Pandas中的常用函数
map、apply、applymap
在日常的数据处理中,经常会对一个DataFrame进行逐行、逐列和逐元素的操作,对应这些操作,Pandas中的map、apply和applymap可以解决绝大部分这样的数据处理需求。
生成100行示例数据:
1 | boolean=[True,False] |
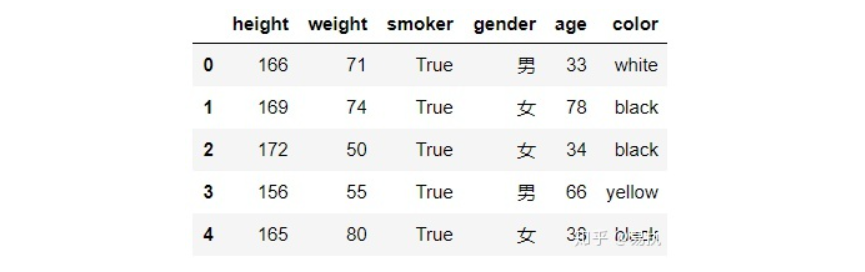
Series数据处理
1. map用法
若想把数据集中gender列的男替换为1,女替换为0,可使用
Series.map():
1 | # 法一:使用字典进行映射 |
不论是利用字典还是函数进行映射,map方法都是把对应的数据逐个当作参数传入到字典或函数中,得到映射后的值。
注:若该列中存在map字典中不存在的值,例如,gender 中还存在“未知”,则“未知”会被映射为Nan,此时可选择使用函数进行映射,定义一个else,同时使用函数会更加灵活,例如当满足多个条件时,都映射到某个值
2. apply
apply 方法的作用原理和 map
方法类似,区别在于 apply 能够传入功能更为复杂的函数
假设在数据统计的过程中,年龄age列有较大误差,需要对其进行调整(加上或减去一个值),由于这个加上或减去的值未知,故在定义函数时,需要加多一个参数
bias,此时用 map
方法是操作不了的(传入 map
的函数只能接收一个参数),apply
方法则可以解决这个问题。
1 | def apply_age(x,bias): |
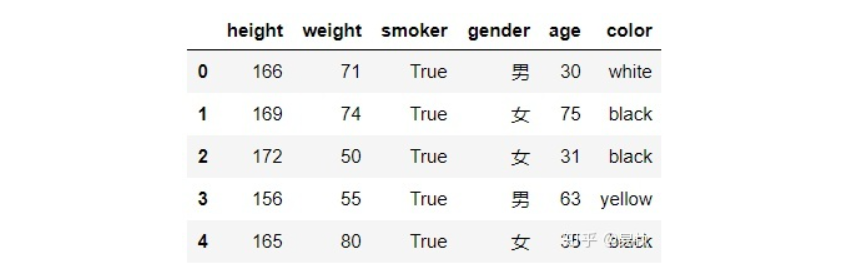
可以看到age列都减了3,当然,这里只是简单举了个例子,当需要进行复杂处理时,更能体现apply的作用。
总而言之,对于Series而言,map可以解决绝大多数的数据处理需求,但如果需要使用较为复杂的函数,则需要用到apply方法。
DataFrame数据处理
1. apply
对DataFrame而言,apply是非常重要的数据处理方法,它可以接收各种各样的函数(Python内置的或自定义的),处理方式很灵活。
在进行具体介绍之前,首先需要了解一下DataFrame中axis的概念(详见数据框操作)
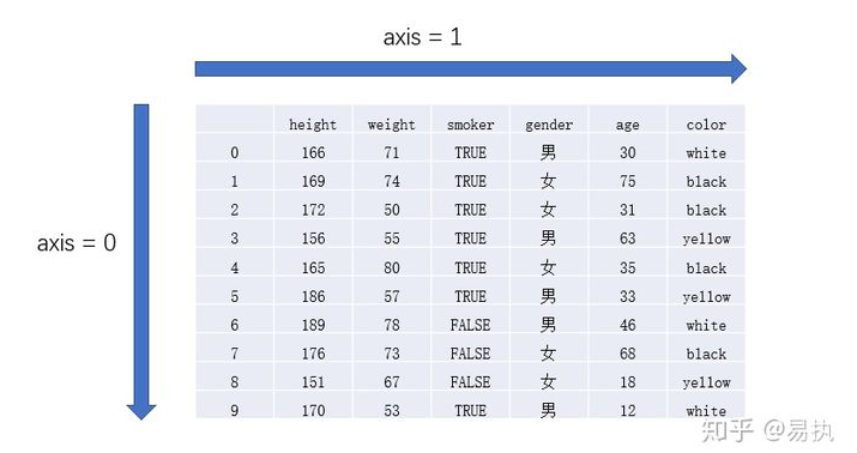
简言之,若想沿着axis=0的方向新增数据,则选择axis=0;若想沿着axis=1的方向新增数据,则选择axis=1。
假设现在需要对data中的数值列分别进行取对数和求和的操作,这时可以用
apply
进行相应的操作,因为是对列进行操作,所以需要指定axis=0:
1 | # 沿着0轴求和 |

当沿着轴0(axis=0)进行操作时,会将各列(columns)默认以Series的形式作为参数,传入到你指定的操作函数中,操作后合并并返回相应的结果。
那如果在实际使用中需要按行进行操作(axis=1), 例如:
在数据集中,有身高和体重的数据,所以根据这个,我们可以计算每个人的BMI指数(体检时常用的指标,衡量人体肥胖程度和是否健康的重要标准),计算公式是:体重指数BMI=体重/身高的平方(国际单位kg/㎡),因为需要对每个样本进行操作,这里使用axis=1的apply进行操作,代码如下:
1 | def BMI(series): |
当apply设置了axis=1对行进行操作时,会默认将每一行数据以Series的形式(Series的索引为列名)传入指定函数,返回相应的结果。
总结一下对DataFrame的apply操作:
- 当
axis=0时,对每列columns执行指定函数;当axis=1时,对每行row执行指定函数。- 无论
axis=0还是axis=1,其传入指定函数的默认形式均为Series,可以通过设置raw=True传入numpy数组。- 对每个Series执行结果后,会将结果整合在一起返回(若想有返回值,定义函数时需要
return相应的值)- 当然,
DataFrame的apply和Series的apply一样,也能接收更复杂的函数,如传入参数等,实现原理是一样的,具体用法详见官方文档。
2. applymap
applymap的用法比较简单,会对 DataFrame
中的每个单元格执行指定函数的操作
新生成一个 DataFrame:
1 | df = pd.DataFrame( |
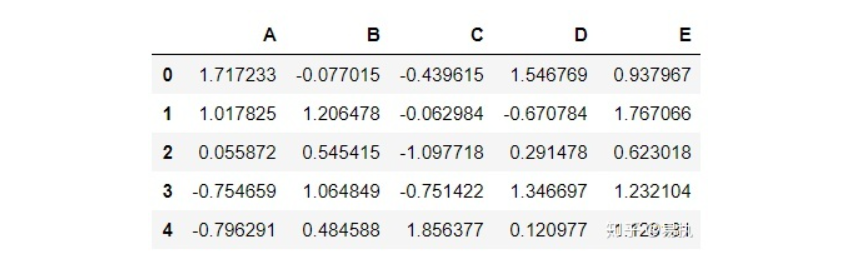
现在想将DataFrame中所有的值保留两位小数显示,使用applymap可以很快达到你想要的目的,代码和图解如下:
1 | df.applymap(lambda x:"%.2f" % x) |
applymap 将 DataFrame 中的每个数据作为 x
传入匿名函数
groupby
pandas.DataFrame.groupby — pandas 1.3.0 documentation (pydata.org)
Pandas教程 | 超好用的Groupby用法详解 - 知乎
将数据根据某个(多个)字段划分为不同的群体(group)进行分析
例:
模拟生成10个样本数据:
1 | company=["A","B","C"] |
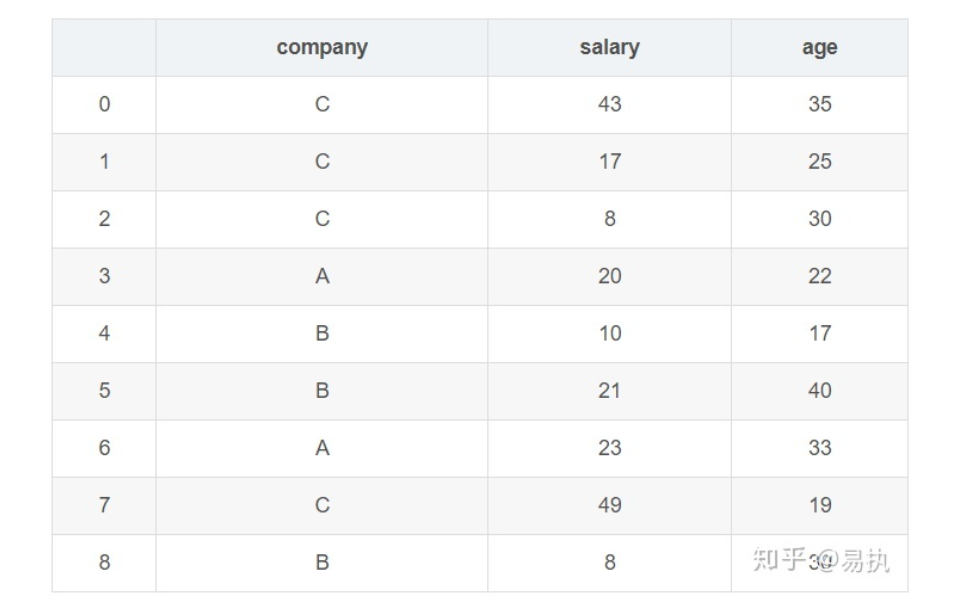
1 | group = data.groupby("company") |
groupby的过程就是将原有的DataFrame按照groupby的字段(这里是company),划分为若干个子DataFrame,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。
agg聚合操作
Pandas中常见的聚合操作:
min, max, sum, mean, median, std, var, count
👇 根据公司进行分组,对其余每一列求平均
1 | > data.groupby("company").agg('mean') |
转化成标准的dataframe格式,末尾加上.reset_index()
1 | >data.groupby("company").agg('mean').reset_index() |
👇 根据公司进行分组,对 salary 列求平均
1 | > data.groupby("company")["salary"].agg('mean') |
1 | 也可以直接写作: |
👇 根据公司进行分组,对 salary 列求中位数,对 age 列求平均
1 | > data.groupby('company').agg({'salary':'median','age':'mean'}) |
👇 根据公司进行分组,对所有数值型的列进行求平均
1 | >data.groupby('company').mean(numeric_only=True) |
如果要根据多列进行groupby,写作
data.groupby(['colnameA','colnameB'])
另一个例子,根据每个季度每个用户的当季度贡献收入,以及给用户打上的标签,计算标签下的用户数与贡献金额,以及占比:
1 | 原始dataframe包含的列名:注册id, 季度, 收入, 标签 |
注意:如果要对同一列,计算均值与中位数:
1 | 不能使用: |
transform操作
若在求得不同公司员工的平均薪水后,想在原数据集中新增一列avg_salary,该怎么做呢?
不用transform的话,实现代码如下:
1 | > avg_salary_dict = data.groupby('company')['salary'].mean().to_dict() |
如果使用transform的话,仅需要一行代码:
1 | > data['avg_salary'] = data.groupby('company')['salary'].transform('mean') |
apply
apply 相比 agg 和 transform
而言更加灵活,能够传入任意自定义的函数,实现复杂的数据操作
假设现在需要获取各个公司年龄最大的员工的数据,可以用以下代码实现:
1 | > def get_oldest_staff(x): |
最后,关于
apply的使用,这里有个小建议,虽然说apply拥有更大的灵活性,但apply的运行效率会比agg和transform更慢。所以,groupby之后能用agg和transform解决的问题还是优先使用这两个方法,实在解决不了了才考虑使用apply进行操作。
crosstab
crosstab 交叉表,用于统计分组频率的特殊透视表(列联表)
官方文档:pandas.crosstab — pandas 1.3.0 documentation (pydata.org)
例:
1 | import pandas as pd |
语法:

assign
官方文档:pandas.DataFrame.assign — pandas 1.3.0 documentation (pydata.org)
作用:Assign new columns to a DataFrame.
例:
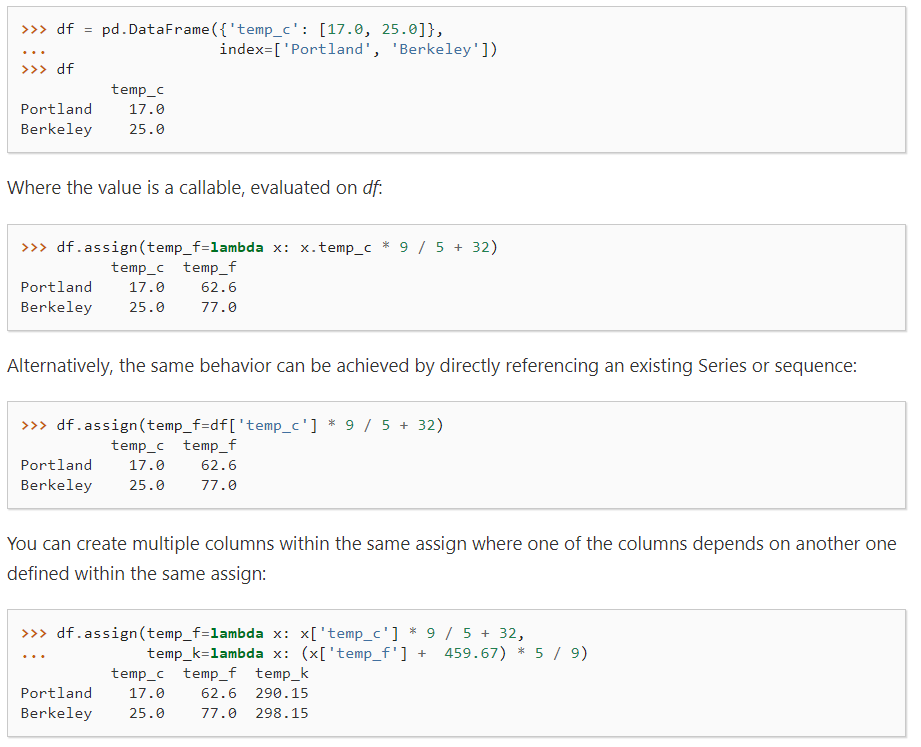
↑也可以写为:
1 | df.assign(temp_f=lambda x:x['temp_c']*9/5+32).assign(temp_k=lambda x: (x['temp_f']+459.67)*5/9) |
例:利用crosstab与assign进行woe和iv的计算:
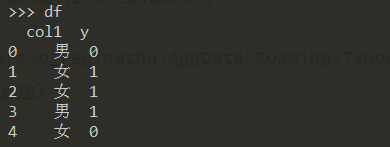
构造数据集:
1 | df = pd.DataFrame({"col1":["男","女","女","男","女"], "y":[0,1,1,1,0]}) |
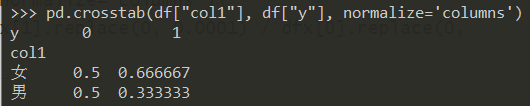
利用 crosstab 得到频率表:
1 | pd.crosstab(df["col1"], df["y"], normalize='columns') |
在频率表的基础上,加上woe列:
1 | pd.crosstab(df["col1"], df["y"], normalize='columns').assign(woe=lambda dfx: np.log(dfx[1].replace(0, 0.0001) / dfx[0].replace(0, 0.0001))) |
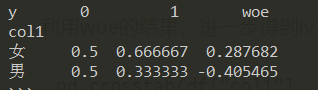
利用woe的结果,进一步得到iv:
1 | pd.crosstab(df["col1"], df["y"], normalize='columns').assign(woe=lambda dfx: np.log(dfx[1].replace(0, 0.0001) / dfx[0].replace(0, 0.0001))).assign(iv=lambda dfx: np.sum(dfx['woe'] * (dfx[1] - dfx[0]))) |
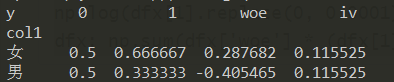
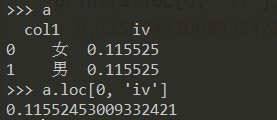
↑因为iv值是是对于一个变量而言(关于iv和woe的介绍详见我的博客 WOE编码与IV值),所以上面的两个iv值是一样的,那么如何从上述结果中提取出iv值:
1 | df_woe_iv = pd.crosstab(df["col1"], df["y"], normalize='columns').assign(woe=lambda dfx: np.log(dfx[1].replace(0, 0.0001) / dfx[0].replace(0, 0.0001))).assign(iv=lambda dfx: np.sum(dfx['woe'] * (dfx[1] - dfx[0]))) |
pivot
原数据:
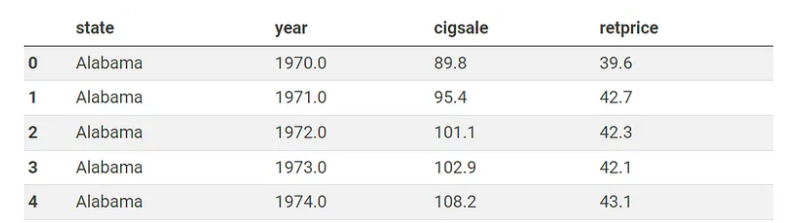
想要把数据转换成,每一行是一个 state,每一列是每一年的数据:(把数据打横)
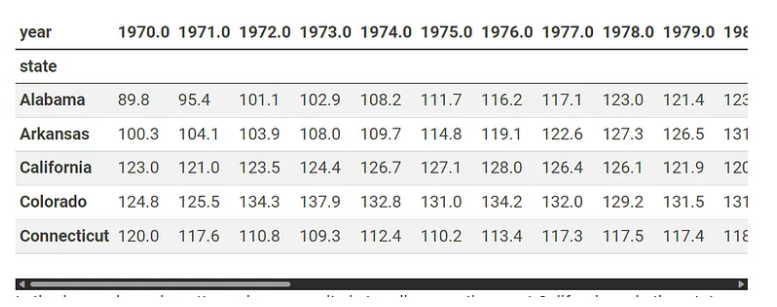
语法如下:
1 | df = df.pivot(index='state',columns='year', values='cigsale') |