存在重复元素2

方法:哈希表
维护一个哈希表,里面始终最多包含 k 个元素,当出现重复值时则说明在 k 距离内存在重复元素。 每次遍历一个元素则将其加入哈希表中,如果哈希表的大小大于 k,则移除最前面的数字。
复杂度
时间复杂度:O(n)。我们会做 n 次 搜索,删除,插入操作,每次操作都耗费常数时间。
空间复杂度:O(min(n,k))。开辟的额外空间取决于散列表中存储的元素的个数,也就是滑动窗口的大小。
代码
1 | class Solution { |

维护一个哈希表,里面始终最多包含 k 个元素,当出现重复值时则说明在 k 距离内存在重复元素。 每次遍历一个元素则将其加入哈希表中,如果哈希表的大小大于 k,则移除最前面的数字。
时间复杂度:O(n)。我们会做 n 次 搜索,删除,插入操作,每次操作都耗费常数时间。
空间复杂度:O(min(n,k))。开辟的额外空间取决于散列表中存储的元素的个数,也就是滑动窗口的大小。
1 | class Solution { |

时间复杂度 : O(n)。search() 和 insert() 各自使用 n 次,每个操作耗费常数时间。
空间复杂度 : O(n)。哈希表占用的空间与元素数量是线性关系。
1 | class Solution { |

另一种思路:利用Python中的set(),判断所得结果长度与原数组长度的关系
1 | class Solution: |

如果存在重复元素,排序后它们应该相邻。
时间复杂度 : O(nlogn)。
空间复杂度 : O(1)。这取决于具体的排序算法实现,通常而言,使用
堆排序 的话,是 O(1)。
1 | class Solution { |

注:对于一些特定的 n不太大的测试样例,方法一的运行速度可能会比方法二更慢。这是因为哈希表在维护其属性时有一些开销。要注意,程序的实际运行表现和 Big-O 符号表示可能有所不同。Big-O 只是告诉我们在 充分大的输入下,算法的相对快慢。因此,在 n不够大的情况下, O(n)的算法也可以比 O(nlogn)的更慢。
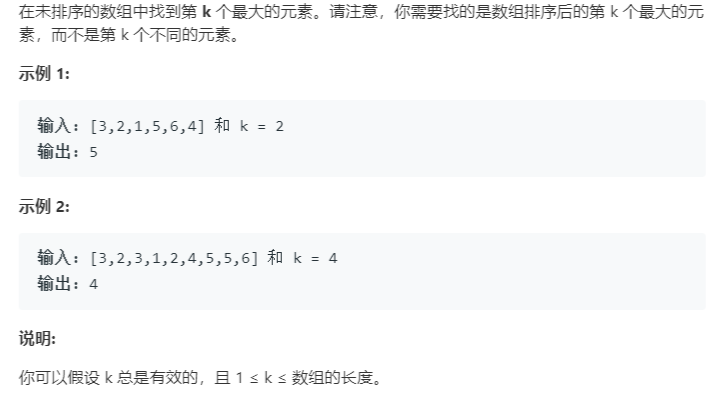
先对数组进行排序,再返回倒数第 k 个元素。
时间复杂度:O(nlogn)
空间复杂度:O(1)
这个时间复杂度并不令人满意
1 | class Solution: |

建一个只能存K个数字的小顶堆,超过K时候,每加进来一个,堆顶就要弹出一个。数组遍历完,最终堆顶的元素就是第K大的(堆里其他元素都比它还要大)。
时间复杂度:O(nlogk). 向大小为 k 的堆中添加元素的时间复杂度为O(logk),我们将重复该操作 n 次,故总时间复杂度为O(nlogk)。
空间复杂度:O(k).
1 | class Solution { |

详见这里.
时间复杂度 : 平均情况O(N),最坏情况 O(N^2)。
空间复杂度 : O(1)。

1 | /** |
注:添加虚拟头节点解决头节点是要被删除的情况

“快指针”每次走两步,“慢指针”每次走一步,当二者相等时,即为一个循环周期。此时,判断是不是因为1引起的循环,是的话就是快乐数,否则不是快乐数。
1 | class Solution { |

1 | class Solution: |


在Python中,先用set()找出所有出现的元素,再使用count()判断出现次数大于n/3的。
1 | class Solution: |

然而时间复杂度不为O(n)。
超过n/3的数最多只能有两个。先选出两个候选人A,B(都令为nums[0])。 遍历数组:
若当前元素等于A,则A的票数++;
若当前元素等于B,则B的票数++;
若当前元素与A,B都不相等,那么检查此时A或B的票数是否减为0:
若为0,则当前元素成为新的候选人;
若A、B票数均不为0,则A、B两个候选人的票数均减一;
遍历结束后选出了两个候选人,但是这两个候选人是否满足>n//3,还需要再遍历一遍数组,找出两个候选人的具体票数。
复杂度
时间复杂度:O(n)
空间复杂度:O(1)
代码
1 | class Solution: |


注意:这样的元素只存在一个,因为出现次数大于n/2,若存在两个,则数组长度会超过n。
在Python中,先用set()找出所有出现的元素,再使用count()判断出现次数大于n/2的。
1 | class Solution: |

先排序,再返回位于n/2位置的元素。
时间复杂度:O(nlogn)。用 Python 和 Java 将数组排序开销都为 O(nlogn),它占据了运行的主要时间。
空间复杂度:O(1)或O(n)。就地排序或使用线性空间将 nums
数组拷贝,然后再排序。
1 | class Solution: |

从第一个数开始count=1,遇到相同的就加1,遇到不同的就减1,减到0就重新换个数开始计数,最后总能找到最多的那个。
时间复杂度:O(n)。严格执行了 n 次循环。
空间复杂度:O(1)。
1 | class Solution: |

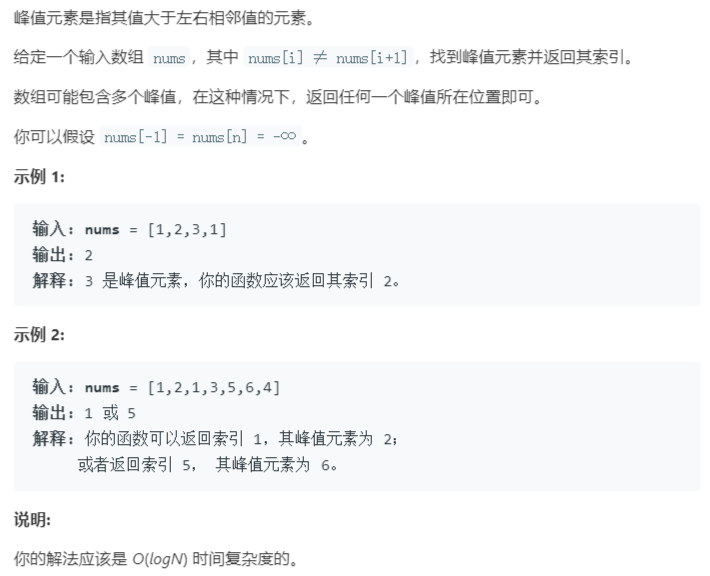
利用连续的两个元素 nums[j] 和 nums[j+1]
不会相等这一事实,我们可以从头开始遍历
nums数组,当遇到nums[i] > nums[i+1]
,即可判断 nums[i]为峰值。
注意:不需要判断nums[i]>nums[i-1]。这是由于“遍历会到达第i个元素”本身就说明上一个元素(第i-
1个)不满足 nums[i] > nums[i+1]这一条件,也就说明
nums[i-1] < nums[i]。
时间复杂度 : O(n)。 只进行一次遍历。 空间复杂度 : O(1)。 只使用了常数空间。
1 | class Solution { |
时间复杂度 : O(logn)。 每一步都将搜索空间减半。 空间复杂度 : O(1)。 只使用了常数空间。
1 | class Solution { |


作者:LeetCode 链接:https://leetcode-cn.com/problems/maximum-length-of-repeated-subarray/solution/zui-chang-zhong-fu-zi-shu-zu-by-leetcode/ 来源:力扣(LeetCode)
设 dp[i][j]为 A[i:] 和 B[j:]
的最长公共前缀,那么答案为所有 dp[i][j] 中的最大值
max(dp[i][j])。若 A[i] == B[j],状态转移方程为
dp[i][j] = dp[i + 1][j + 1] + 1,否则为
dp[i][j] = 0。
复杂度分析
时间复杂度:O(M*N),其中 M和 N是数组 A 和 B 的长度。
空间复杂度:O(M*N),即为数组 dp 使用的空间。
代码
1 | class Solution { |

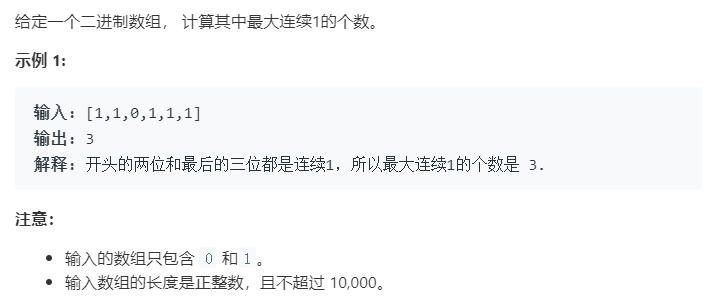
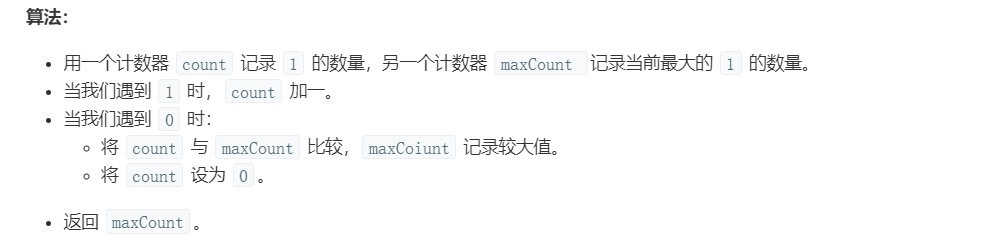
复杂度分析
count 和
maxCount。1 | class Solution(object): |