息增益} | 多叉树 |
| C4.5 | {分类:信息增益率} | 多叉树 |
| CART (分类树) | {分类:基尼指数} | 二叉树 |
| CART (回归树) | {回归:平方误差} | 二叉树 |
算法十问
1.决策树和条件概率分布的关系?
决策树可以表示成给定条件下类的条件概率分布. 决策树中的每一条路径都对应是划分的一个条件概率分布. 每一个叶子节点都是通过多个条件之后的划分空间,在叶子节点中计算每个类的条件概率,必然会倾向于某一个类,即这个类的概率最大.
2.ID3和C4.5算法可以处理实数特征吗?如果可以应该怎么处理?如果不可以请给出理由?

3.既然信息增益可以计算,为什么C4.5还使用信息增益比?
在使用信息增益的时候,模型偏向于选择取值较多的特征。(可能会导致出现很多分支,将数据划分更细,模型复杂度高,出现过拟合的机率更大。)
使用信息增益比就是为了解决偏向于选择取值较多的特征的问题. 使用信息增益比对取值多的特征加上惩罚,对这个问题进行了校正.
4.基尼指数可以表示数据不确定性,信息熵也可以表示数据的不确定性. 为什么CART使用基尼指数?
信息熵、基尼指数都是值越大,数据的不确定性越大. 信息熵需要计算对数,计算量大;信息熵可以处理多个类别,基尼指数就是针对两个类计算的,由于CART树是一个二叉树,每次都是选择yes or no进行划分,从这个角度也是应该选择简单的基尼指数进行计算.
5.决策树怎么剪枝?
一般算法在构造决策树时都是尽可能的细分,直到数据不可划分才会到达叶子节点,停止划分. 因为给训练数据巨大的信任,这种形式形式很容易造成过拟合,为了防止过拟合需要进行决策树剪枝.
一般分为预剪枝和后剪枝:
1)预剪枝是在决策树的构建过程中加入限制,比如控制叶子节点最少的样本个数,提前停止.
预剪枝(提前停止):控制深度、当前的节点数、分裂对测试集的准确度提升大小
- 限制树的高度,可以利用交叉验证选择
- 利用分类指标,如果下一次切分没有降低误差,则停止切分
- 限制树的节点个数,比如某个节点小于100个样本,停止对该节点切分
2)后剪枝是在决策树构建完成之后,根据加上正则项的结构风险最小化自下向上进行的剪枝操作. 剪枝的目的就是防止过拟合,使模型在测试数据上变现良好,更加鲁棒.
后剪枝(自底而上):生成决策树、交叉验证剪枝:子树删除,节点代替子树、测试集准确率判断决定剪枝.
6.ID3算法,为什么不选择具有最高预测精度的属性特征,而是使用信息增益?
7.为什么使用贪心和启发式搜索建立决策树,为什么不直接使用暴力搜索建立最优的决策树?
决策树目的是构建一个与训练数据拟合很好,并且复杂度小的决策树. 因为从所有可能的决策树中直接选择最优的决策树是NP完全问题,在使用中一般使用启发式方法学习相对最优的决策树.
8.如果特征很多,决策树中最后没有用到的特征一定是无用吗?
不是无用的,从两个角度考虑,一是特征替代性,如果已经使用的特征A和特征B可以替代特征C,特征C可能就没有被使用,但是如果把特征C单独拿出来进行训练,依然有效. 其二,决策树的每一条路径就是计算条件概率的条件,前面的条件如果包含了后面的条件,只是这个条件在这棵树中是无用的,如果把这个条件拿出来也是可以帮助分析数据。
9.决策树的优缺点?
优点:
决策树模型可读性好,具有描述性,有助于人工分析;
基本不需要预处理,不需要提前归一化,处理缺失值;
对于异常点的容错能力好,健壮性高;
效率高,决策树只需要一次性构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
缺点:
决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进;
对中间值的缺失敏感;
决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决;
寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善;
有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决;
如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
10.基尼系数存在的问题?
基尼指数偏向于多值属性;当类数较大时,基尼指数求解比较困难;基尼指数倾向于支持在两个分区中生成大小相同的测试。
面试真题
1.决策树如何防止过拟合?
2.信息增益比相对信息增益有什么好处?
3.如果有异常值或者数据分布不均匀,会对决策树有什么影响?
4.手动构建CART的回归树的前两个节点,给出公式每一步的公式推到?
5.决策树和其他模型相比有什么优点?
6.决策树的目标函数是什么?
7.树形结构为什么不需要归一化?
- 数值缩放不影响分裂点位置,对树模型的结构不造成影响。
- 按照特征值进行排序的,排序的顺序不变,那么所属的分支以及分裂点就不会有不同。
- 树模型是不能进行梯度下降的,因为构建树模型(回归树)寻找最优点时是通过寻找最优分裂点完成的,因此树模型是阶跃的,阶跃点是不可导的,并且求导没意义,也就不需要归一化。
以下内容来自 https://www.cnblogs.com/liuyingjun/p/10590095.html
引自知乎——数据取经团:吕洞宾
面试官:小张同学,你好,看了你的简历,对相关算法还是略懂一些,下面开始我们的面试,有这么一个场景,在一个样本集中,其中有100个样本属于A,9900个样本属于B,我想用决策树算法来实现对AB样本进行区分,这时会遇到什么问题:
小张:欠拟合现象,因为在这个样本集中,AB样本属于严重失衡状态,在建立决策树算法的过程中,模型会更多的偏倚到B样本的性质,对A样本的性质训练较差,不能很好的反映样本集的特征。
面试官:看你决策树应该掌握的不错,你说一下自己对于决策树算法的理解?
小张:决策树算法,无论是哪种,其目的都是为了让模型的不确定性降低的越快越好,基于其评价指标的不同,主要是ID3算法,C4.5算法和CART算法,其中ID3算法的评价指标是信息增益,C4.5算法的评价指标是信息增益率,CART算法的评价指标是基尼系数。
面试官:信息增益,好的,这里面有一个信息论的概念,你应该知道的吧,叙述一下
小张:香农熵,随机变量不确定性的度量。利用ID3算法,每一次对决策树进行分叉选取属性的时候,我们会选取信息增益最高的属性来作为分裂属性,只有这样,决策树的不纯度才会降低的越快。
面试官:OK,你也知道,在决策树无限分叉的过程中,会出现一种现象,叫过拟合,和上面说过的欠拟合是不一样的,你说一下过拟合出现的原因以及我们用什么方法来防止过拟合的产生?
小张:对训练数据预测效果很好,但是测试数据预测效果较差,则称出现了过拟合现象。对于过拟合现象产生的原因,有以下几个方面,第一:在决策树构建的过程中,对决策树的生长没有进行合理的限制(剪枝);第二:在建模过程中使用了较多的输出变量,变量较多也容易产生过拟合;第三:样本中有一些噪声数据,噪声数据对决策树的构建的干扰很多,没有对噪声数据进行有效的剔除。对于过拟合现象的预防措施,有以下一些方法,第一:选择合理的参数进行剪枝,可以分为预剪枝后剪枝,我们一般用后剪枝的方法来做;第二:K-folds交叉验证,将训练集分为K份,然后进行K次的交叉验证,每次使用K-1份作为训练样本数据集,另外的一份作为测试集合(作者说反了,应该是份作为测试集,其余k-1份作为训练集); 第三:减少特征,计算每一个特征和响应变量的相关性,常见的为皮尔逊相关系数,将相关性较小的变量剔除,当然还有一些其他的方法来进行特征筛选,比如基于决策树的特征筛选,通过正则化的方式来进行特征选取等。
面试官:你刚刚前面有提到预剪枝和后剪枝,当然预剪枝就是在决策树生成初期就已经设置了决策树的参数,后剪枝是在决策树完全建立之后再返回去对决策树进行剪枝,你能否说一下剪枝过程中可以参考的某些参数?
小张:剪枝分为预剪枝和后剪枝,参数有很多,在R和Python中都有专门的参数来进行设置,下面我以Python中的参数来进行叙述,max_depth(树的高度),min_samples_split(叶子结点的数目),max_leaf_nodes(最大叶子节点数),min_impurity_split(限制不纯度),当然R语言里面的rpart包也可以很好的处理这个问题。
面试官:对了,你刚刚还说到了用决策树来进行特征的筛选,现在我们就以ID3算法为例,来说一下决策树算法对特征的筛选?
小张:对于离散变量,计算每一个变量的信息增益,选择信息增益最大的属性来作为结点的分裂属性;对于连续变量,首先将变量的值进行升序排列,每对相邻值的中点作为可能的分离点,对于每一个划分,选择具有最小期望信息要求的点作为分裂点,来进行后续的决策数的分裂。
面试官:你刚刚还说到了正则化,确实可以对过拟合现象来进行很好的调整,基于你自己的理解,来说一下正则化?
小张:这一块的知识掌握的不是很好,我简单说一下自己对这一块的了解。以二维情况为例,在L1正则化中,惩罚项是绝对值之和,因此在坐标轴上会出现一个矩形,但是L2正则化的惩罚项是圆形,因此在L1正则化中增大了系数为0的机会,这样具有稀疏解的特性,在L2正则化中,由于系数为0的机率大大减小,因此不具有稀疏解的特性。但是L1没有选到的特性不代表不重要,因此L1和L2正则化要结合起来使用。
面试官:还可以吧!正则化就是在目标函数后面加上了惩罚项,你也可以将后面的惩罚项理解为范数。分类算法有很多,逻辑回归算法也是我们经常用到的算法,刚刚主要讨论的是决策树算法,现在我们简单聊一下不同分类算法之间的区别吧!讨论一下决策树算法和逻辑回归算法之间的区别?
小张:分为以下几个方面:第一,逻辑回归着眼于对整体数据的拟合,在整体结构上优于决策树; 但是决策树采用分割的方法,深入到数据内部,对局部结构的分析是优于逻辑回归;第二,逻辑回归对线性问题把握较好,因此我们在建立分类算法的时候也是优先选择逻辑回归算法,决策树对非线性问题的把握较好;第三,从本质来考虑,决策树算法假设每一次决策边界都是和特征相互平行或垂直的,因此会将特征空间划分为矩形,因而决策树会产生复杂的方程式,这样会造成过拟合现象;逻辑回归只是一条平滑的边界曲线,不容易出现过拟合现象。