What we need now is a framework to let us easily experiment with new
recommender system algorithms, evaluate them, and compare them against
each other.
1578205315867
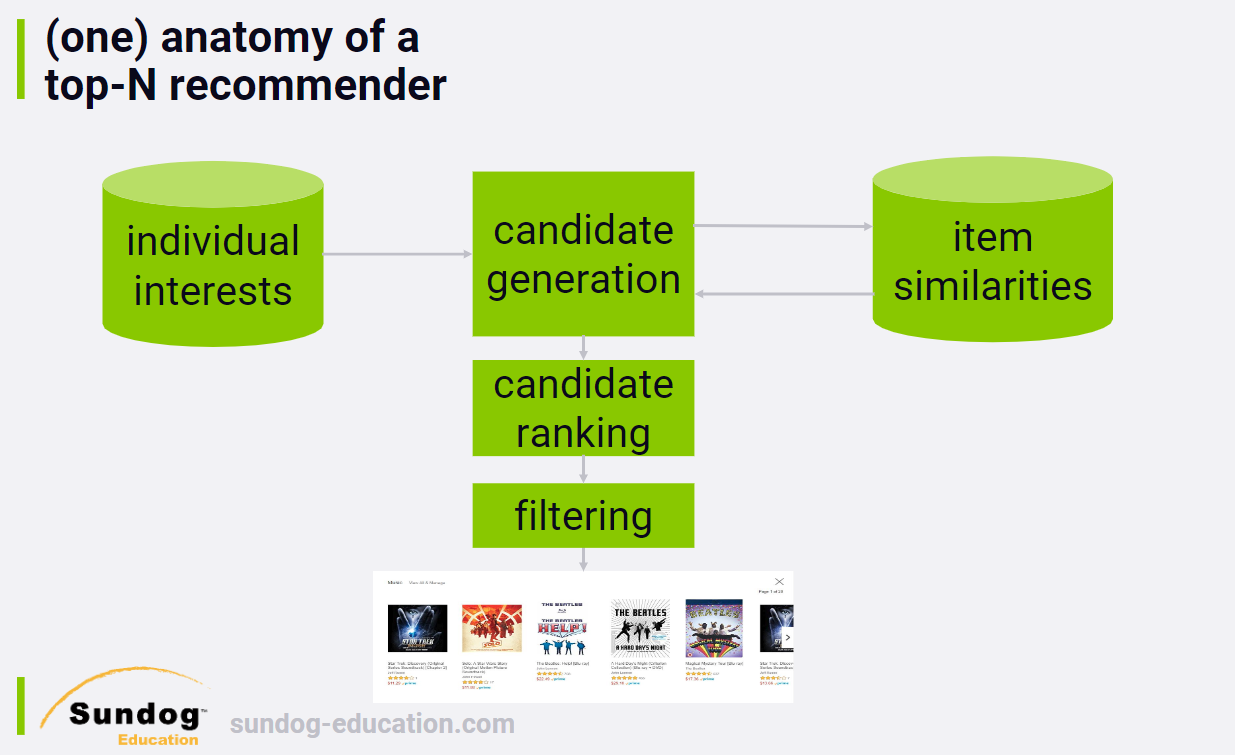
1. Our Recommender Engine
Architecture
1578205676375
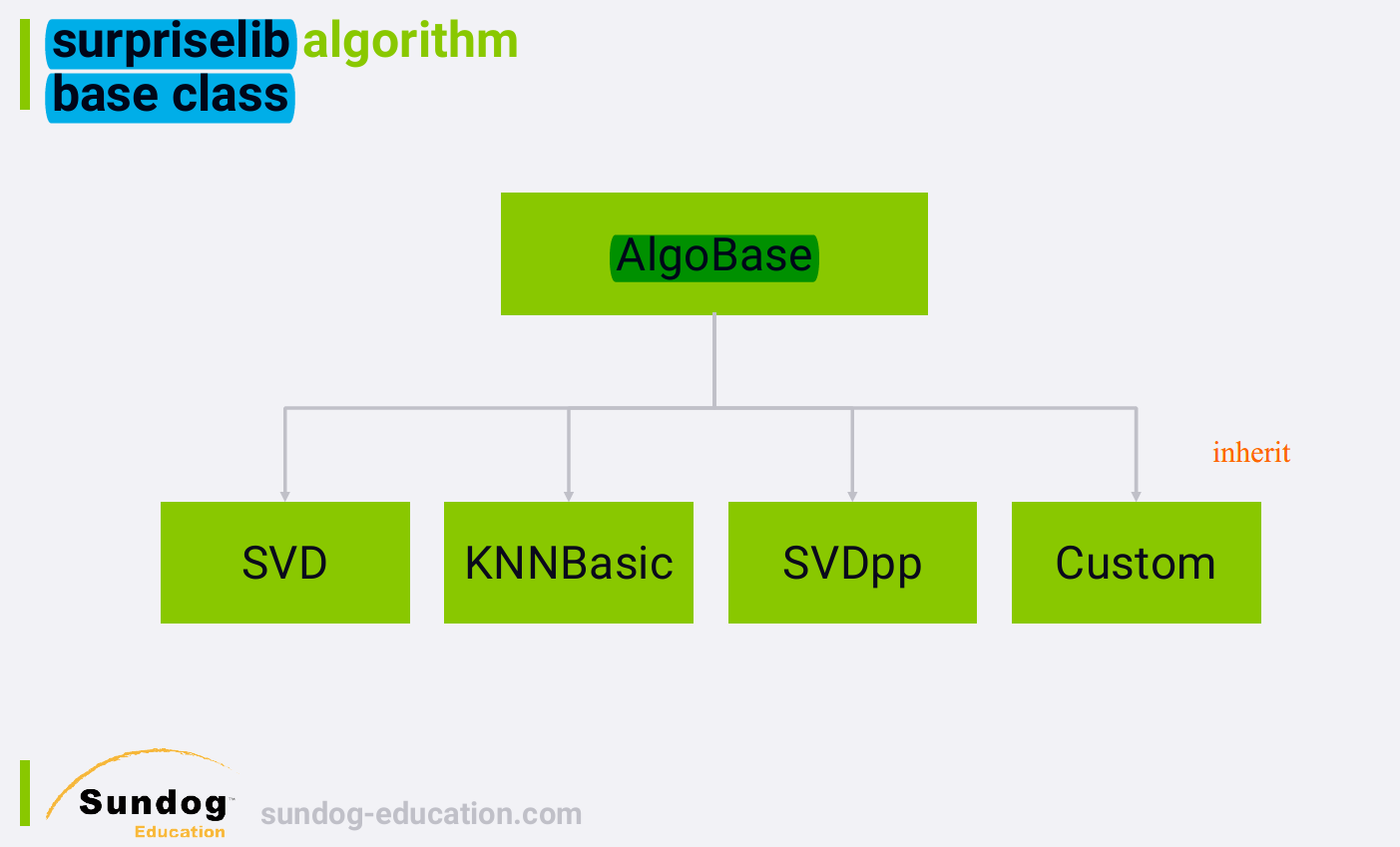
Object oriented design allows us to have base classes, for example,
AlgoBase, that contain functions and variables that can be shared by
other classes that inherit from that base class.
例如AlgoBase中实现了fit和test方法,则无论我们实际上使用的是什么算法,我们都可以调用fit和test方法。
Custom指的是any custom algorithm we might develop
(自己写的recommender system), and make them part of the supriselib
framework.
Create a custom algorithm
So, how do you write your own recommender algorithm that's compatible
with surpiselib?
1578207092161
All you have to do is create a new class that inherits form AlgoBase,
and as far as supriselib is concerned, your algorithm has one job: to
predict ratings.
As we mentioned, supriselib is built around the architecture of
predicting the ratings of every movie for every user, and giving back
the top predictions as your recommendations.
Your class have to implement an estimate function.
When estimate is called by supriselib framework, it's asking you to
predict a rating for the user and item passed in.
注:这里的user id和item id是inner id. Must be mapped back to the raw
user and item ids in your source data.
Now, we want to do more than just predict ratings.
我们想要很简单的将之前在RecommenderMetrics中实现的不同的evaluation
metrics应用到algorithms we work with.
1578207683880
为了做到这一点,我们将创建一个新的class叫做EvaluatedAlgoritm,里面创建了一个新的函数叫做Evaluate,that
runs all the metrics in RecommenderMetrics on that algorithm. So this
class makes it easy to measure accuracy, coverage, diversity and
everything else on a given algorithm.
We create an EvaluationData instance with our data set,
create an EvaluatedAlgorithm for each algorithm we want to
evaluate, and call Evaluate on each algorithm using the
same EvaluationData. Under the hood,
EvaluatedAlgorithm will use all the functions we defined in
RecommenderMetrics to measure accuracy, hit rate,
diversity, novelty, and coverage.
Since what we generally want to do is 比较不同推荐系统, we can make
life even easier by writing a class that takes care of all the
comparison for us. 于是我们创建了新的class:Evaluator.
Ideally, we want to just submit algorithms we want to evaluate
against each other into this class, and let it do everything from
there.
1578208719473
The beauty of this is that you don't even have to use the
EvalutedAlgorithm or EvaluatedData classed at
all, when you want to start playing around with new algorithms and
testing them against each other. All you need to do is use this
Evaluator class, which has a really simple interface.
将上述framework写好后,如下这是我们比较SVD算法与random算法所需要的所有代码:
1578208901255
2. Code Walkthrough
Framework文件夹里:
1578209106245
结果分析
1578283638478
我们比较的是SVD和随机推荐。SVD is one of the best algorithms
available right now, so it shouldn't be surprise that SVD beats random
recommendation in accuracy and hit rate no matter how we measure it.
RMSE和MAE: lower is better.
Hit rate,包括cHR, ARHR: higher is better.
Coverage, diversity, novelty: need to apply some common sense to, as
it's not a clear higher-is-better sort of thing. There are trade-offs
involved with these metrics.
就Coverage而言,SVD的要低一些: that's just because we are enforcing a
quality threshold on the top-N recommendations we're making with SVD,
while our random recommender isn't actually making totally random
recommendations, it's predicting movie ratings using what's called a
normal distribution centered around the average rating value, which ends
up meaning all of the rating predictions it makes fall above our rating
threshold, giving us 100% coverage. Having 100% coverage at the expense
of having bad recommendations isn't a trade-off worth making.
1. The
methodology for testing recommender systems offline.
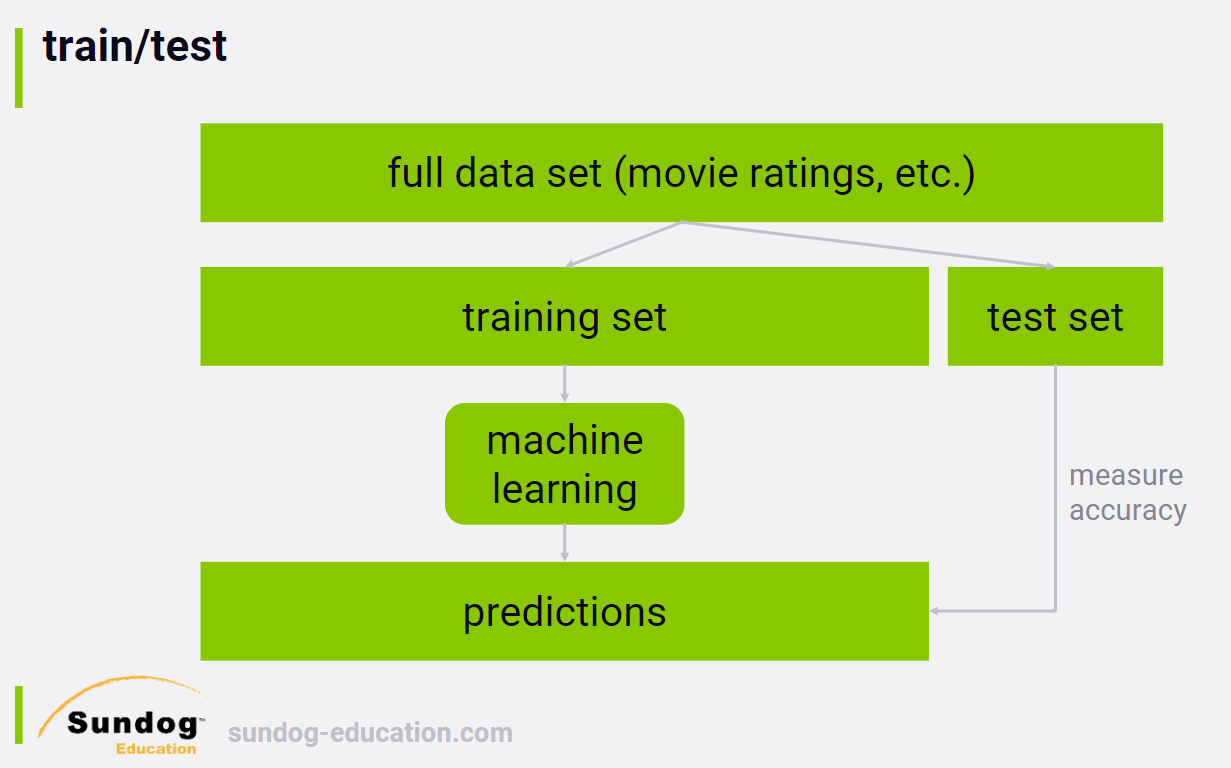
1.1 train/test split
1578116193748
You measure your recommender system's ability to predict how people
rated things in the past.
If you do this over enough people, you can end up with a meaningful
number that tells you how good your recommender system is at
recommending things, or more specifically, recommending things people
already watched and rated. That's really all you can do, if you
can't test things out in an online system.
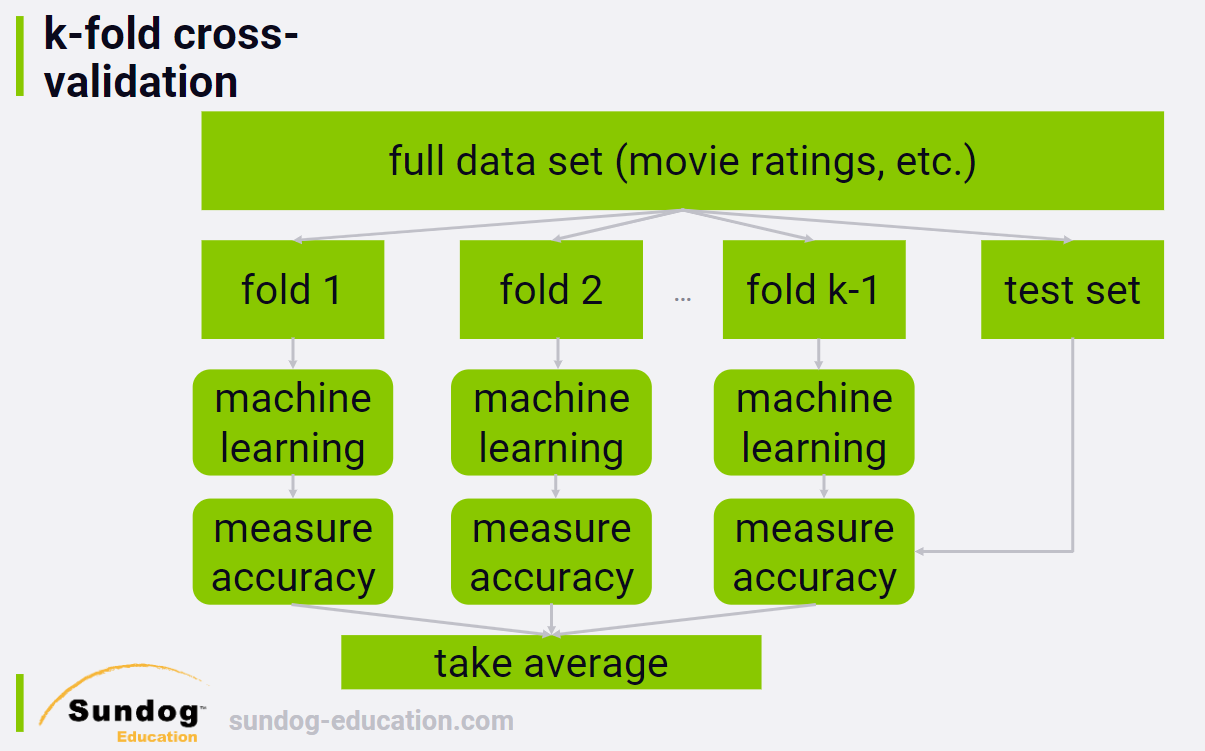
1.2 k-fold cross-validation
If you really want to get fancy, it's possible to improve on a single
train/test split by using a technique called k-fold cross
validation.
1578116897885
Instead of a single training set, we create many randomly assigned
training sets. Each individual training set, or fold, is used to train
your recommender system independently, and then we measure the accuracy
of the resulting systems against your test set. So we end up with a
score of how accurate each fold ends up predicting user ratings, and we
can average them together.
This obviously takes a lot more computing power to do, but the
advantage is that you don't end up over-fitting to a single training
set.
注:By using train/test, all we can do is test our ability to predict
how people rated movies they already saw. That's not the point of a
recommender system. We want to recommend new things to people that they
haven't seen, but find interesting. However, that's fundamentally
impossible to test offline.
We haven't talked about how to actually come up with an accuracy
metric when testing our recommender systems, so let's cover a couple of
different ways to do it.
2. Accuracy Metrics (RMSE, MAE)
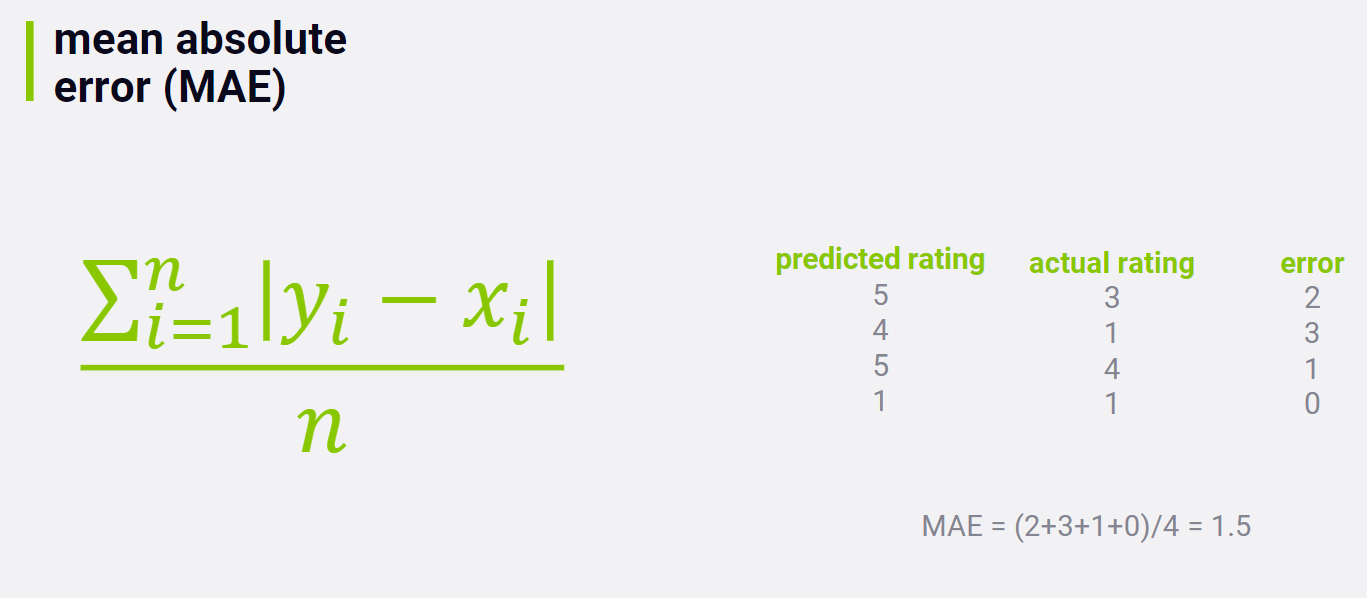
2.1 MAE
We want to minimize MAE.
1578117806539
2.2 RMSE
We want to minimize RMSE.
This is a more popular metric for a few reasons, but one is that
it penalizes you more when your rating prediction is way off,
and penalizes you less when your are reasonably close.
1578117900853
注:就推荐系统而言,RMSE just doesn't matter much in the real world.
人们并不关心你的系统对他们已经看过的电影的评分预测是否准确。What does
matter is which movie you put in front of users in a top-N recommender
list, and how those users react to those movies when they see them
recommended.
3. Top-N Hit Rate - Many Ways
Different ways to measure the effectivenss of top-n recommenders
offline:
3.1 Hit Rate
You generate top-n recommendations for all of the users in your test
set. If one of the recommendations in a user's top-n
recommendations is something they actually rated, you consider that a
hit. You actually managed to show the user something that they
found interesting enough to watch on their own already, so we consider
that a success.
1578119273699
How to measure hit rate? Use leave-one-out cross validation.
3.2 leave-one-out cross
validation
What we do is compute the top-n recommendations for each user in our
training data, and intentionally remove one of those items from that
user's training data. We then test our recommender system's ability to
recommend that item that was left out in the top-n results it creates
for that user in the testing phase.
1578120352619
The trouble is that it's a lot harder to get one specific movie right
while testing than to just get one of the n recommendations. So "hit
rate" with "leave-one-out" tends to be very small and difficult to
measure, unless you have a very large data set to work with. But it's a
much more user focused metric when you know your
recommender system will be producing top-n lists in the real world,
which most of them do.
3.3 ARHR
This metric is just like "hit rate", but it accounts for where in the
top-n list you hits appear. Instead of summing up the number of hits, we
sum up the reciprocal ranking of each hit.
1578122155631
You end up getting more credit for successfully recommending an item
in the top slot than in the bottom slot. Again, this is a more
user focused metric, since users tend to focus on the
beginning of lists.
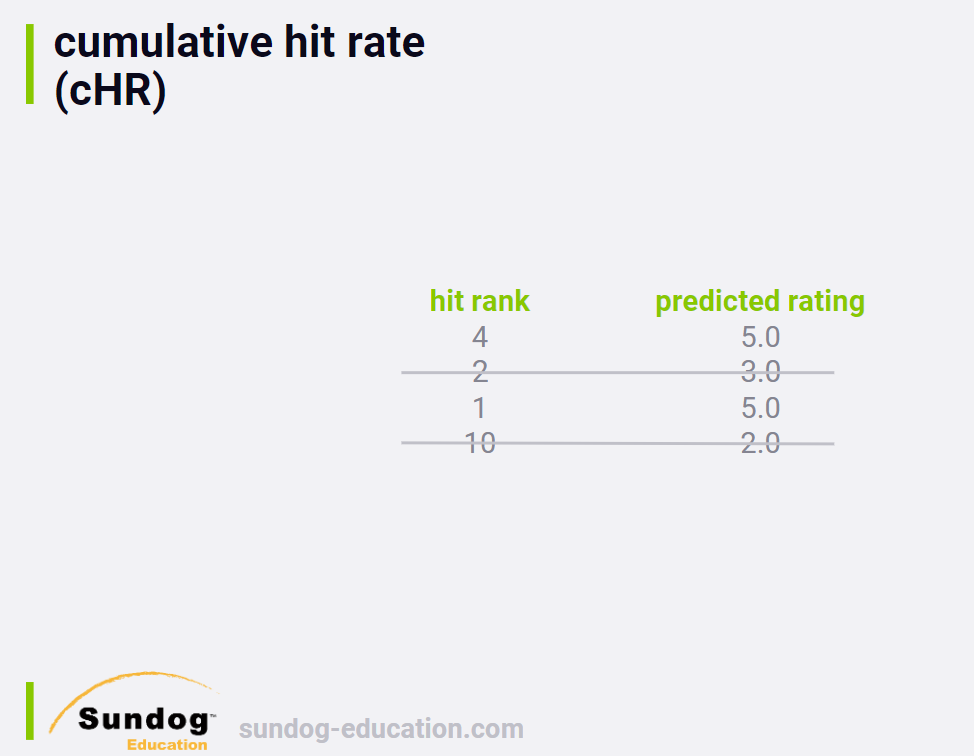
3.4 cHR
Throw away hits if our predicted rating is below some threshold.
The idea is that we shouldn't get credit for recommending items to a
user that we think they won't actually enjoy.
1578122704818
In this example, if we had a cutoff of three stars, we throw away the
hits for the second and fourth items in these test results and our hit
rate metric wouldn't count them at all.
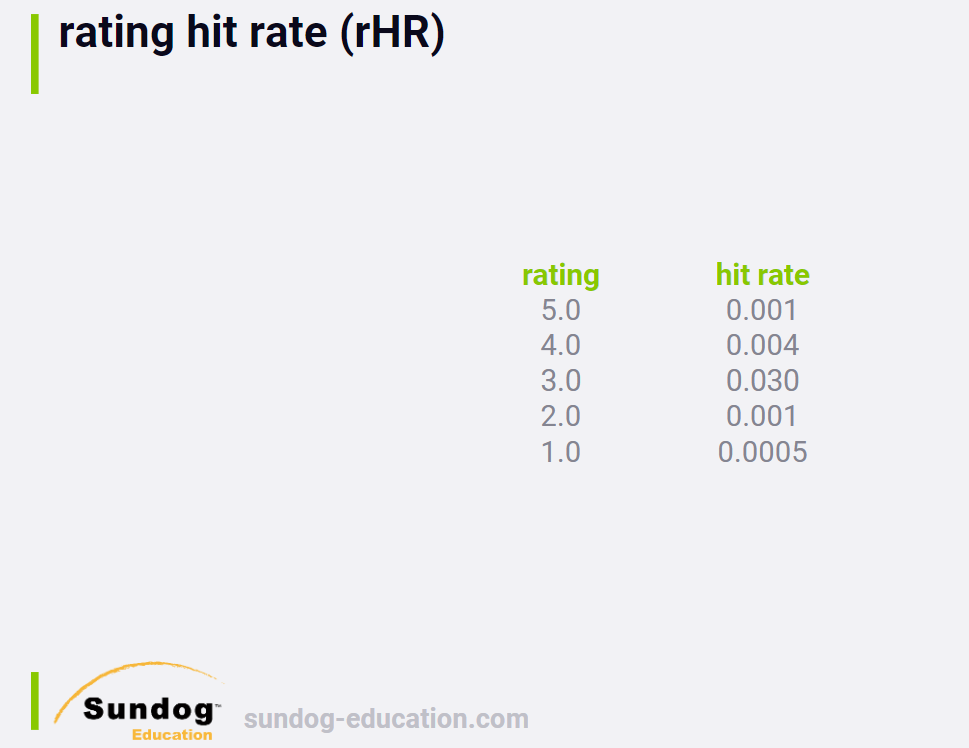
3.5 rHR
Another way to look at hit rate is to break it down by predicted
rating score.
It can be a good way to get an idea of the distribution of how good
your algorithm thinks recommended movies are that actually get a hit.
Ideally, you want to recommend movies that they actually like, and
breaking down the distribution gives you some sense of how well you're
doing in more detail.
1578123016707
对每一个rating type (1,2,3,4,5), print out its hit rate.
4. Coverage, Diversity and
Novelty
Accuracy isn't the only thing that matters.
4.1 Coverage 覆盖度
The percentage of possible recommendations that your system is able
to provide.
1578123495150
It's worth noting that coverage can be at odds with accuracy. If you
enforce a higher quality threshold on the recommendations you make, then
you might improve your accuracy at the expense of coverage. Finding the
balance of where exactly you're better off recommending nothing at all
can be delicate.
Coverage can also be important to watch, because it gives you a sense
of how quickly new items in your catalog will start to appear in your
recommendations. When a new book come out on Amazon, it won't appear in
recommendations until at least a few people buy it, therefore
establishing patterns with the purchase of other items. Until those
patterns exist, that new book will reduce Amazon's coverage metric.
4.2 Diversity 多样性
You can think of this as measure of how broad a variety of items your
recommender system is putting in front of people. An example of low
diversity would be a recommender system that just recommends the next
books in a series that you've started reading, but doesn't recommend
book from different authors, or movies related to what you've read.
1578124451718
Diversity, at least in the context of recommender systems, isn't
always a good thing. You can achieve very high diversity by just
recommending completely random items. Unusually high diversity scores
mean that you just have bad recommendations more often than not. You
always need to look at diversity alongside metrics that measure the
quality of the recommendations as well.
4.3 Novelty 新颖性
Similarly, novelty sounds like a good thing, but often it isn't.
Novelty is a measure of how popular the items are that you are
recommending. And again, just recommending random stuff would yield very
high novelty scores, since the vast majority of items are not top
sellers.
1578124908363
Although novelty is measurable, what to do with it is in many ways
subjective. There's a concept of user trust in a recommender system.
People want to see at least a few familiar items in their
recommendations that make them say, "Yeah, that's a good recommendation
for me. The system seems good". If you only recommend things people
never heard of, they may conclude that your system doesn't really know
them. Also, popular items are usually popular for a reason. They're
enjoyable by a large segment of the population, so you would expect them
to be good recommendations for a large segment of the population who
hasn't read or watched them yet. If you're not recommending some popular
items, you should probably question whether your recommender system is
really working as it should.
You need to strike a balance between familiar, popular items
and what we call serendipitous discovery of new items that user has
never heard of before. (balance between novelty and trust). The
familiar items establish trust with the user, and the new ones allow the
user to discover entirely new things that they might love.
Novelty is important, because the whole point of recommender systems
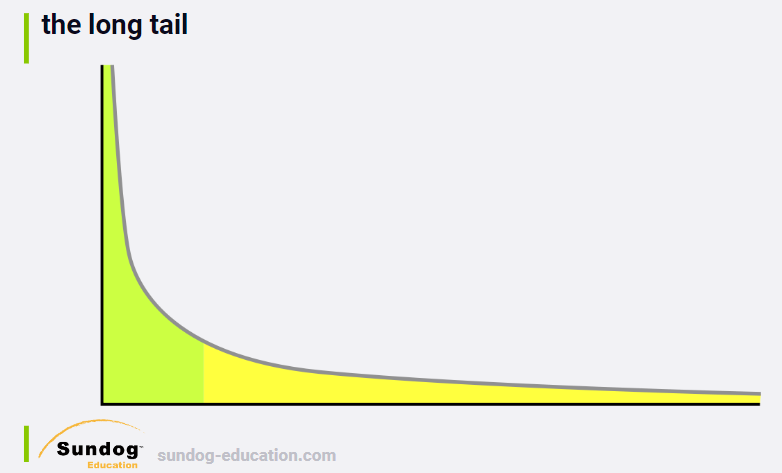
is to surface items in what we call "the long tail".
1578125635846
Imagine this is a plot of the sales of every item in you catalog,
sorted by sales. Y 轴代表sales (popularity),X轴代表products. Most of
sales来自于一小部分items,但是"long tail" makes up a large amount of
sales as well. 黄色部分的item代表了人们各自感兴趣的东西. Recommender
systems can help people discover those items in the long tail that are
relevant to their own unique niche interests. If you can do that
successfully, then the recommendations your system makes can help new
authors get discovered, can help people explore their own passions, and
make money for whoever you're building the system for as well. Everybody
wins.
5. Churn, Responsiveness, and
A/B Tests
5.1 Churn
Another thing we can measure is Churn.
1578127764650
Churn can measure how sensitive your recommender system is to new
user behavior.
如果用户rate了一部新电影,会使得他的推荐内容发生很大的变化吗?If so,
your churn score will be high. Maybe just showing the same
recommendations too many times is a bad idea itself.
如果一个用户总是看到相同的推荐,但是不点击进去,在某个时候你应该停止推荐它而给用户推荐其他的东西。Sometimes,
a little bit of randomization in your top-n recommendations can keep
them looking fresh, and expose your users to more items.
But, just like diversity and novelty, high churn is not in itself a
good thing. You could maximize your churn metric by just recommending
items completely at random, 但显然这不是好的推荐。
All these metrics need to be looked at together, and you need
to understand the trade-offs between them.
5.2 Responsiveness
1578128338650
If you rate a new movie, does it affect your recommendations
immediately or next day after some nightly job runs? More responsiveness
would always seem to be a good thing, but in the world of business, you
have to decide how responsive your recommender really needs to be, since
recommender systems that have instantaneous responsiveness are complex,
difficult to maintain, and expensive to build. You need to strike your
own balance between responsiveness and simplicity.
? What's important
前面讲了许多evaluate推荐系统的方法:MAE, RMSE, Hit rate in various
forms, coverage, diversity, novelty, churn, and responsiveness.
So how do you know what to focus on? It depends.
It may even depend on cultural factors. Some cultures may want more
diversity and novelty, while other cultures may want to stick to things
that are familiar with them.
It also depends on what you're trying to achieve as a business. And
usually, a business is just trying to make money, which leads to one
more way to evaluate recommender systems that is arguably the most
important of all: online A/B tests!
Doing online A/B tests to tune your recommender system using your
real customers, and measuring how they react to your recommendations.
You can put recommendations from different algorithms in front of
different sets of users, and measure if they actually buy, watch, or
otherwise indicate interest in the recommendations you've presented.
By always testing changes to your recommender system using
controlled, online experiments, you can see if they actually cause
people to discover and purchase more new things than they would have
otherwise.
None of the metrics we've discussed matter more than how real
customers react to the recommendations you produce in the real world.
You can have the most accurate rating predictions in the world, but if
customers can't find new items to buy or watch from your system, it will
be worthless from a practical standpoint.
Online tests can help you to avoid introducing complexity that adds
no value, and remember, complex systems are difficult to maintain.
SO REMEMBER, offline metrics such as accuracy, diversity, and novelty
can all be indicators you can look at while developing recommender
systems offline, but you should never declare victory until you've
measured a real impact on real users from your work. User
behavior is the ultimate test of your work.
Accurately predicted ratings don't necessarily make for good
video recommendations. At the end of the day, the results of online A/B
tests are the only evaluation that matters for your recommender
system.
Another thing you can do is just straight up ask your users, if they
think specific recommendations are good.
1578129889414
In practice though, it's a tough thing to do. Users will probably be
confused over whether you're asking them to rate the item or rate the
recommendation, so you won't really know how to interpret this data. It
also requires extra work form your customers with no clear payoff for
them, so you're unlikely to get enough ratings on your recommendations
to be useful.
It's best to just stick with online A/B tests, and measure how your
customers vote with their wallets on the quality of your
recommendations.
Suprise is built around measuring the accuracy of recommender
systems. Although this is the wrong thing to focus on, it's really the
best we can do without access to a real, large-scale website of our
own.
TestMetrics中调用了RecommenderMetrics中的方法来实现一个real
recommender system并evaluate it.
结果分析
1578201799750
RMSE大概0.9,MAE大概0.7。
On average, our guess of rating for a given movie for a given user,
was off by about 0.7 stars. RMSE is higher, meaning that we got
penalized for being way off more often than we'd like.
Remember, error metrics are bad. 你想要RMSE与MAE越低越好,if accuracy
is your goal.
1578201882902
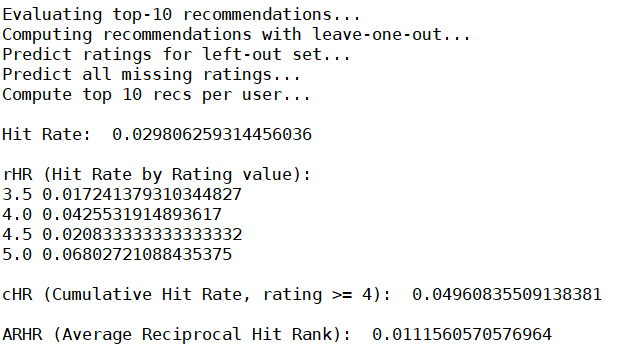
Hit Rate大概 3%,which actually isn't that bad, considering that
only one movie was left out from each user's rating to test with.
这个数值本身很难解释是好是坏,除非有其他的推荐系统可供比较。
If we break it down by rating value, you can see that our hit rate
did better at higher rating predictions, which make sense and it's what
we want to see. Hit
Rate在评分越高的类型中表现得更好(例如,在评分为5的电影中,Hit Rate为
6%)。
Cumulative Hit Rate with a 4.0 threshold isn't much lower than the
raw hit rate, meaning that we're doing a good job of recommending items
we think are good recommendations.
ARHR is 0.01. It takes the ranking of the hits into account. Again,
it has no real value until we have other recommender systems to compare
it against.
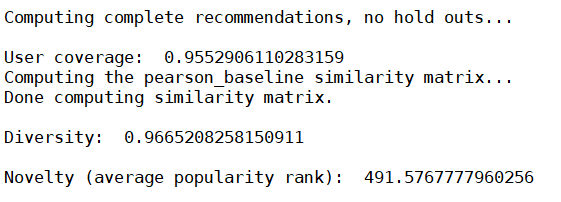
1578203470922
We look at user coverage for which we have at least one 4-star
rating prediction, ant it's pretty high. That's good.
Diversity is really high at 0.96, and novelty seems pretty high,
with an average popularity rank of 491. Remember there are only a few
thousand movies in our data set to begin with.
This tells us that our algorithm is going pretty deep into the long
tail to get its recommendations and that could be a problem in the real
world.
Novelty比较高(平均受欢迎程度排名比较靠后),说明推荐的都是比较小众的电影(long
tail).
总结
So even though our accuracy metrics look okay here, diversity and
novelty is telling us that we're recommending a lot of really obscure
stuff. And that could be an issue when trying to establish user trust in
the system. People generally want to see a few things that at least look
familiar. So I would expect this particular algorithm wouldn't do that
well in an online A/B test, but you can never really know until you
actually try it.
Anyhow, we now have working code now for evaluating real recommender
systems!
Sometimes, it's not easy to try to force a problem into this way of
thinking, and that's a big reason why other frameworks like Spark or
Hive, or other ways of processing SQL style queries have become a little
bit more popular that just writing raw MapReduce code.
But, still, if you can easily express something in terms of mapping
and reducing, this can sometimes be the most efficient way of doing
it.
1578037510439
Then, the results all get passed into the MapReduce framework which
does shuffle and sort for us. And then, we just have to write the
Reducer.
1578038403968
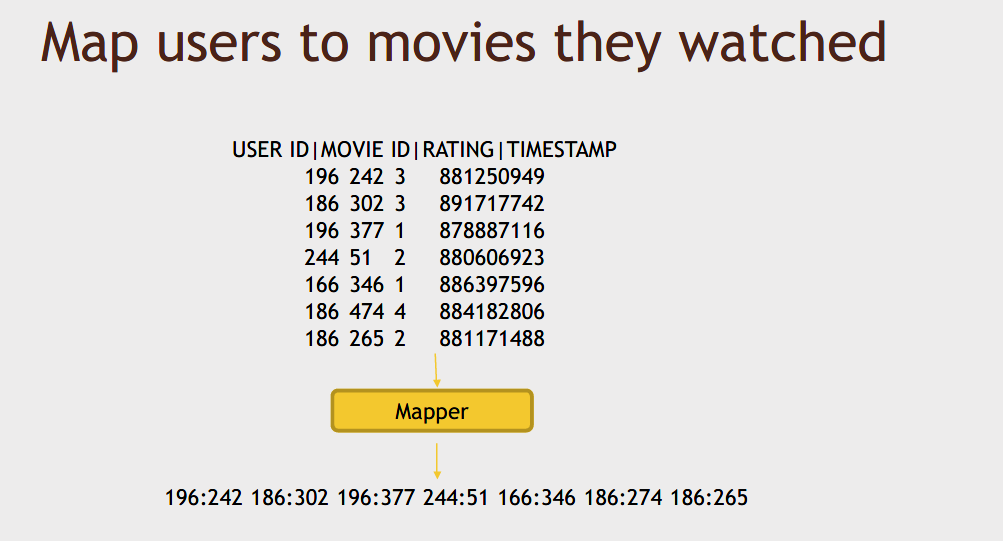
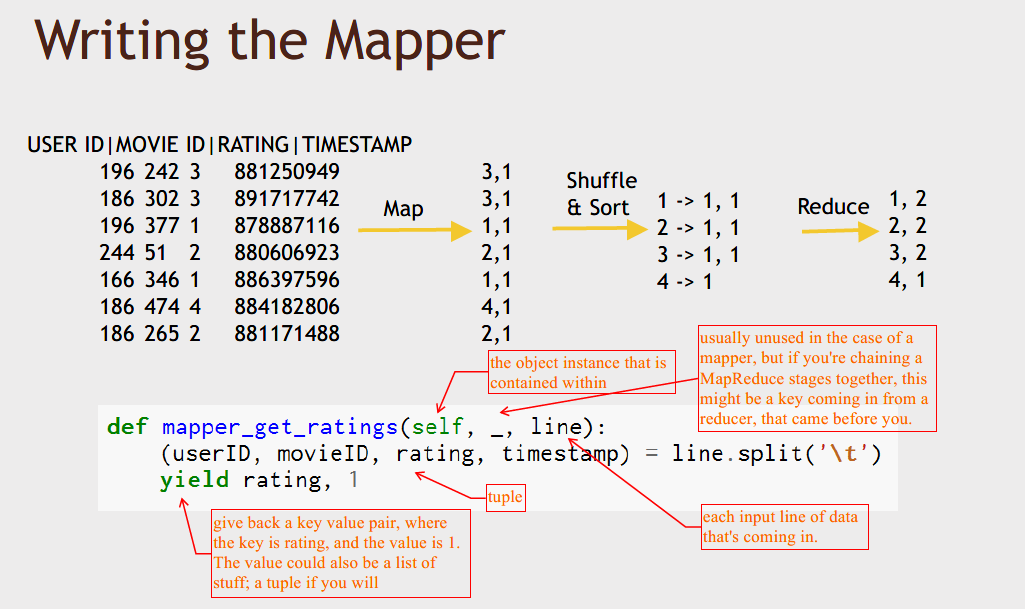
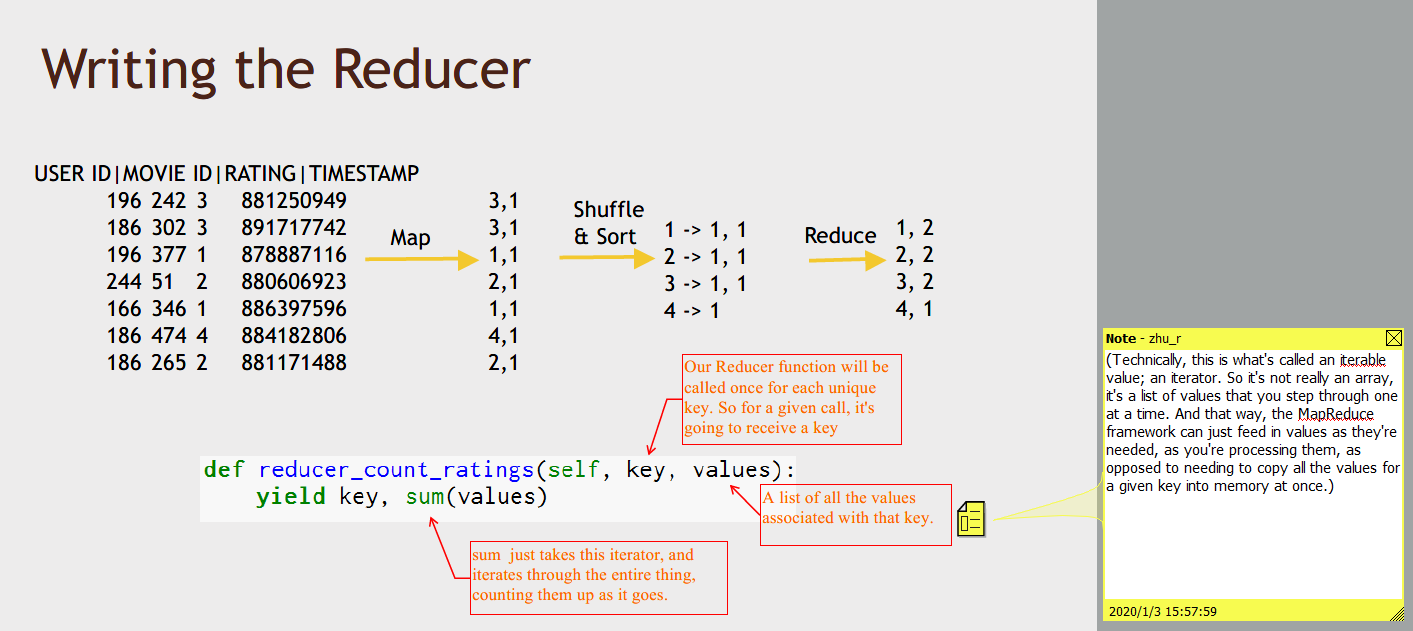
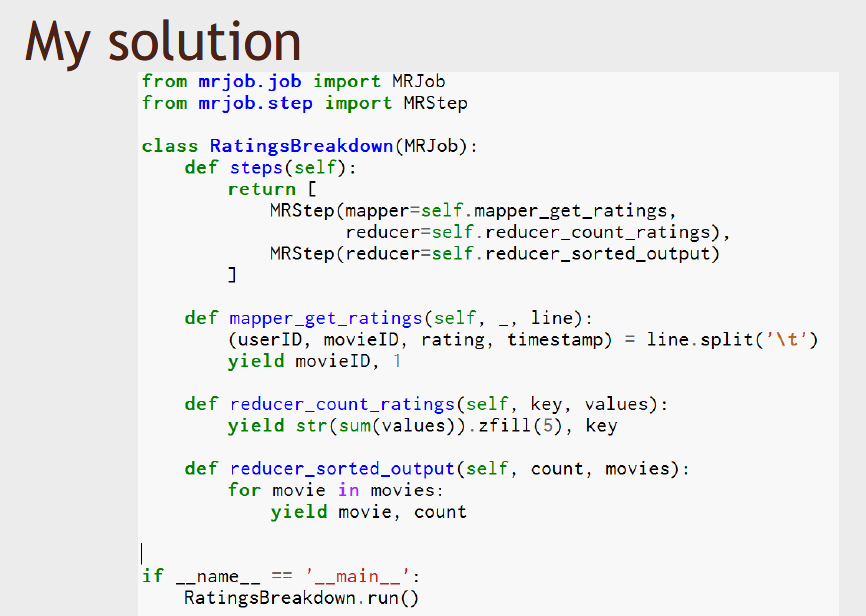
Here's a complete Python MapReduce script.
1578039179773
This is an entire MRJOB script in Python that would use MapReduce
streaming to actually execute across a cluster.
defbacktrack(self, combination, digit, phone, output): iflen(digit)==0: output.append(combination) return for letter in phone[digit[0]]: self.backtrack(combination+letter,digit[1:], phone, output)
defdp(i,j): if (i,j) in memo: return memo[(i,j)] if j==len(p): return i==len(s) first = i < len(s) and p[j] in {s[i],'.'}
iflen(p) >= j+2and p[j+1]=='*': return dp(i,j+2) or (first and dp(i+1,j)) else: return first and dp(i+1,j+1) memo[(i,j)] = ans return ans return dp(0,0)
3
复杂度
时间复杂度:用 T 和 P 分别表示匹配串和模式串的长度。对于 i=0, ... , T
和 j=0, ... , P 每一个 dp(i, j) 只会被计算一次,所以后面每次调用都是
O(1)的时间。因此,总时间复杂度为 O(TP) 。