熵、条件熵、互信息、相对熵
参考 《数学之美》
https://blog.csdn.net/tsyccnh/article/details/79163834
1. 信息量
一条信息的信息量与其不确定性有着直接的关系。比如说,我们要搞清楚一件非常非常不确定的事,或是我们一无所知的事情,就需要了解大量的信息。相反,如果已对某件事了解较多,则不需要太多的信息就能把它弄清楚。从这个角度来看,可以认为,信息量就等于不确定性的多少。(信息量和事件发生的概率有关,一个事件发生的概率越大,信息量就越小。)
假设我们听到了两件事, 事件A:巴西队进入了2026世界杯决赛圈 事件B:中国的进入了2026世界杯决赛圈
仅凭直觉来说,显而易见事件B的信息量比事件A的信息量要大。究其原因,是因为事件B发生的概率很小。当越不可能发生的事件发生了,我们获取到的信息量就越大,越可能发生的事件发生了,我们获取到的信息量就越小。
(信息量的定义) 假设X是一个离散型随机变量,则定义事件 \(X=x_0\)的信息量为: \[ I(x_0)=-\log p(x_0) \]
由于\(p(x_0)\)取值范围是[0,1],信息量绘制为图形如下:
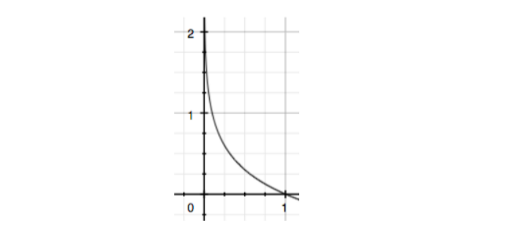
符合我们对信息量的直觉(事件发生的概率越大,信息量越小)
2. 信息熵
香农在他著名的论文”通信的数学原理“(A Mathematic Theory of Communication)中提出了”信息熵“的概念,解决了信息的度量问题,并且量化出信息的作用。
那么如何量化信息量的度量呢?来看一个例子。 2014年举行了世界杯足球赛,大家都很关心谁会是冠军。假如我错过了看世界杯,赛后我问一个知道比赛结果的观众“哪支球队是冠军"?他不愿意直接告诉我,而让我猜,并且我每猜一次,他要收一元钱才肯告诉我是否猜对了,那么我要掏多少钱才能知道谁是冠军呢?我可以把球队编上号,从1到32,然后提问:“冠军球队在1一16号中吗?”假如他告诉我猜对了,我会接着问:“冠军在1一8号中吗?”假如他告诉我猜错了,我自然知道冠军队在9一16号中。这样只需要五次,我就能知道哪支球队是冠军。 所以,谁是世界杯冠军这条消息的信息量只值5块钱。
当然,香农不是用钱,而是用“比特”(Bit)这个概念来度量信息量。一个比特是一位二进制数,在计算机中,一个字节(Byte)就是8比特。在上面的例子中,这条消息的信息量是5比特。(如果有朝一日有64支球队进入决赛阶段的比赛,那么“谁是世界杯冠军"的信息量就是6比特,因为要多猜一次。)读者可能已经发现,信息量的比特数和所有可能情况的对数函数log有关。(\(\log 32=5,\log 64=6\))
有些读者会发现实际上可能不需要猜五次就能猜出谁是冠军,因为像西班牙、巴西、德国、意大利这样的球队夺得冠车的可能性比日本、南非、韩国等球队大得多。因此,第一次猜测时不需要把32支球队等分成两个组,而可以把少数几支最可能的球队分成一组,把其他球队分成另一组。然后猜冠军球队是否在那几支热门队中。重复这样的过程,根据夺冠概率对余下候选球队分组,直至找到冠军队。这样,也许三次或四次就猜出结果。因此,当每支球队夺冠的可能性(概率)不等时,“谁是世界杯冠军”的信息量比5比特少。香农指出,它的准确信息量应该是 \[ H=-(p_1\log p_1+p_2\log p_2+...+p_{32}\log p_{32}) \]
香农把它称为“信息熵”(Entropy),一般用符号 \(H\) 表示,单位是比特。其中,\(p_1,p_2,...,p_{32}\)分别是这32支球队夺冠的概率。当32支球队夺冠概率相同时,对应的信息熵等于5比特。可以证明上面公式的值不可能大于5,即 \(0\leq H \leq \log n\)
信息熵用来表示所有信息量的期望。
(信息熵的定义) 对于任意一个随机变量 \(X\)(比如得冠军的球队),它的熵定义如下: \[ H(X)=-\sum _{x\in X}P(x)\log P(x) \]
举个例子,假设你拿出来你的电脑,会有三种可能性:
| 序号 | 事件 | 概率 | 信息量(这里使用的自然对数) |
|---|---|---|---|
| A | 电脑正常开机 | 0.7 | \(-\log0.7=0.36\) |
| B | 电脑无法开机 | 0.2 | \(-\log0.2=1.61\) |
| C | 电脑爆炸了 | 0.1 | \(-\log0.1=2.3\) |
信息熵: \[ \begin{align} H(X)&=-(p(A)*\log p(A) + p(B)*\log p(B) + p(C)*\log p(C))\\ &=0.7*0.36 + 0.2*1.61 + 0.1*2.3\\ &=0.804 \end{align} \] 对于0-1分布问题(只有两种可能),熵的计算方式可以简化为: \[ \begin{align} H(X)&=-\sum_{i=1}^n p(x_i)\log p(x_i)\\ &=-p(x)\log p(x)-(1-p(x))\log(1-p(x)) \end{align} \]
信息量度量的是一个具体事件发生所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。 (https://blog.csdn.net/wchwdog13/article/details/108783819)
变量的不确定性越大,熵也就越大,要把它搞清楚,所需信息量也就越大。
3. 条件熵
有些时候,在战争中1比特的信息能抵过干军万马。在第二次世界大战中.当纳粹德国兵临前苏联莫斯科城下时,斯大林在欧湖已经无兵可派,他们在西伯利亚的中苏边界有60万大军却不敢使用,因为苏联人不知道德国的轴心国盟友日本当时的军事策略是北上进攻前苏联,还是南下和美国开战。如果是南下,那么苏联人就可以放心大胆地从亚洲撤回60万大军增援莫斯科会战。事实上日本人选择了南下,其直接行动是后来的偷袭珍珠港,但是苏联人并不知骁。斯大林不能猜,因为猜错了后果是很严重的。这个“猜“既是指扔钢镚儿似的卜卦,也包括主观的臆断。最后传奇间谍佐尔格向莫斯科发去了信息量仅1比特却价值无限的情报(信息):“日本将南下",于是前苏联就把西伯利亚所有的军队调往了欧洲战场。后面的故事大家都知道了。
如果把这个故事背后的信息论原理抽象化、普遍化,可以总结如下:
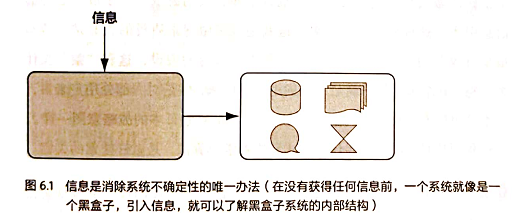
一个事物(比如上面讲到的日本内阁的战略决定)内部会存有随机性,也就是不确定性,假定为 \(U\),而从外部消除这个不确定性唯一的办法是引入信息 \(I\),而需要引入的信息量取决于这个不确定性的大小,即 \(I>U\) 才行。当 \(I<U\) 时,这些信息可以消除一部分不确定性,也就是说新的不确定性 \(U'=U-I\)
反之,如果没有信息,任何公式或数字的游戏都无法排除不确定性。这个朴素的结论非常重要,但是在研究工作中经常被一些半瓶子醋的专家忽视,希望做这方面工作的读者谨记。几所有的自然语言处理、信息与信号处理的应用都是一个消除不确定性的过程。
网页搜索本质上就是要从大量(几十亿个)网页中.找到和用户输入的搜索词最相关的几个网页。几十亿种可能性,当然是很大的不确定性 \(U\)。如果只剩下几个网页,就几平没有了不确定性了(此时 \(U'<<U\)),甚至是完全确定了(对于导航类搜索就是如此,第一条结果通常就是要找的网页)。因此,网页搜索本质上也是利用信息消除不确定性的过程。如果提供的信息不够多,比如搜索词是常用的关键词,诸如“中国”、“经济”之类的,那么会有好多相关的结果,用户可能还是无从选择,这时正确的做法是挖掘新的隐含信息,比如网页本身的质量信息。如果这些信息还是不够消除不确定性,不妨再问问用户。这就是相关搜索的理论基础。不正确的做法是在这个关键词上玩数字和公式的游戏,由于没有额外的信息引入,这种做法没有效果,这就是很多做搜索质量的人非常辛苦却很少有收获的原因。最糟糕的做法是引入人为的假设,这和“蒙“没什么差别。其结果是似平满足了个别用户的口味,但是对大部分用户来讲,搜索结果反而变得更糟。合理利用信息,而非玩弄什么公式和机器学习算法,是做好搜索的关键。
知道的信息越多,随机事件的不确定性就越小。
这些信息,可以是直针对我们要了解的随机事件,也可以是和我们关心的随机事件相关的其他(事件)的信息一一通过获取这些相关信息也能帮助我们了解所关注的对象。比如自然语言的统计模型,其中的一元模型就是通过某个词本身的概率分布来清除不确定因素;而二元及更高阶的语言模型则还使用了上下文的信息,那就能准确预测一个句子中当前的词汇了。在数学上可以严格地证明为什么这些”相关的“信息也能够消除不确定性,为此,需要引入一个条件熵(Conditional Entropy)的概念。
假定 \(X\) 和 \(Y\) 是两个随机变量, \(X\) 是我们需要了解的。假定我们现在知道了 \(X\) 的随机分布 \(P(X)\),那么也就知道了 \(X\) 的熵: \[ H(X)=-\sum_{x\in X}P(x)\log P(x) \] 那么它的不确定性就是这么大。现在假定我们还知道 \(Y\) 的一些情况,包括它和 \(X\) 一起出现的概率,在数学上称为联合概率分布,以及在 \(Y\) 取不同值的前提下 \(X\) 的概率分布,在数学上称为条件概率分布。
定义在 \(Y\) 的条件下的条件熵为: \[ \begin{align*} H(X|Y) &= -\sum_{x\in X,y\in Y}P(x,y)\log P(x,y)\\ &=\sum_{i=1}^n p_iH(X|Y=y_i) \end{align*} \] 这里,\(p_i=P(Y=y_i),\quad i=1,2,...,n.\)
可以证明, \(H(X)\geq H(X|Y)\),也即多了 \(Y\) 的信息之后,关于 \(X\) 的不确定性下降了。在统计语言模型中,如果把 \(Y\) 看成前一个字,那么在数学上就证明了二元模型的不确定性小于一元模型。同理,可以定义有两个条件的条件熵 \[ H(X|Y,Z)=-\sum_{x\in X,y\in Y,z\in Z}p(x,y,z)\log p(x,y,z) \] 还可以证明, \(H(X|Y)\geq H(X|Y,Z)\)。也就是说,三元模型应该比二元好。
上述的等号什么时候成立?等号成立说明增加了信息,不确定性却没有降低。如果我们获取的信息与要研究的事物毫无关系,等号就成立。
用一句话概括这一节:信息的作用在于消除不确定性,自然语言处理的大量问题就是寻找相关的信息。
4. 互信息
在上一节中提到,当获取的信息和要研究的事物“有关系”时,这些信息才能帮助我们消除不确定性。如何量化地度量“相关性”,香农在信息论中提出了一个“互信息”(Mutual Information)的概念作为两个随机事件“相关性”的量化度量。
假定有两个随机事件 \(X\) 和 \(Y\),它们的互信息定义如下: \[ I(X;Y)=\sum_{x\in X,y\in Y}P(x,y)\log\frac{P(x,y)}{P(x)P(y)} \] 这个互信息就是上节介绍的随机事件 \(X\) 的不确定性(熵 \(H(X)\))以及在知道随机事件 \(Y\) 的条件下的不确定性(条件熵 \(H(X|Y)\))之间的差异,即 \[ I(X;Y)=H(X)-H(X|Y) \]
即决策树中的信息增益
所谓两个事件相关的量化度量,就是在了解了其中一个 \(Y\) 的前提下,对消除另一个 \(X\) 的不确定性所提供的信息量。
互信息是一个取值在 \(0\) 到 \(min(H(X),H(Y))\) 之间的函数,当 \(X\) 和 \(Y\) 完全相关时,它的取值是 \(H(X)\),同时 \(H(X)=H(Y)\);当二者完全无关时,它的取值是0。
在自然语言处理中,两个随机事件,或者语言特征的互信息是很容易计算的。只要有足够的语料,就不难估计出互信息公式中的 \(P(X,Y),P(X)\) 和 \(P(Y)\) 三个概率,进而算出互信息。因此,互信息被广泛用于度量一些语言现象的相关性。
机器翻译中,最难的两个问题之一是词义的二义性(又称歧义性,Ambiguation)问题。比如 Bush 可以是美国总统布什的名字,也可以是灌木丛。那么如何正确地翻译这些词呢?
法一:用语法,分析语句,等等。-> 迄今为止没有一种语法能很好地解决这个问题,Bush不论翻译成人名还是灌木丛,都是名词,在语法上没有太大问题。
法二:加规则“总统做宾语时,主语得是一个人”。-> 要是这样,语法规则就多得数不清,而且还有许多例外。
真正简单却非常实用的方法是使用互信息: 首先从大量文本中找出和总统布什一起出现的互信息量最大的一些词,比如总统、美国、国会、华盛顿,等等。再用同样的方法找出和灌木丛一起出现的互信息量最大的词,比如土壤、植物、野生,等等。有了这两组词,再翻译 Bush 时,看看上下文中哪类相关的词多就可以了。
这种方法最初由吉尔(William Gale),丘奇(Kenneth Church)和雅让斯基(David Yarowsky)提出。
5. 相对熵 (KL散度)
“相对熵”,也叫KL散度 (\(Kullback-Leibler Divergence\)).
相对熵也用来衡量相关性,但和变量的互信息不同,它用来衡量两个取值为正数的函数的相似性,定义如下: \[ KL(f(x)||g(x))=\sum_{x\in X} f(x)\log\frac{f(x)}{g(x)} \] 1. 对于两个完全相同的函数,它们的相对熵等于零。 2. 相对熵越大,两个函数的差异越大;反之,相对熵越小,两个函数的差异越小。 3. 对于概率分布或概率密度函数,如果取值均大于零,相对熵可以度量两个随机分布的差异性。 4. \(KL(f(x)||g(x))>=0\)
总结:相对熵可以用来衡量两个概率分布之间的差异。(越小,两个分布越接近)
相对熵是不对称的,即 \[ KL(f(x)||g(x)) \neq KL(g(x)||f(x)) \] 这样使用起来有时不是很方便,为了让它对称,詹森和香农提出一种新的相对熵的计算方法,将上面的不等式两边取平均,即 \[ JS(f(x)||g(x))=\frac{1}{2}[KL(f(x)||g(x))+KL(g(x)||f(x))] \] 相对熵最早是用在信号处理上。如果两个随机信号,它们的相对熵越小,说明这两个信号越接近,否则信号的差异越大。后来研究信息处理的学者们也用它来衡量两段信息的相似程度,比如说如果一篇文章是照抄或者改写另一篇,那么这两篇文章中词频分布的相对熵就非常小,接近于零。在Google自动问答系统中,我们采用了上面的詹森-香农度量来衡量两个答案的相似性。
相对熵在自然语言处理中还有很多应用,比如用来衡量两个常用词(在语法和语义上)在不同文本中的概率分布,看它们是否同义。另外,利用相对熵,还可以得到信息检索中最重要的一个概念:词频率-逆向文档频率(TF-IDF)。
维基百科对相对熵的定义:
In the context of machine learning, \(D_{KL}(P||Q)\) is often called the information gain achieved if P is used instead of Q.
即如果用P来描述目标问题,而不是用Q来描述目标问题,得到的信息增量。在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布。如果我们的Q通过反复训练,能完美的描述样本,那么就不再需要额外的“信息增量”,Q等价于P。
6. 交叉熵 (cross entropy)
参考 https://blog.csdn.net/qq_41296039/article/details/129949230
对相对熵的定义变形可以得到: \[ \begin{align} KL(P||Q)&=\sum_{x\in X} p(x)\log\frac{p(x)}{q(x)}\\ &=\sum_{x\in X}p(x)\log p(x)-\sum_{x\in X}p(x)\log q(x)\\ &=-H(p(x))-\sum_{x\in X}p(x)\log q(x) \end{align} \] 等式的前一部分恰巧就是p的熵,等式的后一部分就是交叉熵: \[ H(P,Q) = - \sum_xp(x)\log q(x) \] 在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,即\(KL(y||\hat y)\),而由于KL散度中的前一部分\(-H(y)\)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中,直接使用交叉熵损失函数评估模型。
7. 机器学习中交叉熵的应用
在线性回归问题中,通常使用MSE(Mean Squared Error)作为损失函数: \[ loss = \frac{1}{2n}\sum_{i=1}^n(y_i-\hat y_i)^2 \] 而在分类问题中,交叉熵基本上是标配的方法。(最小化交叉熵损失函数)
7.1 交叉熵在单分类问题中的使用(单标签)
\[ loss = - \sum_{i=1}^m y_i\log (\hat y_i) \] 上式为一个样本的loss计算方法,m代表着m种类别
例如,有如下样本:

对应的标签和预测值:
| 猫 | 青蛙 | 老鼠 | |
|---|---|---|---|
| Label | 0 | 1 | 0 |
| Pred | 0.3 | 0.6 | 0.1 |
那么, \[ loss = -(0*\log0.3 + 1*\log0.6 + 0*\log0.1)=-\log 0.6 \] 对应一个batch的loss就是, \[ loss = -\frac{1}{n}\sum_{j=1}^n\sum_{i=1}^m y_{ji}\log(\hat y_{ji}) \] 其中n为当前batch的样本数,m为类别数。
7.2 交叉熵在多分类问题中的使用(多标签)
和单标签的分类问题不同,多标签的分类问题是n-hot
例如,有如下样本

对应的标签和预测值:
| 猫 | 青蛙 | 老鼠 | |
|---|---|---|---|
| Label | 0 | 1 | 1 |
| Pred | 0.1 | 0.7 | 0.8 |
值得注意的是,这里的预测值不是通过softmax计算的,而是采用的sigmoid(不同于单标签中的多种类问题),将每一个节点的输出归一化到[0,1]之间(所有的Pred之和不为1)。也即每一个Label是独立的,相互之间没有影响。所以交叉熵在这里是对每一个节点单独进行计算,每一个节点只有两种可能值,如前所述熵的计算可以进行简化。
同样的,交叉熵的计算也可以进行简化,即 \[ loss = -y\log\hat y - (1-y)\log(1-\hat y) \] 注意,上式只是针对一个节点的计算公式,这一点要和单分类loss区分开来。
例子中可以计算为: \[ \begin{align*} loss_猫 = -0*\log0.1-(1-0)*\log(1-0.1)=-\log0.9\\ loss_蛙 = -1*\log0.7-(1-1)*\log(1-0.7)=-\log0.7\\ loss_鼠 = -1*\log0.8 -(1-1)*\log(1-0.8)=-\log0.8 \end{align*} \] 单样本的loss即为 \(loss=loss_猫+loss_蛙+loss_鼠\).
每一个batch的loss就是: \[ loss = \sum_{j=1}^n\sum_{i=1}^m -y_{ji}\log\hat y_{ji}-(1-y_{ji})\log(1-\hat y_{ji}) \] 其中n为当前batch中的样本量,m为类别数。
softmax与cross-entropy的关系: 一句话概括,softmax把分类输出标准化成概率分布,cross-entropy刻画预测分类和真实结果之间的相似度。 多分类简化为二分类时,softmax公式就转变为sigmoid公式,损失函数由cross-entropy转化为binary cross-entropy的形式。
7.3 交叉熵的优缺点
在分类问题中,交叉熵作为loss function的优点包括:
优点: 交叉熵越小,说明模型预测的结果与真实结果之间的差异度量越小,从而可以更好地评估模型的性能。 与均方误差(Mean Square Error,MSE)相比,交叉熵能够更好地处理分类问题,因为它能够更好地量化分类问题中的不确定性。 交叉熵可以避免梯度消失的问题,因为当目标值与预测值相差很大时,交叉熵的梯度相对于均方误差的梯度更大。 交叉熵是实际应用中使用最广泛的分类损失函数之一,在训练神经网络模型时具有良好的收敛性和鲁棒性。
缺点: 计算交叉熵需要计算softmax函数,所以在处理大规模的分类问题时,计算代价较高。 交叉熵对噪声敏感,训练过程过程中可能会出现过拟合的现象。 交叉熵在处理稀疏标签数据时可能会出现问题,需要进行特殊处理。