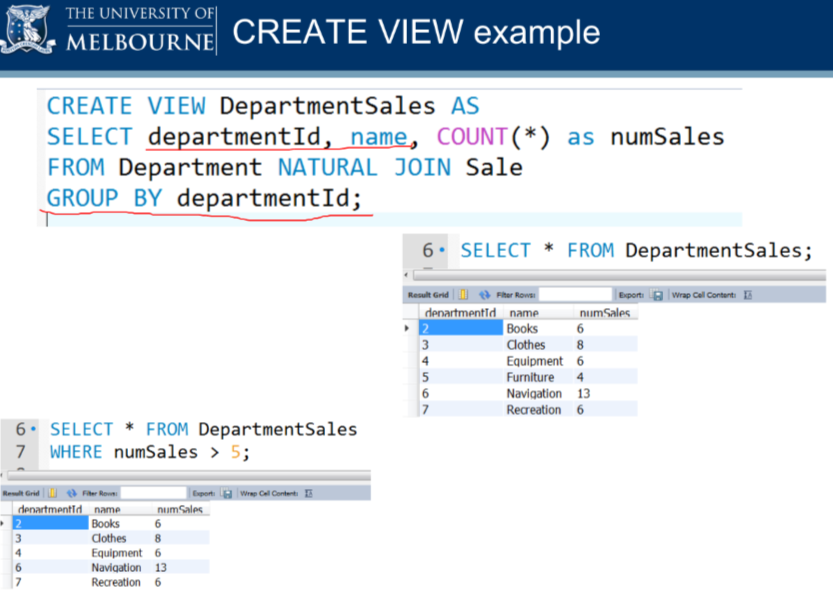
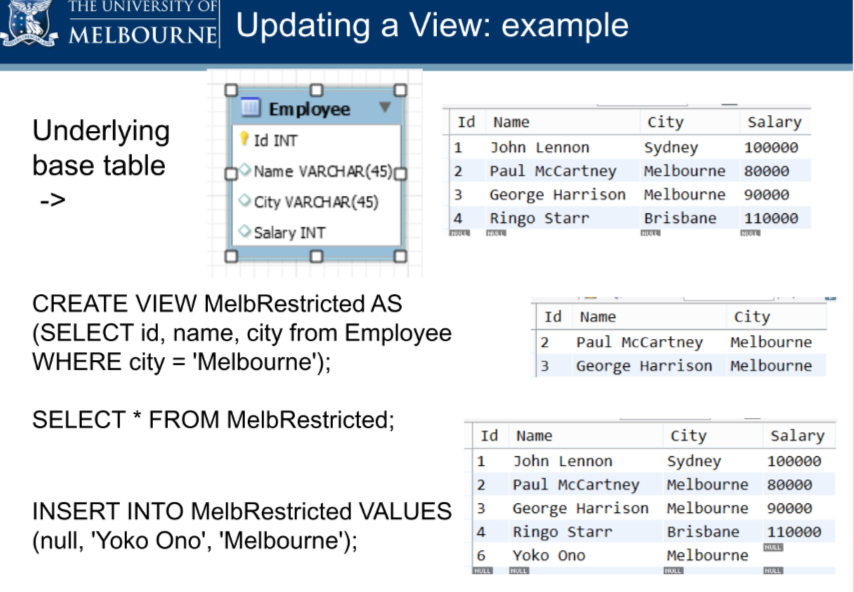
With streaming technologies such as Kafka, you can actually process
new data as it's generated into your cluster, maybe you're gonna save it
into HDFS, maybe you'll save it into HBase or some other database or
maybe you'll actually process it in real time as it comes in.
Usually when we're talking about Big Data, there's a big flow of it
coming in all the time and you want to be dealing with it as it comes
instead of storing it up and dealing with it in batches.
1579417930302
Enter Kafka
1579418299281
The good thing is that Kafka because it stores it, consumers can
catch up from where they last left off, so it will maintain the point
where each consumer left off and allow them to just pick up whenever
they want to. So it can publish data in real time to your consumers, but
if your consumer goes off line or just wants to catch up from some point
in the past, it can do that too.
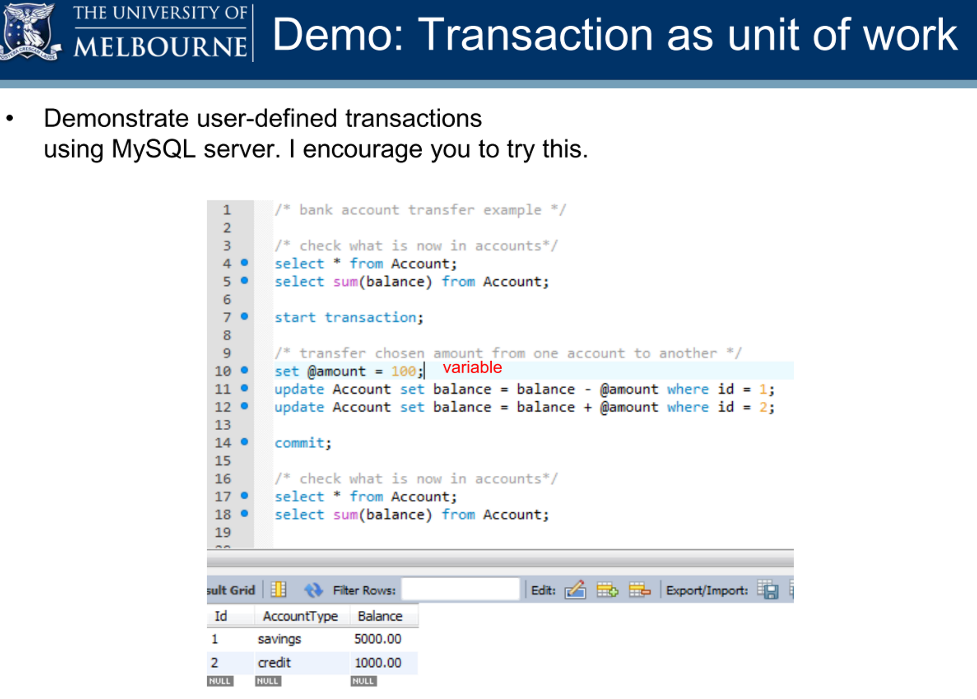
We've talked about integrating Hadoop with SQL solutions - MySQL -
RDBMSs, if you will - relational database management systems - and those
are very handy for giving you the power of a rich analytical query
language like SQL to answer your business questions. But, you know, they
do take a little bit of time to execute. So if you're doing
analytic work, relational databases are awesome. Even if you're
running a small, like, say, an internal web site or a very small-scale
web site, something like MySQL can even vend that data to the outside
world pretty well.
BUT let's imagine you need to take things up to the next level.
You're going to start to run into some limitations with SQL and
relational database systems.
Maybe you don't really need the ability to issue arbitrary queries
across your entire dataset. Maybe all you need is just the ability to
very quickly answer a specific question like "What
movie should I recommend for this customer?" or "What web pages has this
customer looked at in the past?"
And if you need to do that at a very large scale very quickly
across a massive dataset, something like MySQL might not cut
it. You know, if you're an Amazon or a Google, you might need something
that can even handle tens of thousands of transactions per
second without breaking a sweat. And that's where NoSQL comes
in.
These are alternative database systems that give up a rich
query language like SQL for the ability to very quickly and at
great scale answer very simple questions. So for systems like that you
want something called NoSQL, also known as non-relational databases, or
not only SQL - that's a term that comes up sometimes, too. And
these systems are built to scale horizontally forever, and also
built to be very fast and very resilient.
Up first, let's talk about HBase. HBase is actually built on top of
HDFS, so it allows you to have a very fast, very scalable transactional
system to query your data that's stored on a horizontally partitioned
HDFS file system. So if you need to expose your massive data that's
sitting on your Hadoop cluster, Hbase can be a great way to expose that
data to a web service, to web applications, anything that needs to
operate very quickly and at a very high scale.
We can actually make your Hadoop cluster look like a relational
database through a technology called Hive. And there's
also ways of integrating a new Hadoop cluster with a MySQL database.
1579064046135
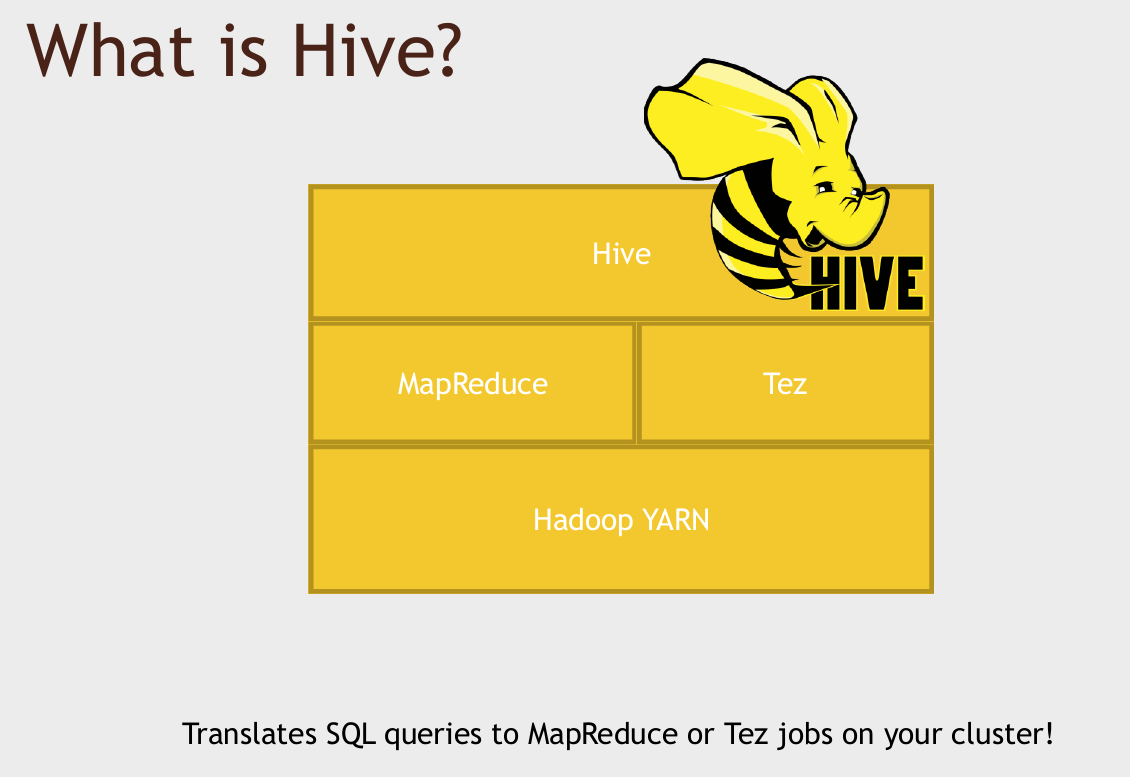
What is Hive?
It lets you write standard SQL queries that look just like you'd be
using them on MySQL, but actually execute them on data that's stored
across your entire cluster, maybe on an HDFS cluster as well.
1579064255091
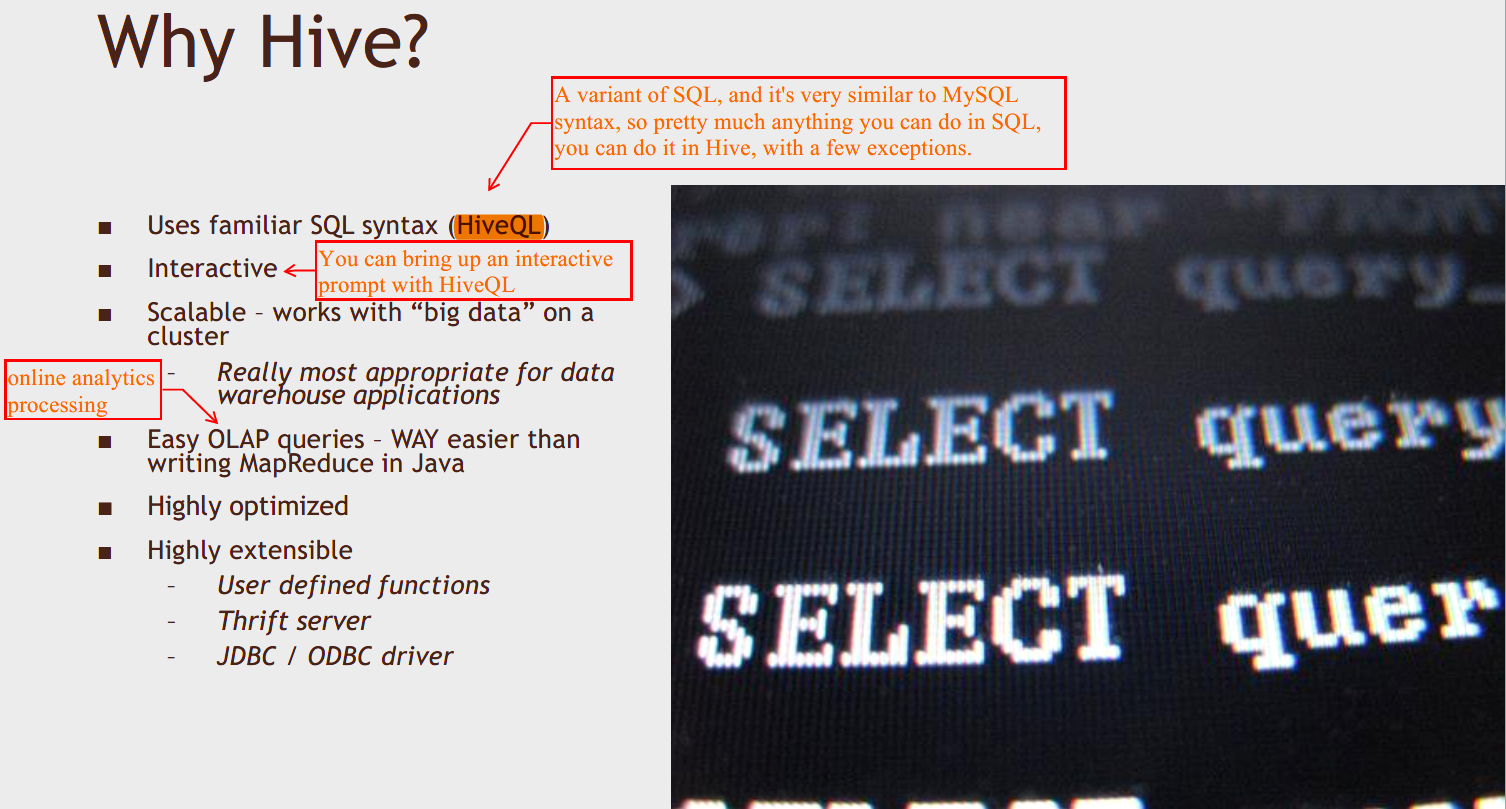
Why Hive
1579082214734
Why not Hive
1579083363568
It's not really meant for being hit with tons of queries all at once,
from a website or something like that. That's where you use something
like HBase instead.
Hive is a bunch of smoke and mirrors to make it look like a database,
so you can issue SQL queries on it, but it isn't really.
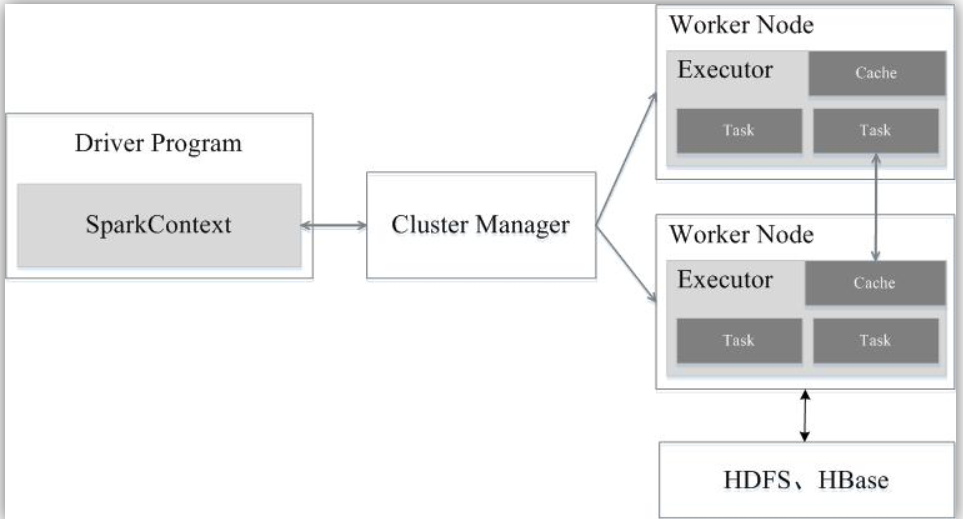
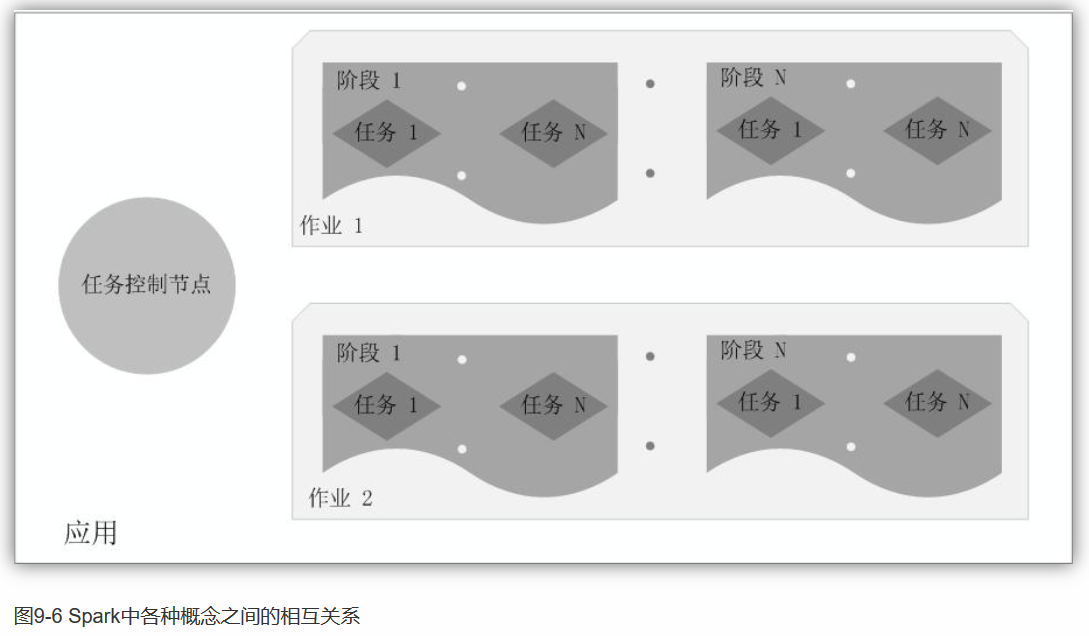
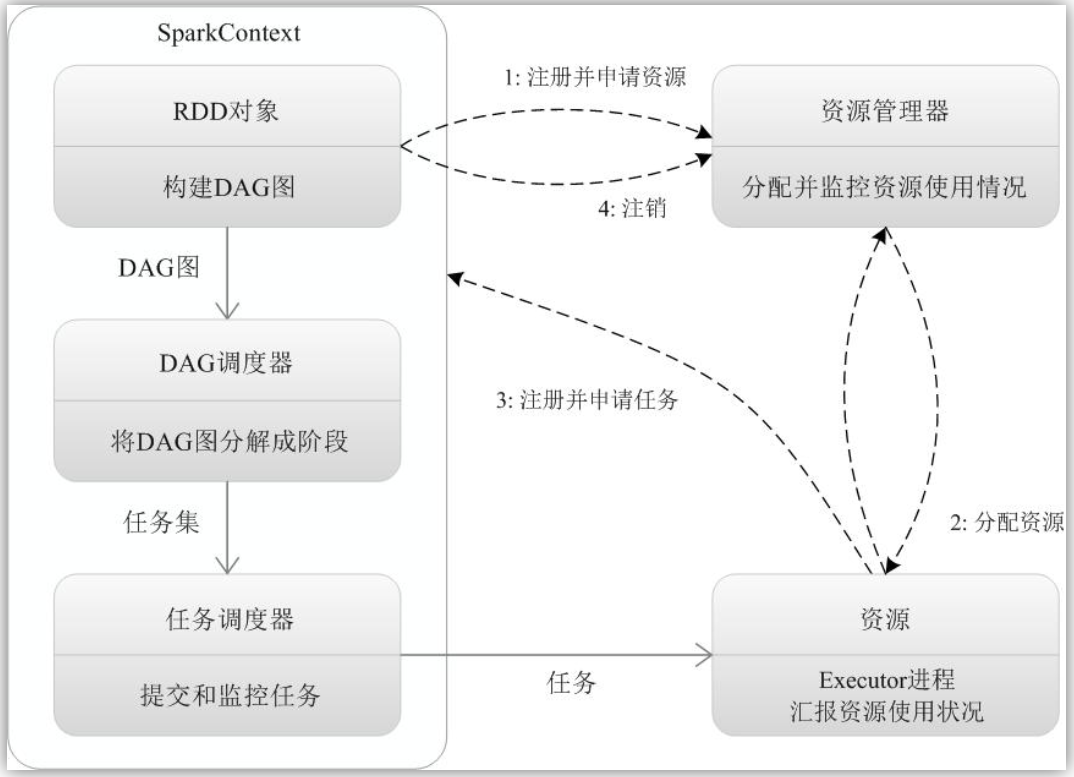
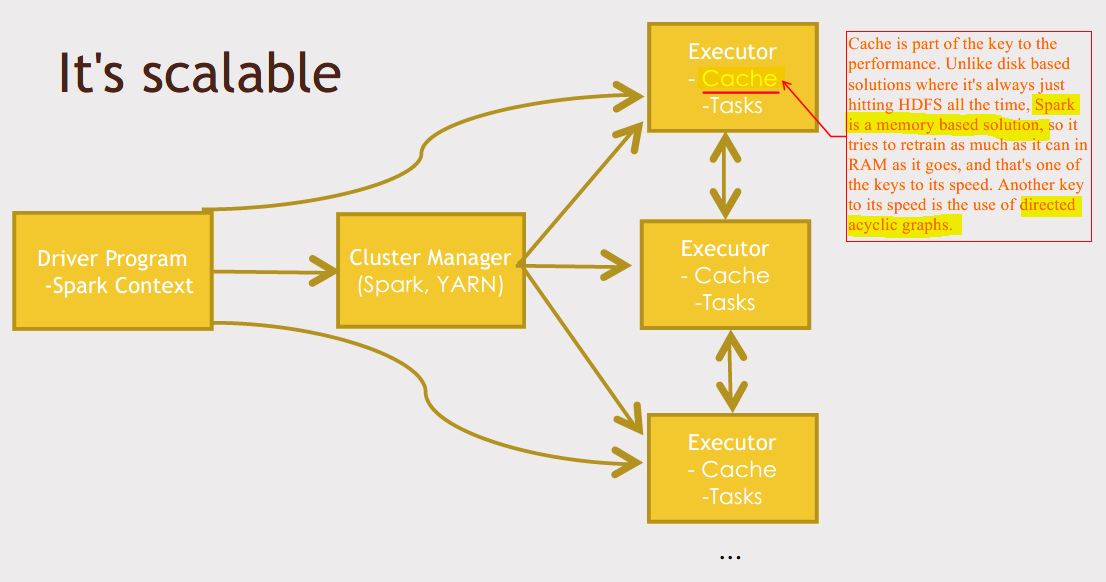
Spark除了比MapReduce更快以外,还有一个优势:MapReduce is very limited
in what it can do. You have to think about things in terms of mappers
and reducers, whereas Spark provides a framework for removing that level
of though from you, you can just think more about your end results and
program toward that and think less about how to actual distribute it
across the cluster.