参考
Chi-Square
Test vs. t-Test: What's the Difference? - Statology
Chi-Square Test | How
to Calculate Chi-square using Formula with Example (byjus.com)
⬅可查看卡方表
1. 卡方检验
实际上卡方检验有几种不同的版本,但最常见的是卡方独立性检验(Chi-Square
Test of Independence)。
1.1 定义
当我们想要检验两个分类变量之间是否存在统计上显着的关联时,我们使用卡方独立性检验。
原假设(\(H_0\)):
两个变量之间没有显著的关联。 备择假设(\(H_a\)): 两个变量之间有显著的关联。
即:拒绝原假设,表示两个变量之间有显著的关联
1.2 案例
以下是可能用到卡方独立性检验的一些例子。
(1)案例1:
我们想知道性别(男性、女性)和政党偏好(共和党、民主党、独立党派)之间是否有统计学上的显著关联。为了验证这一点,我们可以随机调查100个人,记录他们的性别和政党偏好。然后,我们可以对独立性进行卡方检验,以确定性别和政党偏好之间是否有统计学上的显著关联。
(2)案例2:
我们想知道年级(大一、大二、大三、大四)和最喜欢的电影类型(惊悚片、戏剧、西部片)之间是否有统计学上的显著关联。为了验证这一点,我们可以随机调查某所学校每个年级的100名学生,并记录下他们最喜欢的电影类型。然后,我们可以对独立性进行卡方检验,以确定年级和喜爱的电影类型之间是否有统计学意义上的关联。
(3)案例3:
我们想知道一个人最喜欢的运动(篮球、棒球、足球)和他们成长的地方(城市、农村)之间是否有统计学上的显著关联。为了验证这一点,我们可以随机调查100个人,问他们在什么样的地方长大,他们最喜欢的运动是什么。然后,我们可以对独立性进行卡方检验,以确定一个人最喜欢的运动和他们成长的地方之间是否有统计学上的显著关联
1.3 假设
在对独立性进行卡方检验之前,我们首先需要确保满足以下假设,以确保检验有效
- 随机:应该使用随机样本或随机实验来收集两个样本的数据。
- 分类型:我们正在研究的变量应该是分类型的。
- 样本量 :变量的每个取值的预期观察数应至少为5。
1.4 如何计算
参考 https://www.statology.org/chi-square-test-of-independence/
\[
\chi^2=\frac{\sum(O-E)^2}{E}
\]
where: \(O:\) observed value \(E:\) expected value
If the p-value that corresponds to the test statistic X2 with
(#rows-1)*(#columns-1) degrees of freedom
is less than your chosen significance level then you can reject the null
hypothesis.
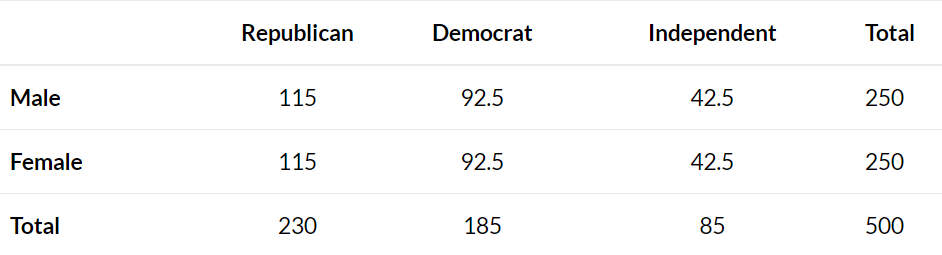
假设我们想知道性别是否与政党偏好有关。我们随机抽取500名选民,调查他们的政党偏好。下表显示了调查结果:

接下来,我们将用下面的公式计算列联表中每个单元格的期望值 \[
Expected\ value = (row\ sum * column\ sum) / table\ sum.
\] For example, the expected value for Male Republicans is: \((230*250) / 500 = 115\). We can repeat this
formula to obtain the expected value for each cell in the table:
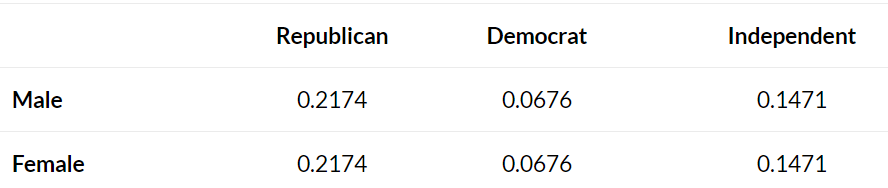
下一步,对每个单元格计算\((O-E)^2/E\) For example, Male Republicans
would have a value of: \((120-115)^2 /115 =
0.2174\). We can repeat this formula for each cell in the
table:
计算检验统计量 \(\chi^2\)
和相应的p值:
\(\chi^2 = Σ(O-E)^2 / E = 0.2174 + 0.2174 +
0.0676 + 0.0676 + 0.1471 + 0.1471 =0.8642\)
According to the Chi-Square
Score to P Value Calculator, the p-value associated with \(\chi^2\) = 0.8642 and (2-1)*(3-1) = 2
degrees of freedom is 0.649198.
由于这个p值不小于0.05,我们无法拒绝零假设。这意味着我们没有足够的证据表明性别和政党偏好之间存在联系。
Note : You can also perform this entire
test by simply using the Chi-Square
Test of Independence Calculator.