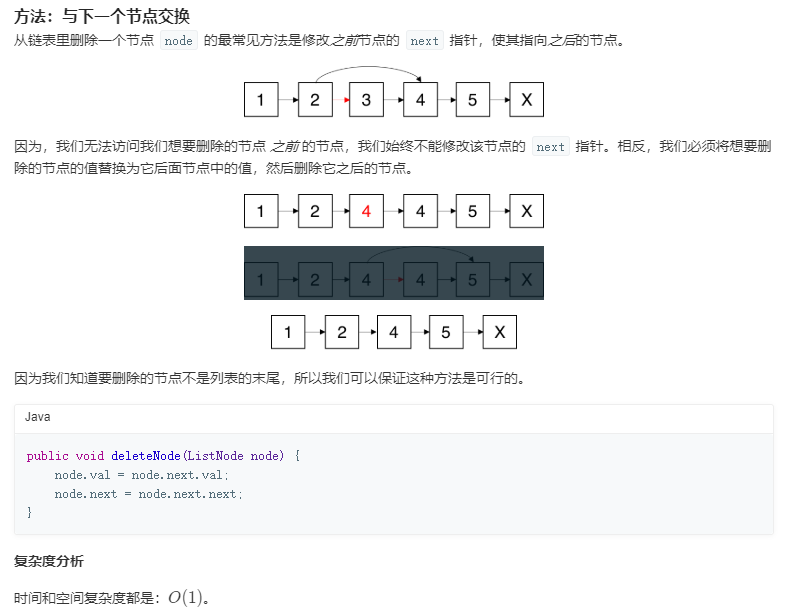
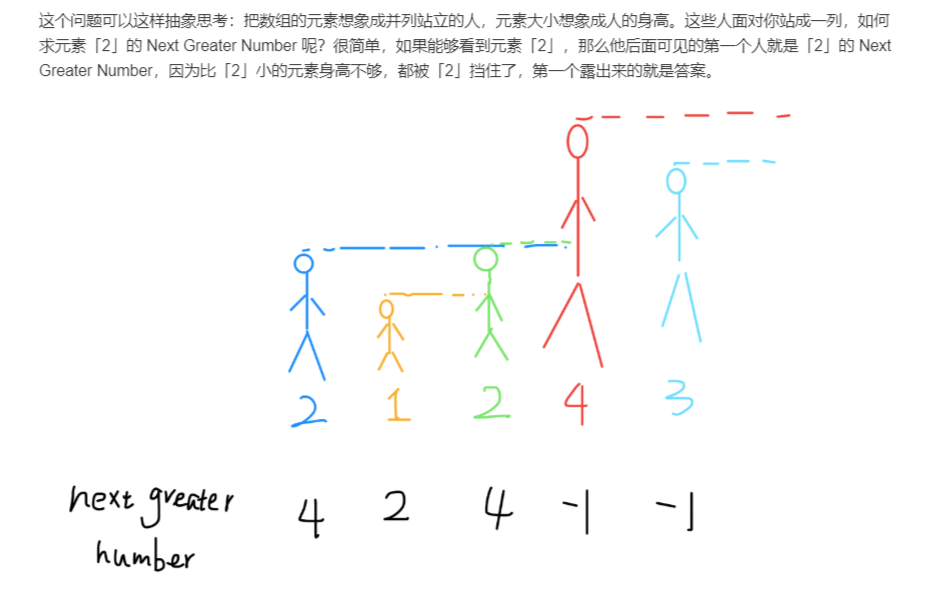
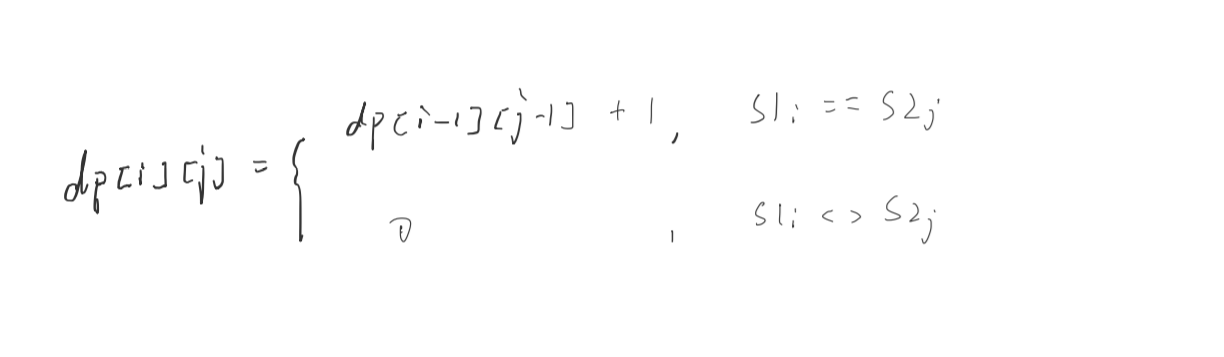下一个更大元素1


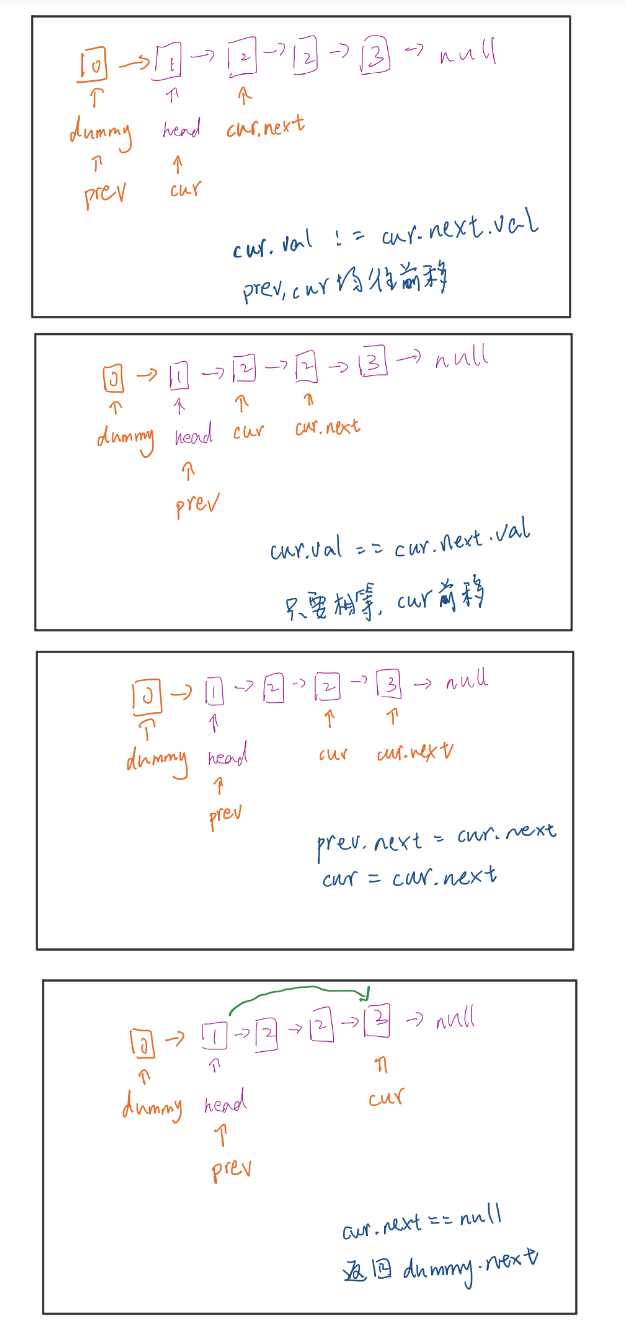
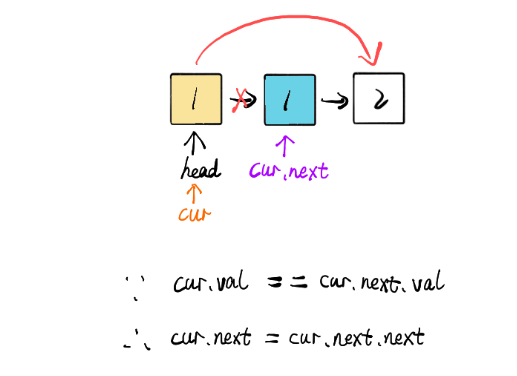
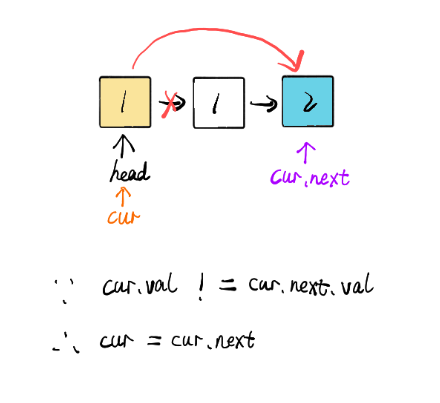
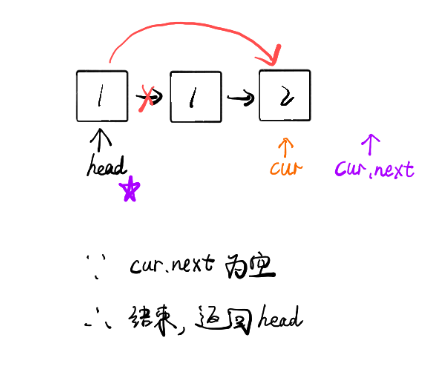
图解
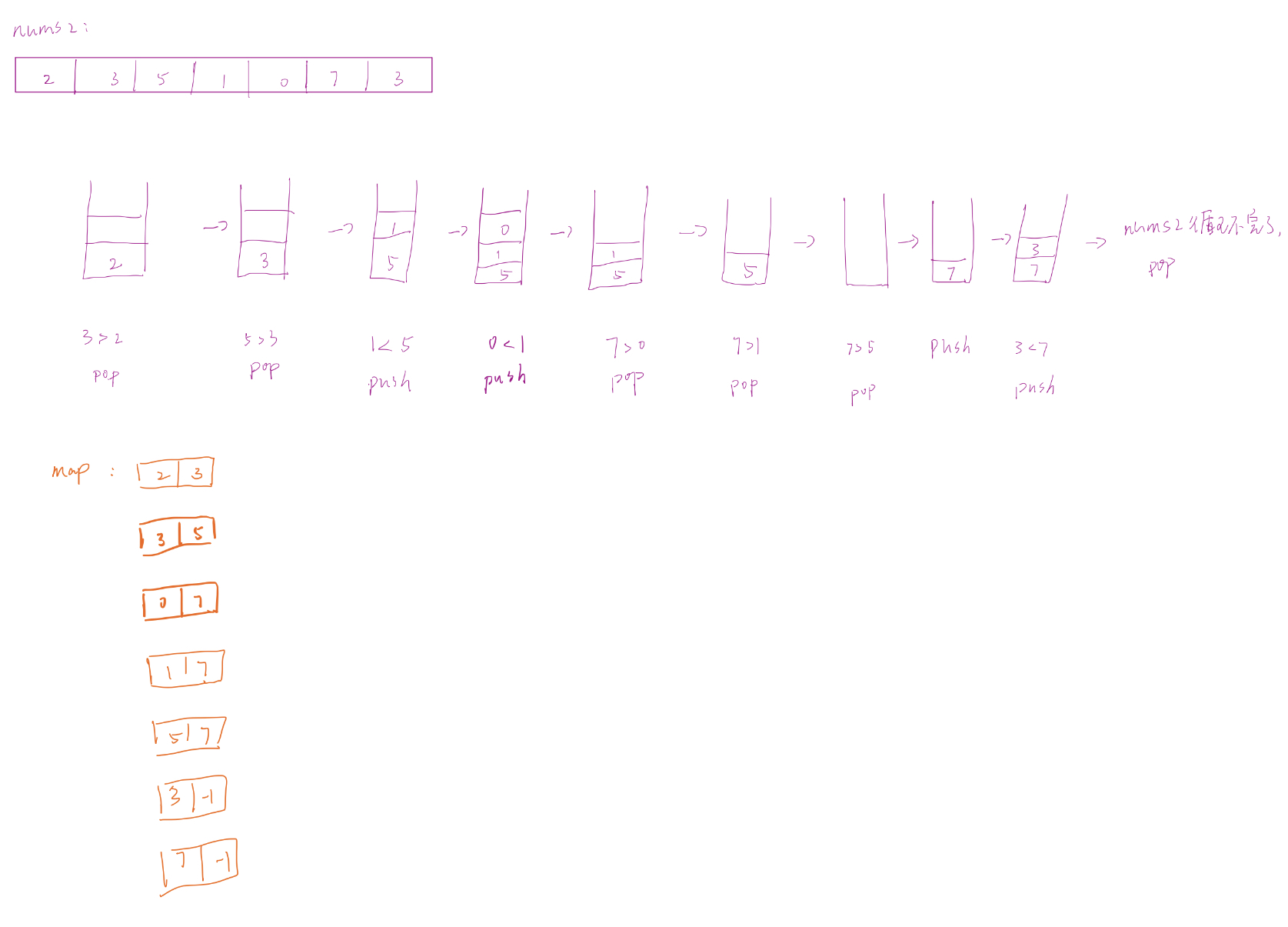
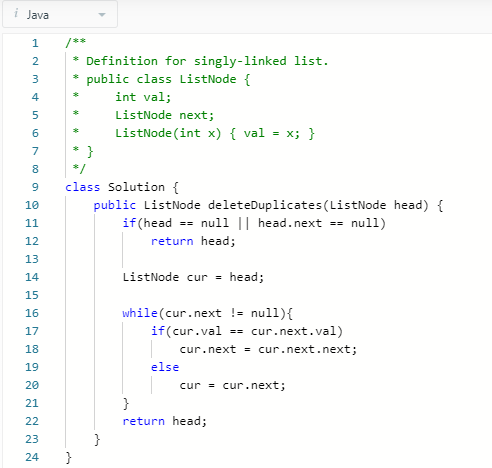
另一种写法(从后往前)
转自:
作者:labuladong 链接:https://leetcode-cn.com/problems/next-greater-element-i/solution/dan-diao-zhan-jie-jue-next-greater-number-yi-lei-w/ 来源:力扣(LeetCode)
模板:
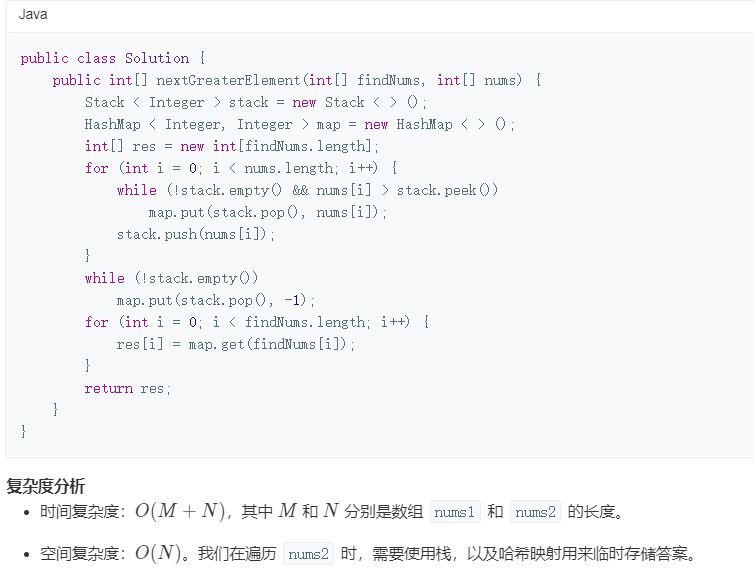
1 | vector<int> nextGreaterElement(vector<int>& nums) { |
for 循环要从后往前扫描元素,因为我们借助的是栈的结构,倒着入栈,其实是正着出栈。while 循环是把两个“高个”元素之间的元素排除,因为他们的存在没有意义,前面挡着个“更高”的元素,所以他们不可能被作为后续进来的元素的 Next Great Number 了。
这个算法的时间复杂度不是那么直观,如果你看到 for 循环嵌套 while 循环,可能认为这个算法的复杂度也是 O(n^2),但是实际上这个算法的复杂度只有 O(n)。
分析它的时间复杂度,要从整体来看:总共有 n 个元素,每个元素都被 push 入栈了一次,而最多会被 pop 一次,没有任何冗余操作。所以总的计算规模是和元素规模 n 成正比的,也就是 O(n) 的复杂度。
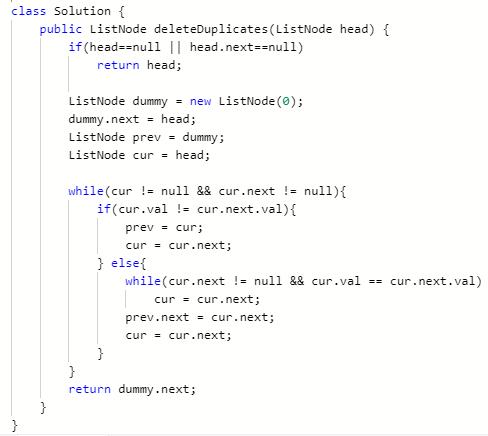
本题代码
1 | class Solution { |