Precision, Recall, ROC曲线等
1.Precision, Recall
准确率 \(Accuracy = \frac{TP+TN}{TP+TN+FP+FN}\)
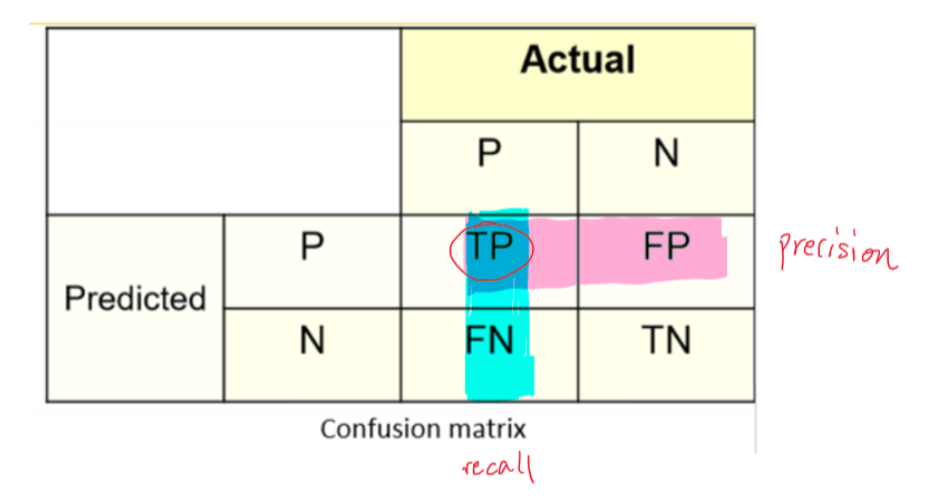
精确率 \(Precision = \frac{TP}{TP+FP}\),预测为positive中,实际为positive的比例,反映分类器的准确性
召回率 \(Recall = \frac{TP}{TP+FN}\),实际为positive中,预测为positive的比例,反映分类器的完备性
F值为精确率和召回率的调和平均: \[
F1\_Score=\frac{2*Precision*Recall}{Precision+Recall}
\]
什么情况下更注重哪个指标?
注重 \(Precision = \frac{TP}{TP+FP}\),希望 FP 小 -> 判断为正实际为负的情况少 -> 垃圾邮件 (垃圾邮件为1)
注重 \(Recall = \frac{TP}{TP+FN}\),希望 FN 小 -> 判断为负实际为正的情况少 -> 信贷风控 (坏客户为1)
2.TPR,FPR
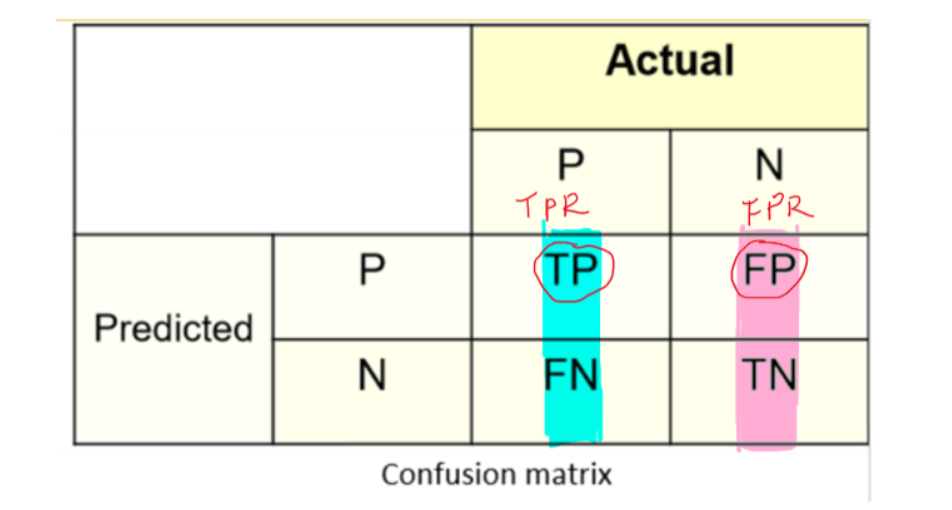
\[ TPR (True\ Positive\ Rate) = \frac{TP}{TP+FN} \]
TPR 等价于 Recall,正样本中正确分类的比例(所有真实的1中,有多少被模型成功选出) \[ FPR(False\ Positive\ Rate) = \frac{FP}{FP+TN} \] FPR,负样本中错分的比例(所有真实的0中,有多少被模型误判为1)
3. Sensitivity, Specificity
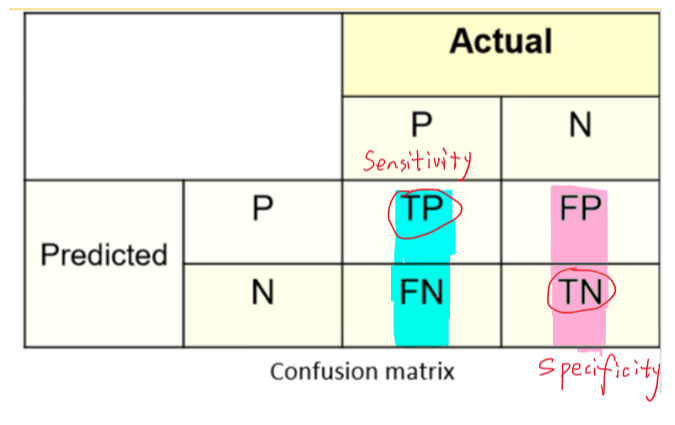
灵敏度 \(Sensitivity = \frac{TP}{TP+FN}\),等价于 Recall,正样本中正确分类的比例 (Accuracy with respect to positive cases, also called True Positive Rate)
特异度 \(Specificity = \frac{TN}{TN+FP}\),负样本中正确分类的比例 (Accuracy with respect to negative cases)
\(FPR=1-Specificity\)
4. ROC 曲线
最理想的模型,当然是 TPR 尽量高而 FPR 尽量低,然而任何模型在提高正确预测概率的同时,也会难以避免地增加误判率,ROC曲线非常形象地表达了二者之间的关系。
ROC曲线是一个画在二维平面上的曲线,横坐标是FPR(负样本中错分的比例),纵坐标是TPR(正样本中正确分类的比例)。对某个分类器而言,根据其在测试样本上的表现可以得到一个(FPR,TPR)点对,调整分类时使用的阈值,可以得到一个曲线,就是ROC曲线。一般情况下,这个曲线应该处于对角线的上方(对角线代表的是一个随机分类器)。
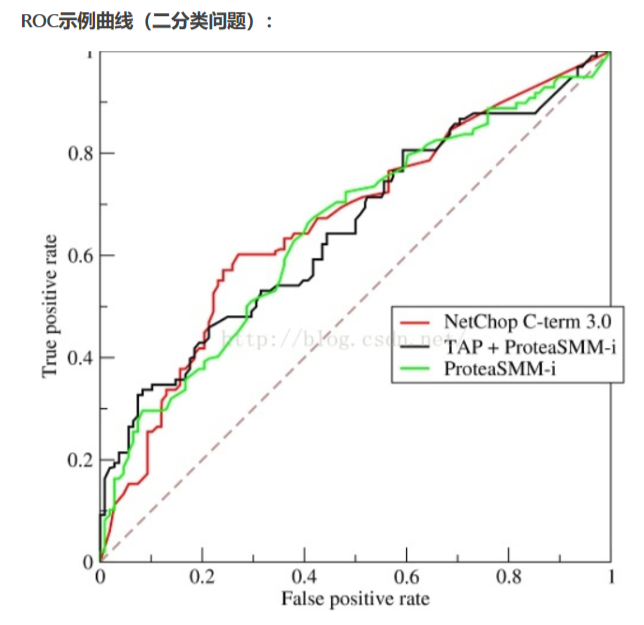
ROC曲线越靠近左上角越好。
具体绘制过程: 对于一个二分类模型,输出的最初结果是连续的(概率);假设已经确定一个阈值,那么最初结果大于阈值时,则输出最终结果为1,小于阈值则输出为0。假如阈值取值为0.6,那么 FPR 和 TPR 就可以计算出此时的取值,标记为一个点,记为 (FPR1,TPR1); 如果阈值取值为0.5,同理可以计算出另一个点,记为 (FPR2,TPR2)。设定不同的阈值,就可以计算不同的点 (FPR,TPR),以 FPR 为横坐标, TPR 为纵坐标,把不同的点连成曲线,就得到了ROC曲线。
阈值为0时,所有预测均会被判为正例,此时 (FPR,TPR)=(1,1);阈值为1时,所有预测均会被判为负例,此时 (FPR,TPR)=(0,0) 即ROC曲线,从原点往后的走势,阈值是逐渐减小的。
那么问题来了,阈值如何确定?
以Logistic模型为例,模型输出的结果其实是概率,我们通过设定阈值,把概率转化为最终的输出结果0和1。直观想法,是把(0,1)区间进行等分,比如等分为十个区间,那么就可以分别以0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9为阈值;计算出不同的(FPR,TPR)值;最后把点之间进行连线,即得到ROC曲线。然而这种方法有缺陷,见下面的示例。
下面,我们以某商业银行某时间段内某支行客户的逾期相关数据为例详细说明:P 代表此支行的某客户的逾期率(暂且定义为在此时间段内某客户的逾期可能性),Y 代表是否为高逾期客户,X 是与逾期有关的相关指标,比如行业、企业规模、客户的五级分类等等。
然而,我们发现计算出的概率值都落在 [0.0092,0.578] 区间范围内,这种情况下,如果还用上面的“直观想法”,那么设定阈值为0.1到0.5时,能够计算出不同的 (FPR,TPR) 值;而将阈值取到0.6到0.9时,模型的判定结果为所有的样本就都是0了……so sad!此时计算出的 (FPR,TPR) 值都是 (0,0),ROC曲线的点由11个变成了6个.
面对这个特殊案例,我们的直观想法肯定需要改进。于是最终,我们的实现方法是:
- 把(0,1)区间升级为(min(P),max(P));
- 取值(min(P),max(P))/10,设定阈值为(min(P),max(P))*k/10,其中k=1,2,3,…,9;
- 根据不同的阀值,计算出不同的(FPR,TPR)值。
这时候再画出ROC曲线,就避免了上面的问题。然而小伙伴又发问了:这样在写代码实现的过程中,每次都要和阈值进行比较,计算量比较大,不如先对样本计算出的概率值从小到大排序,取前百分之几(比如10%)处的值为阈值,排在这之后的判定为0,其他则判定为1。这样计算量就少了很多!
于是,我们继续改进阈值的设置,**首先把Logistic模型输出的概率从小到大排序,然后取10%的值(也就是概率值)作为阈值,同理把10%*k(k=1,2,3,…,9)处的值作为阈值,计算出不同的(FPR,TPR)值,**就可以画出ROC曲线啦。
可是,从小到大排序之后,每次取前百分之几处的值为阈值呢?总共分成10份还是100还是1000份呢?有选择困难症的小伙伴又纠结了,告诉你个办法,别纠结,有多少个模型输出的概率值就分成多少份,不再考虑百分之几!比如Logistic模型输出的概率有214个,那么我们把214个目标变量从小到大进行排序,然后分别以这214个的概率值为阈值,可以计算出214个不同的(FPR,TPR)值,也可以画出ROC曲线。
ROC曲线画好后,就要发挥用处!对于一个模型一组参数可以画出一条ROC曲线,此时最优的阈值是什么呢(即以什么阈值为准,去最终划分为0,1)?TPR和FPR是正相关的,也就是说,正确判定出1的数量增加时,必然要伴随着代价:误判为1的FP也增加。
从ROC曲线上也可以反映出这种变化,从ΔTPR>ΔFPR到ΔTPR<ΔFPR(一开始曲线比较陡,TPR增长得快,FPR增长得慢,即ΔTPR>ΔFPR;到后面,曲线比较平缓,TPR增长得慢,FPR增长得快,有ΔTPR<ΔFPR),最理想的阀值是ΔTPR=ΔFPR时。但是在实际应用中,我们很少能够给出ROC曲线的函数表达式,这时的解决方法包括:
给出ROC曲线的拟合函数表达式,然后计算出最优的阈值,这个目前通过软件实现难度不大:如何给出最优拟合函数,计算数学上有很多方法;计算出 ΔTPR≈ΔFPR 的点即为最优的阀值。
从业务上给出最优的阀值。
4.1 AUC指标
对模型进行调参时,可以画出多条ROC曲线,此时哪组参数是最优的呢?我们可以结合AUC指标,哪组参数的AUC值越高,说明此组参数下的模型效果越好。
AUC (Area Under the ROC Curve) 值:ROC曲线下的面积,取值范围在 0.5 到 1 之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
另外,在SAS的评分模型输出中,常用来判断收入分配公平程度的gini系数也用来评价模型,此时gini=2*AUC-1.
4.2 ROC曲线的特性
既然已经有这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布(比例)变化的时候,ROC曲线能保持不变。当数据中存在类不平衡现象时可以使用ROC曲线来评估模型的性能。 在实际的数据集中,经常出现类不平衡现象,即负样本比正样本多很多(或者相反),而且测试集中的样本分布也可能随时间变化,ROC曲线在此时可以发挥很好的作用。 下图是 ROC 曲线和 Precision-Recall 曲线的对比:
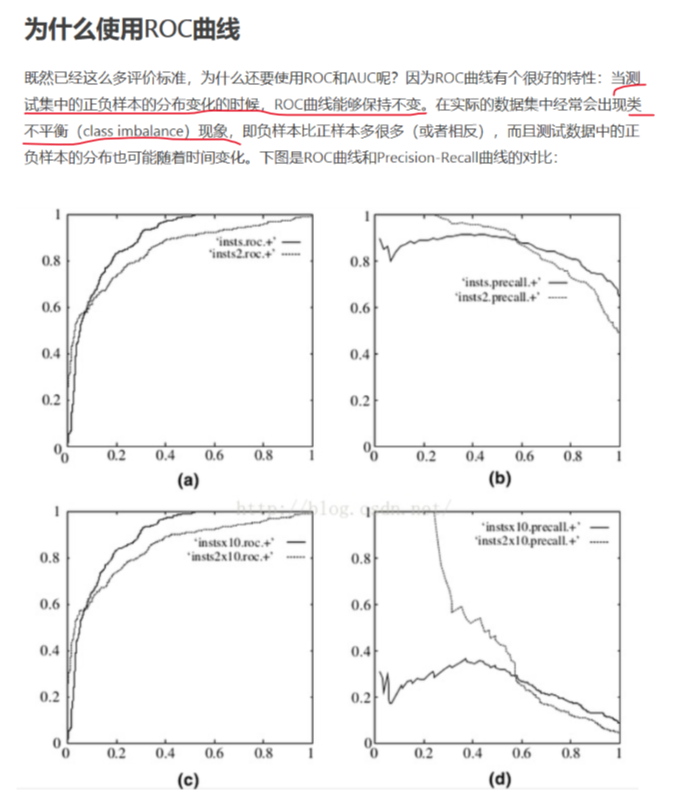
上图中,(a)和(c)为 ROC 曲线,(b)和(d)为 Precision-Recall 曲线。(a)和(b)展示的是分类器在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的10倍后分类器的结果。可以明显看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。
5. KS 曲线
参考:
【建模基础课】ROC、K-S,教你巧妙使用模型评价指标
KS(Kolmogorov-Smirnov)值
模型指标—KS
https://ppppqp.github.io/note/ml/ROC/
https://zhuanlan.zhihu.com/p/79934510
https://www.k2analytics.co.in/7-important-model-performance-measures
常用的模型评价还有K-S曲线,它和ROC曲线的画法异曲同工。以Logistic模型为例,首先把Logistic模型输出的概率从大到小排序,然后取10%的值(也就是概率值)作为阈值,同理把10%*k(k=1,2,3,…,9)处的值作为阀值,计算出不同的FPR和TPR值,以10%*k(k=1,2,3,…,9)为横坐标(以阈值为横坐标),分别以TPR和FPR的值为纵坐标,就可以画出两个曲线,这就是K-S曲线。
从K-S曲线就能衍生出KS值,KS=max(TPR-FPR)(或者KS=max(|TPR-FPR|)),即是两条曲线之间的最大间隔距离。当(TPR-FPR)最大时,也就是ΔTPR-ΔFPR=0,这和ROC曲线上找最优阈值的条件ΔTPR=ΔFPR是一样的。从这点也可以看出,ROC曲线、K-S曲线、KS值的本质是相同的。
另一种常见的描述KS的计算方法:KS = max(|cum_bad_rate - cum_good_rate|)。两种说法其实是一致的。其中
cum_bad_rate
为累计正样本数占总正样本的比例(这里的累计指预测概率大于阈值的样本中),等价于TPR,所有实际为1中,按当前阈值划分时,预测为1的有多少(所有正样本中,当前累计抓出了多少);cum_good_rate
为累计负样本数占总负样本数的比例,等价于FPR,所有实际为0中,按当前阈值划分时,被误判为1的有多少(当前累计负样本数实际就是被误判为1的)(所有负样本中当前累计抓出了多少)。
例1:
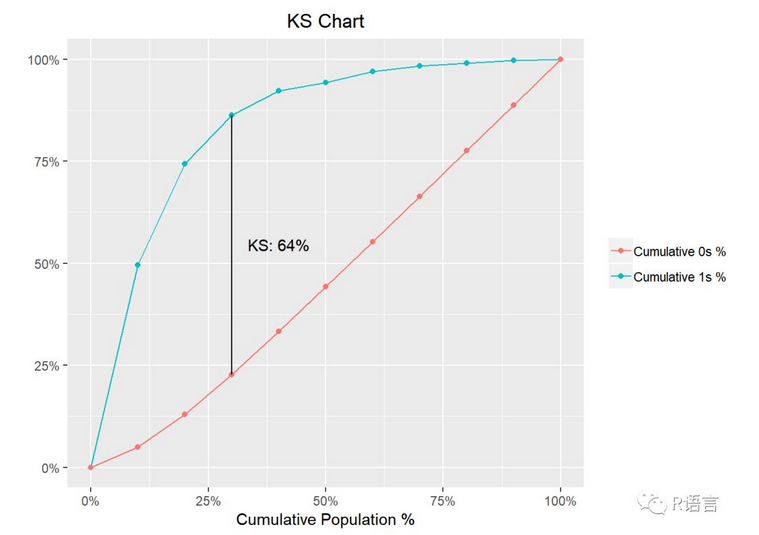
以上图为例,蓝色的线是TPR,红色的线是FPR,通常TPR会在FPR的上方。横坐标是阈值,从左到右阈从1到0逐渐减小。TPR与FPR随着阈值从1到0,取值均从0到1,逐渐增长,且TPR的走势一般是concave up(上凹)的,即一开始增长较快,后面逐渐减慢,FPR的走势一般是concave down(下凹)的,一开始增长较慢,后面逐渐加快。其实也很好理解,一开始阈值较大时,例如0.9,抓出的正样本数(TP)通常会大于抓出的负样本数(FP)。而两条曲线增长速度的转折点就是ks取值最大的时候。通常如下图所示:
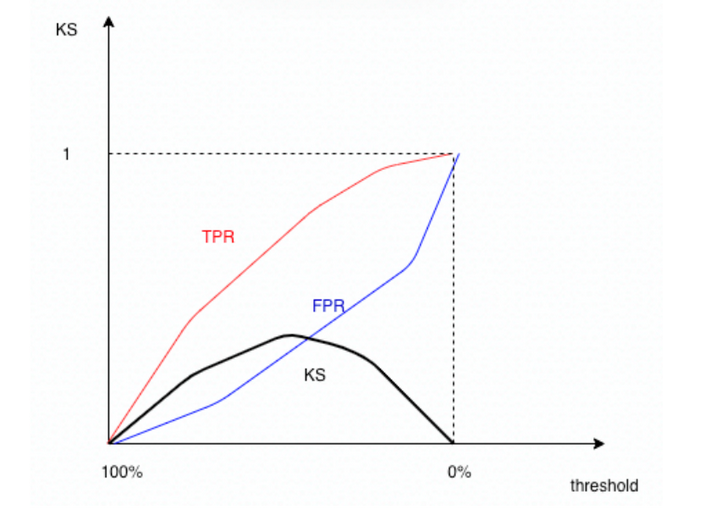
例2: 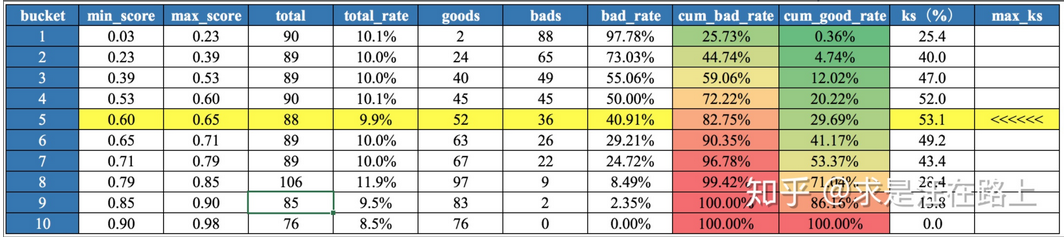
上表中,模型目标是预测逾期概率,1为bad,0为good,score为模型分数,和模型概率是相反的,即逾期概率越高,分数越低。第1组到第10组,逾期概率逐渐降低。bad_rate为该组正样本(坏样本)占该组样本数的比例,cum_bad_rate为累计正样本数占总正样本数的比例,cum_good_rate为累计负样本数占总负样本数的比例。
KS(Kolmogorov-Smirnov)值越大,表示模型区分正负样本的能力越强。KS值的取值范围是 [0,1]。
| ks值 | 含义 |
|---|---|
| >0.3 | 模型预测能力较好 |
| 0.2~0.3 | 模型可用 |
| 0~0.2 | 模型预测能力较差 |
通常来讲,KS>0.3即表示模型有较好的预测准确性。
另一种评价标准:
| ks值 | 含义 |
|---|---|
| >0.75 | 模型能力高但疑似有误,建议对计算、假设、数据等进行严格的检查 |
| 0.6~0.75 | 模型能力非常强 |
| 0.5~0.6 | 模型能力很强 |
| 0.4~0.5 | 模型能力良好 |
| 0.2~0.4 | 模型能力较好 |
| <0.2 | 模型能力较差 |
另:关于KS值是否越大越好,可参考以下链接:https://www.k2analytics.co.in/7-important-model-performance-measures
K-S曲线能直观地找出模型中差异最大的一个分段,比如评分模型就比较适合用KS值进行评估;但同时,KS值只能反映出哪个分段是区分度最大的,不能反映出所有分段的效果。所以,在实际应用中,模型评价一般需要将ROC曲线、K-S曲线、KS值、AUC指标结合起来使用。
6. Lift 提升度
参考
模型和策略效果衡量常用指标——LIFT提升度 - 简书
分类模型的性能评估——以 SAS Logistic 回归为例 (3): Lift 和 Gain | 统计之都 (cosx.org)
怎么做模型提升度的曲线? - 知乎
Understand Gain and Lift Charts (listendata.com)
Comparing Model Evaluation Techniques Part 2: Classification and Clustering - Data Science Central
11 Important Model Evaluation Techniques Everyone Should Know - Data Science Central
Evaluation Metrics Machine Learning (analyticsvidhya.com)
6.1 什么是 Lift
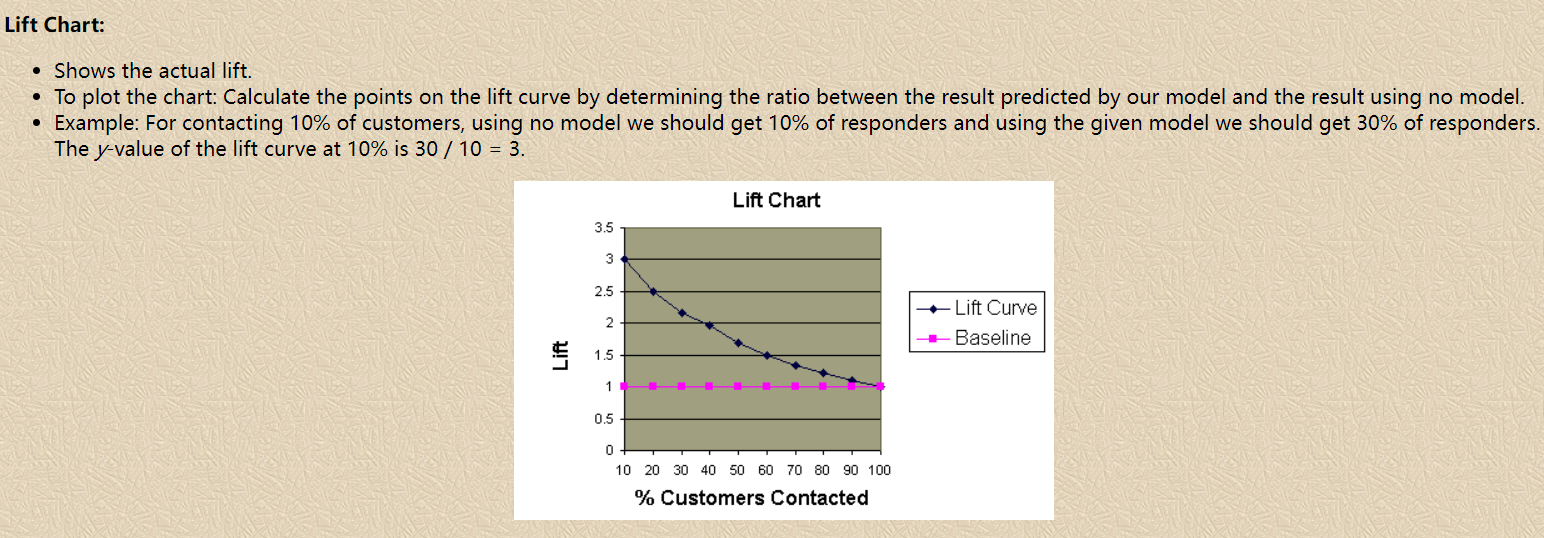
Lift提升度衡量的是,与不利用模型相比,模型的预测能力 “变好” 了多少(how much better one can expect to do with the predictive model comparing without a model. The "lift" is the ratio of results with and without the model; Better models have higher lifts.)。它衡量的是一个模型(或规则)对目标中“响应”的预测能力优于随机选择的倍数,以1为界线,大于1的Lift表示该模型或规则比随机选择捕捉了更多的“响应”,等于1的Lift表示该模型的表现独立于随机选择,小于1则表示该模型或规则比随机选择捕捉了更少的“响应”。维基百科中提升度被解释为“Target response divided by average response”。
显然,lift(提升指数)越大,模型的运行效果越好。如果这个模型的预测能力跟 baseline model 一样(lift 等于 1),这个模型就没有任何 “提升” 了(套一句金融市场的话,它的业绩没有跑过市场)。
以信用评分卡模型为例,LIFT提升度衡量的是评分模型对坏样本的预测能力相比随机选择的倍数,LIFT大于1说明模型表现优于随机选择。我们通常会将打分后的样本按分数从低到高(违约概率从高到低)排序,取10或20等分(有同分数对应多条观测的情况,所以各组观测数未必完全相等),并对组内观测数与坏样本数进行统计。用评分卡模型捕捉到的坏客户的占比,可由该组坏样本数除以总的坏样本数计算得出;而不使用此评分卡,以随机选择的方法覆盖到的坏客户占比,等价于该组观测数占总观测数的比例(分子分母同时乘以样本整体的坏账率)。对两者取累计值,取其比值,则得到提升度Lift,即该评分卡抓取坏客户的能力是随机选择的多少倍。
6.2 为什么要看 Lift
举个例子,一个贷款产品目标客群有10000个人,其中混合了500个坏客户。如果随机选择1000个人放款,可能会遇到50个坏客户。但是如果运用模型对坏客户加以预测,只选择模型分数最高的1000人放款,如果这1000个客户表现出来最终逾期的只有20户,说明模型在其中是起到作用的,此时的LIFT就是大于1的。如果表现出来逾期客户超过或等于50个,LIFT小于等于1,那么从效果上来看这个模型用了还不如不用。LIFT就是这样一个指标,可以衡量使用这个模型比随机选择对坏样本的预测能力提升了多少倍。
6.3 Lift 如何计算
通常计算LIFT的时候会把模型的最终得分按照从低到高(违约概率从高到低)排序并等频分为10组或20组(有同分数对应多条观测的情况,所以各组观测数未必完全相等),计算分数最低(违约概率最高)的一组对应的累计坏样本占比/累计总样本占比就等于LIFT值了。累计坏样本占比相当于是使用模型的情况下该组能够从所有的坏样本中挑出多少比例的坏样本(该组坏样本数/总坏样本数),而累计总样本占比等于随机抽样的情况下从所有坏样本抽取了多少比例的坏样本(该组人数/总人数)(即以随机选择的方法覆盖到的坏客户占比,等价于该组观测数占总观测数的比例(分子分母同时乘以样本整体的坏账率),也即完全随机的情况下,抽取10%的样本也会对应抽到坏样本中的10%,以6.2中的例子:
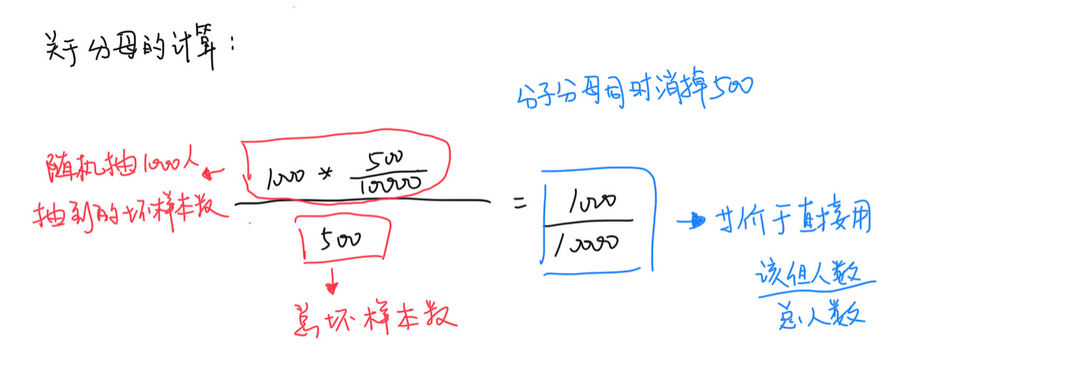
注:关于提升度与累计提升度:通常提升度指的就是累计提升度? 每组都可以算一个累计提升度:衡量到目前组的情况 最大值:到前多少组,两者比值达到最大(一定在第一组?)
个人理解:累计提升度可以理解为用百分之多少的人数覆盖了百分之多少的目标人群,如果用很少的人数覆盖了很大一部分的目标人群,则累计提升度会比较大。比较两个模型的效果时,以一个模型划分结果去等人数划分另一个模型,哪个模型覆盖的目标人群更多,则其提升度越大。
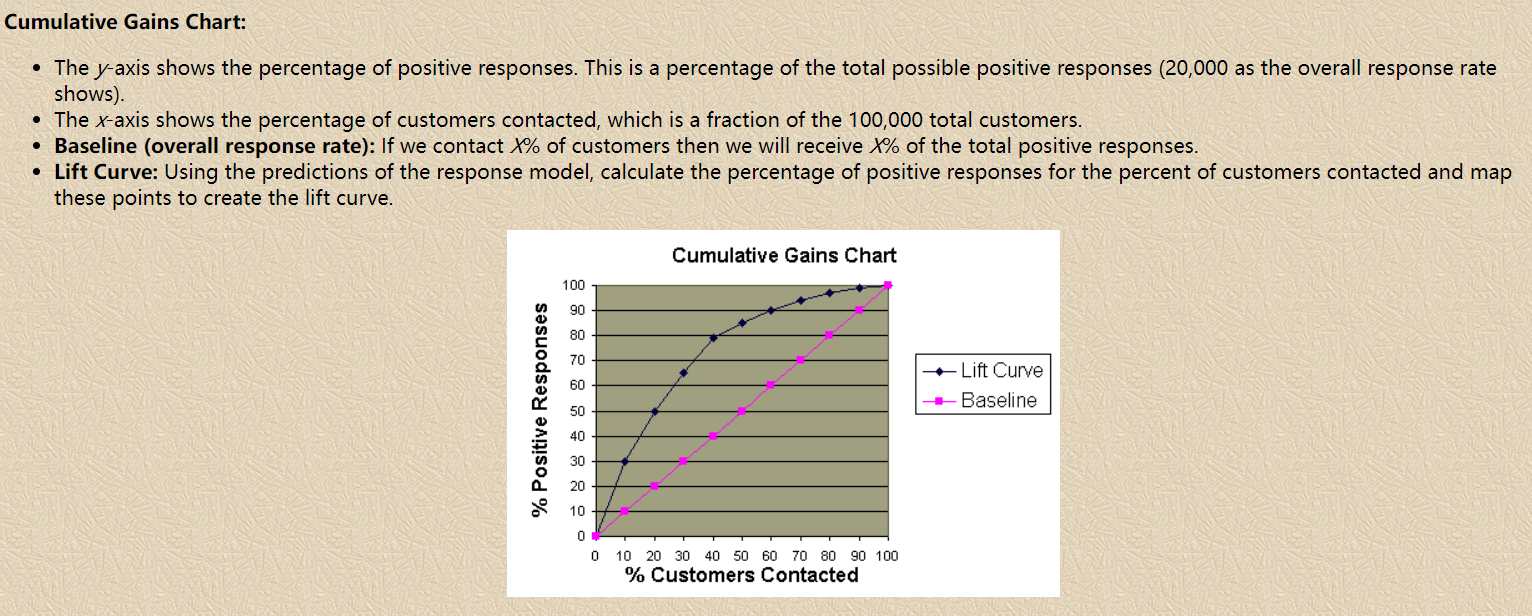
下图是一个提升表(Lift Table)的示例:
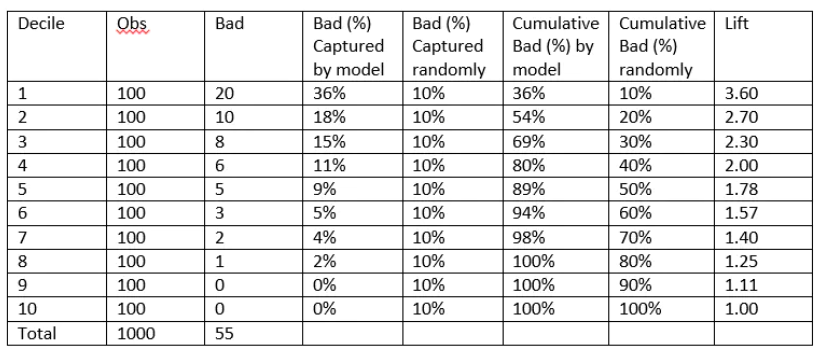
以分数段为横轴,以提升度为纵轴,可绘制出累计提升图,示例如下:
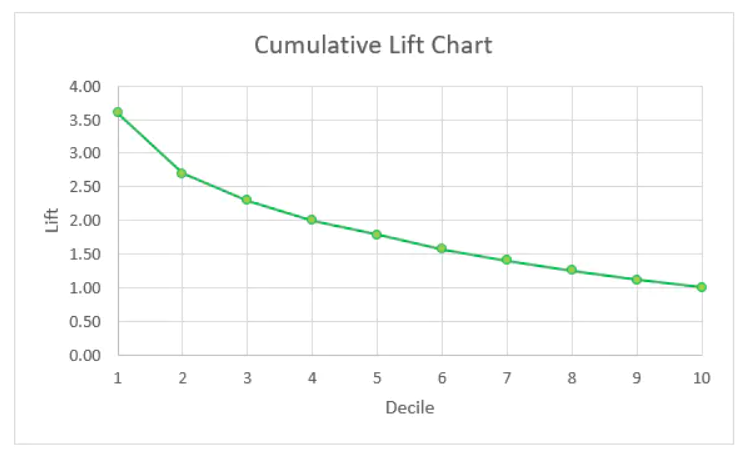
有了累计提升图,我们就能直观地去比较不同模型或策略给我们带来的区分能力增益程度。
对累计提升度的解释:
(假设分为10份) The Cum Lift of 4.03 for top two deciles, means that when selecting 20% of the records based on the model, one can expect 4.03 times the total number of targets (events) found by randomly selecting 20%-of-file without a model.
另一个例子:
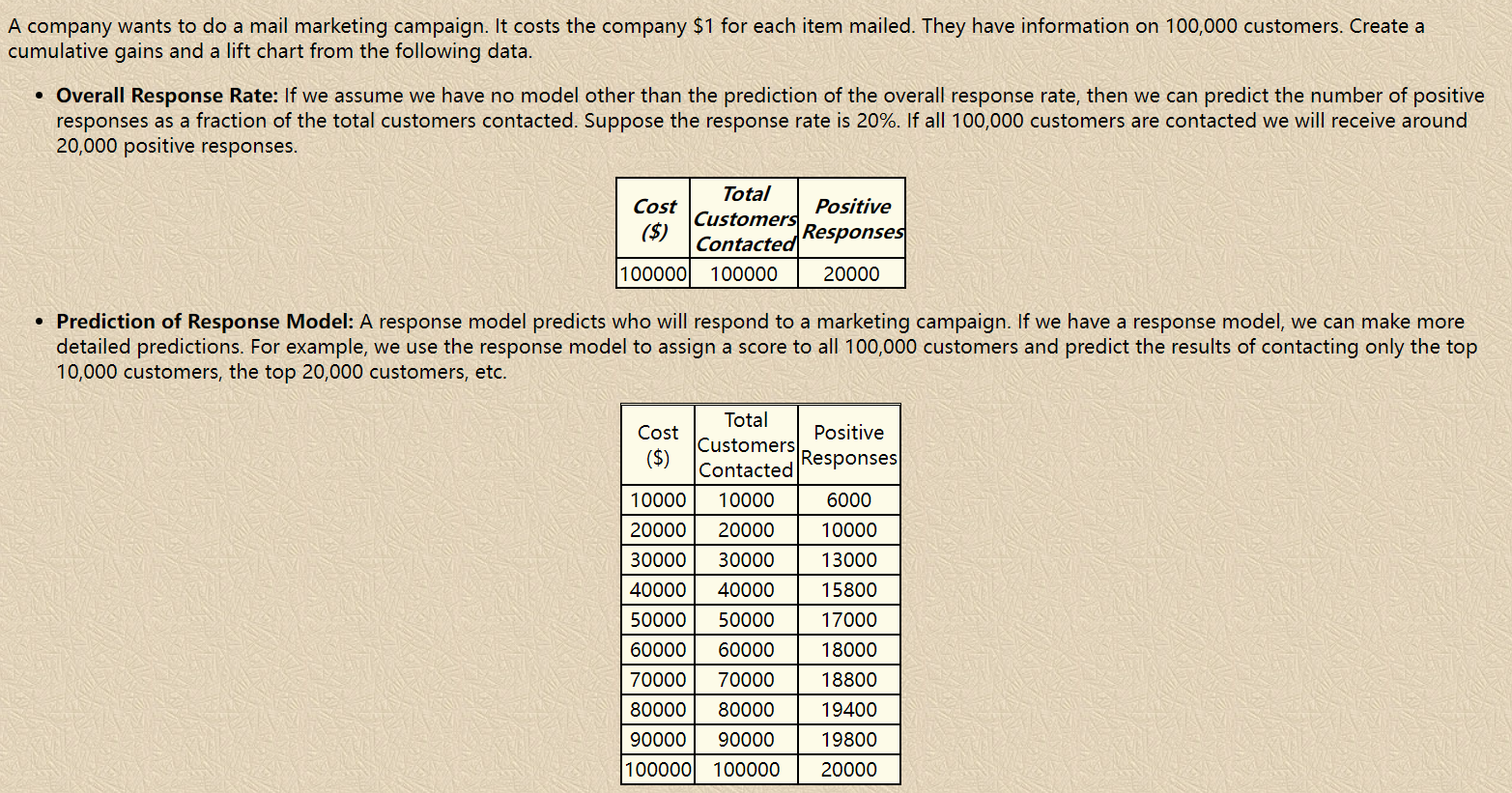
6.4 关于提升度与混淆矩阵
While the confusion matrix gives proportions between all negatives and positives, Gain and lift charts focus on the true positives. One of their most common uses is in marketing, to decide if a prospective client is worth calling.
Gain and lift charts work with a sample (a fraction of the population). In comparison, a confusion matrix uses the whole population to evaluate a model.
注:Gain 和提升度类似(其实就是Lift的分子部分)
7. 在 Python 中的实现
1 | from sklearn.metrics import precision_score, recall_score, f1_score |