Python working directory
- 更改当前路径
1 | import os |
- 获取当前路径
1 | import os |
1 | import os |
1 | import os |
1 | dat = pd.DataFrame({'id':[1,2,3], 'string': ['a', 'b','c']}) |
1 | dat = pd.DataFrame([n_clusters_start, score], columns = ["分类数", "得分"]) |
例:
1 | exclamationCount = lambda text: sum([1 for x in text if x == '!']) |
1 | eachLetterCount = lambda text,letter: sum([1 for x in text.lower() if x == letter]) |
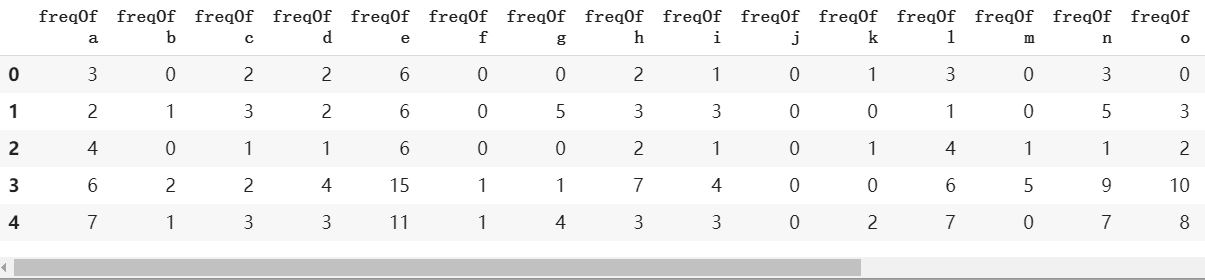
1 | import pandas as pd |
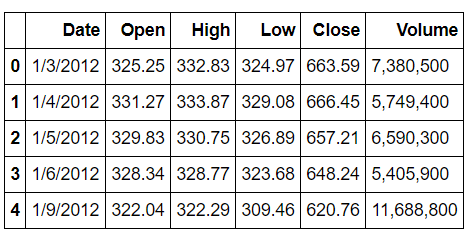
若文件中无列表头,需设定header = None,否则第一行会被识别为标题(如下图)
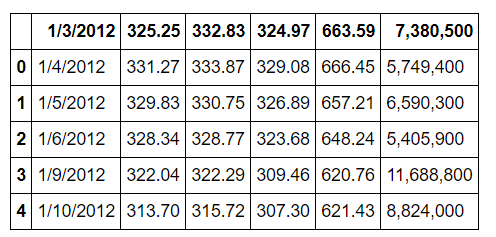
1 | import pandas as pd |
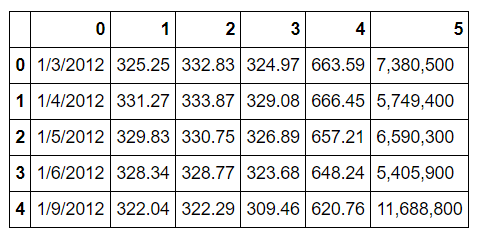
或者用names指定需要的列表头
1 | import pandas as pd |
另:关于读取csv文件,报错:
参考 https://www.cnblogs.com/huangchenggener/p/10983812.html
1 | 'utf-8' codec can't decode byte 0xd4 in position 0: invalid continuation byte |
法一:csv文件的保存格式改为 "CSV UTF-8 (逗号分割) (*.csv)"
法二:pd.read_csv()中加上编码方式:
1 | pd.read_csv("xxx.csv", encoding='gbk') |
(本文参考Markdown Tutorial)
1 | _unknown_或*unkown* |
效果如下:unknown
1 | __unknown__或**unknown** |
效果如下:unknown
1 | **_of course_** |
效果如下:of course
在前面加#号, 一共有六级标题。一级标题为在前面加一个#号(#
一级标题),二级标题为在前面加两个#号(## 二级标题)。
注:#号与文本之间有一个空格。1
2
3
4
5
6
7# Header one
## Header two
### Header three
#### Header four
##### Header five
###### Header six
plain text
效果如下:

语法如下:
1 | [Visit GitHub!](www.github.com) |
再比如:
1 | [You're **really, really** going to see this.](www.dailykitten.com) |
You're really, really going to see this.
语法如下:
1 | Do you want to [see something fun][a fun place]? |
效果如下:
Do you want to see something fun?
Well, I have a website for you!
一般可将链接地址写在Markdown文件的最后。使用refrence的好处是如果有许多链接都是指向一个地方,那么需要更改的时候只需要修改一次就行了。
另外如果直接粘贴链接,有可能只是显示为文本没有显示为超链接,例如
https://daringfireball.net/projects/markdown
。可以在链接前后加上<>,例如:<https://daringfireball.net/projects/markdown/>,效果:https://daringfireball.net/projects/markdown/
插入图片和插入链接类似,语法如下:
1 |  |
shift+enter: 运行代码块
shift+tab: show the documentation pop up for the method
Esc+m: markdown语句
jupyter notebook中reload模块:
参考 https://blog.csdn.net/ybdesire/article/details/86709727
1 | #对于 python2.x |
Lists are mutable.
1 | amazon_cart = [ |
1 | >>>x = [1,2,3,4,5,6] |
缩进是 Python的灵魂
关于 Python 的教程可参考廖雪峰的网站
https://www.liaoxuefeng.com/wiki/1016959663602400
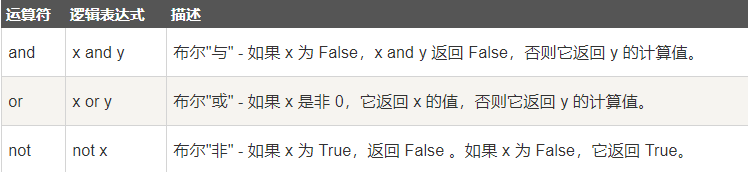
1 | df[(df['id']>=1) & (df['id']<=2)] |
>, <, >=, <=, ==, !=
pandas进行条件筛选和组合筛选
参考 https://www.cnblogs.com/qxh-beijing2016/p/15499009.html
1 | df = pd.DataFrame({'A':[100, 200, 300, 400, 500],'B':['a', 'b', 'c', 'd', 'e'],'C':[1, 2, 3, 4, 5]}) |
(1)找出df中A列值为100、200、300的所有数据
1 | num_list = [100, 200, 300] |
(2)找出df中A列值为100且B列值为‘a’的所有数据
1 | df[(df.A==100)&(df.B=='a')] |
(3)找出df中A列值为100或B列值为‘b’的所有数据
1 | df[(df.A==100)|(df.B=='b')] |
注:多条件筛选的时候,必须加括号'()'
一篇测试文章.