隐语义模型
来源于:
https://github.com/NLP-LOVE/ML-NLP/tree/master/Project/17.%20Recommendation%20System
1. 基本思想
推荐系统中一个重要的分支,隐语义建模。隐语义模型LFM:Latent Factor Model,其核心思想就是通过隐含特征联系用户兴趣和物品。
过程分为三个部分,将物品映射到隐含分类,确定用户对隐含分类的兴趣,然后选择用户感兴趣的分类中的物品推荐给用户。它是基于用户行为统计的自动聚类。
隐语义模型在Top-N推荐中的应用十分广泛。常用的隐语义模型,LSA(Latent Semantic Analysis),LDA(Latent Dirichlet Allocation),主题模型(Topic Model),矩阵分解(Matrix Factorization)等等。
首先通过一个例子来理解一下这个模型,比如说有两个用户A和B,目前有用户的阅读列表,用户A的兴趣涉及侦探小说,科普图书以及一些计算机技术书,而用户B的兴趣比较集中在数学和机器学习方面。那么如何给A和B推荐图书呢?
对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后在给他们推荐那些用户喜欢的其他书。 对于ItemCF, 需要给他们推荐和他们已经看的书相似的书,比如用户B 看了很多数据挖掘方面的书,那么可以给他推荐机器学习或者模式识别方面的书。
还有一种方法就是使用隐语义模型,可以对书和物品的兴趣进行分类。对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。
2 模型理解
- 如何给物品进行分类?
- 如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度?
- 对于一个给定的类,选择哪些属于这个类的物品推荐给用户,以及如何确定这些物品在一个类中的权重?
为了解决上面的问题,研究人员提出:为什么我们不从数据出发,自动地找到那些类,然后进行个性化推荐,隐语义分析技术因为采取基于用户行为统计的自动聚类,较好地解决了上面的问题。隐语义分析技术从诞生到今天产生了很多著名的模型和方法,其中和推荐技术相关的有pLSA,LDA,隐含类别模型(latent class model), 隐含主题模型(latent topic model), 矩阵分解(matrix factorization)。
隐语义模型LFM通过如下公式计算用户 u 对物品 i 的兴趣:
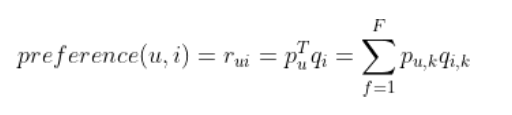
这个公式中 \(p_{u,k}\) 和 \(q_{i,k}\) 是模型的参数,其中 \(p_{u,k}\) 度量了用户 u 的兴趣和第 k 个隐类的关系,而 \(q_{i,k}\) 度量了第 k 个隐类和物品 i 之间的关系。那么,下面的问题就是如何计算这两个参数。
对最优化理论或者机器学习有所了解的读者,可能对如何计算这两个参数都比较清楚。这两个参数是从数据集中计算出来的。要计算这两个参数,需要一个训练集,对于每个用户u,训练集里都包含了用户u喜欢的物品和不感兴趣的物品,通过学习这个数据集,就可以获得上面的模型参数。